





O presente capítulo tenta responder, de maneira metodologicamente organizada, a uma pergunta: o que já se produziu até o momento como reflexão ética acerca do uso de Big Data em saúde?
Dessa maneira, ao compreender quais são esses aspectos éticos, o livro pretende apresentar ao leitor as principais questões já abordadas por acadêmicos interessados pela temática. Busca-se assim, apontar para temas que precisam de maior aprofundamento no debate, principalmente em contextos periféricos e desiguais. Não se trata de uma resposta definitiva sobre o que fazer com a tecnologia, até mesmo porque essas tecnologias continuam a se transformar, o que significa que toda decisão ou prescrição é provisória.
O estudo desses aspectos éticos se constitui assim em um passo anterior a qualquer decisão ou abordagem normativa ao tema. Ou seja, mais do que dizer o que fazer, o intuito deste livro é informar essa decisão, ao oferecer um panorama dos principais pontos críticos do uso de Big Data. Tais pontos e sua leitura, no entanto, são irremediavelmente preocupados com os efeitos dessas tecnologias em contextos e corpos periféricos.
Com isso em mente, tratamos adiante dos aspectos éticos identificados quando utilizados os descritores Big Data, Bioética e Ética como parâmetros para buscar os artigos científicos na literatura científica regional e internacional[1] [2].
4.1. Corpo de análise
O primeiro achado significativo é que, durante a busca, só foram encontrados artigos na base científica internacional. Não havia até novembro de 2020, artigos latino-americanos sobre as repercussões éticas do uso de Big Data em saúde. Mesmo levando em conta a produção internacional, a busca resultou em apenas 44 artigos.
O debate sobre a moralidade do uso de Big Data em saúde ainda é muito incipiente. Sinal inequívoco é que o volume de publicação científica sobre a dimensão ética do uso de Big Data em saúde está muito aquém do incremento nas publicações técnicas sobre o tema nos últimos anos. Ao se comparar os artigos obtidos como resultado da busca dos descritores Big Data e Saúde, contrastando os apenas 44 artigos sobre os aspectos morais das novas tecnologias nas mesmas bases até o ano de 2020, foram encontrados 2615 artigos na base PubMed (contra os 55 artigos desta base durante a pesquisa) e sete artigos na base LILACS (contra a ausência de artigos nesta base durante a pesquisa). Em face das significativas implicações éticas sobre o tema, o debate ético certamente precisa se intensificar. Na Figura 1, no entanto, percebe-se que, ainda de forma tímida, há uma tendência crescente da reflexão ética ao longo dos anos, o que indica um aumento de interesse sobre o tema.
Figura 1 – Comparação da tendência entre a produção técnica e a discussão ética sobre o uso de Big Data em saúde.
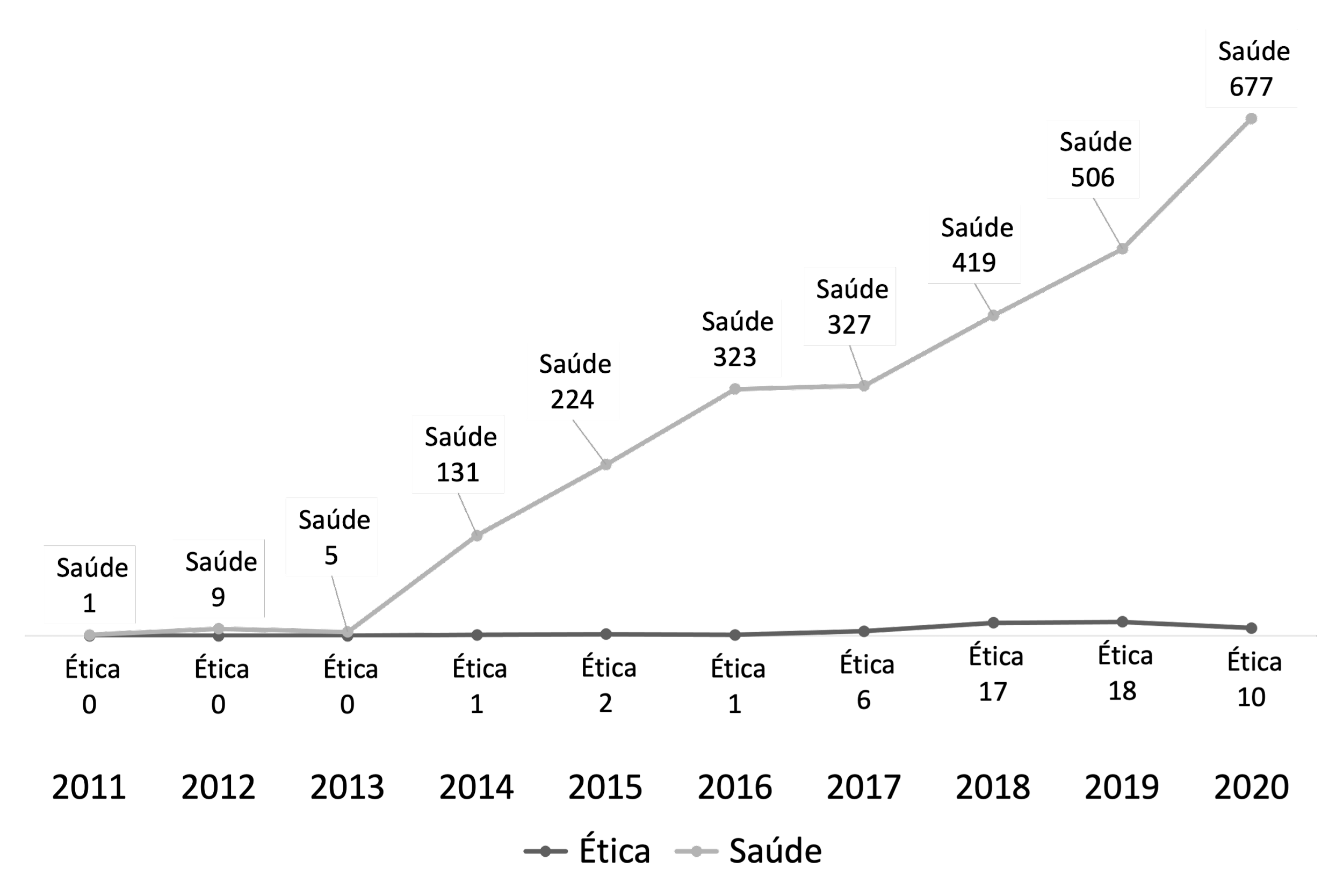
Fonte: Gráfico elaborado pelos autores com dados obtidos a partir da busca dos descritores Big Data e Saúde nas bases científicas PubMed, LILACS e dos artigos analisados neste livro.
A tendência permanece crescente até 2020 quando, em comparação com o ano anterior, ocorreu uma significativa queda no número de publicações. Uma das possíveis explicações para tal fenômeno é alguma demora que sempre precede a indexação dos artigos por parte das bases. No entanto, pode-se conjecturar que tenha sido em parte resultante das consequências inéditas da pandemia de COVID-19 sobre a dinâmica global da pesquisa e publicação científica (Sohrabi et al., 2021).
Em relação à nacionalidade do primeiro autor dos artigos, conforme pode ser visto na Figura 2, observou-se que a produção científica sobre o tema é principalmente anglo-saxônica, e majoritariamente estadunidense, origem de 19 (43,18%) dos 44 artigos selecionados.
Figura 2 – Quantidade de artigos selecionados por país.

Fonte: Gráfico elaborado pelos autores com base nas informações dos artigos analisados durante a pesquisa.
Esse padrão segue, de maneira geral, um fenômeno observado globalmente na editoria e publicação científica, ou seja, a liderança com larga vantagem dos países desenvolvidos no mundo acadêmico. Nesse sentido, merece destaque os Estados Unidos, que possuem 21,36% da publicação científica mundial (Scimago, 2021). Tal dinâmica acaba por privilegiar um enfoque em discussões que refletem preocupações, posicionamentos e desafios éticos centrados nos contextos do norte geopolítico. Isso é ainda mais significativo no caso do Big Data, uma vez que esse é um tipo de tecnologia que demanda altos recursos técnicos e econômicos e seus principais polos desenvolvedores estão sediados no Vale do Silício.
Garrafa (2005) sinaliza, no entanto, para a necessidade de que a bioética na América Latina como um todo produza reflexões locais e se recuse a importar de forma acrítica e sem contexto as preocupações éticas estrangeiras. Uma das características resultantes desse posicionamento foi a politização e ampliação de escopo das bioéticas latino-americanas. Desde os anos 90, a bioética latino-americana já trabalhava a ampliação de sua agenda, tendo papel fundamental na consequente transformação pela qual tem passado a bioética internacional. Esse processo resultou na DUBDH nos moldes que conhecemos hoje (Garrafa, 2012).
No caso da reflexão acerca do uso de Big Data em saúde, ainda há muito trabalho a se fazer nesse sentido. A incipiência é ainda mais significativa em bases regionais. É significativo o fato de que, observando os critérios de busca, não foram encontradas publicações regionais sobre o tema. Evidentemente, o resultado não permite a extrapolação de uma completa inexistência de discussão sobre o tema na América Latina. O que o dado reflete, sem dúvida, é que no contexto latino-americano a incipiência na discussão ética sobre o uso de Big Data em saúde é ainda maior do que em nível internacional.
Conclusão semelhante foi obtida por Harayama (2020) que na busca com descritores Big Data, Bioética e Ética, de maio a julho de 2020 nas bases Scielo, BIREME e Jstor, bem como incluindo na pesquisa sítios da Organização Mundial da Saúde e do Ministério da Saúde do Brasil, encontrou somente 21 artigos (Harayama, 2020). A própria existência desse artigo acima citado, mas que não foi detectado pela busca da Pubmed ou pela própria base regional em nossa pesquisa, é prova de que existe reflexão e que o processo de indexação por bases científicas representa uma adicional de dificuldade que se interpõe a um maior debate regional sobre o tema.
O corpus foi também analisado quanto à área de atuação científica dos seus primeiros autores, conforme a Figura 3 abaixo. Foram identificadas cinco áreas. No entanto percebe-se a prevalência de autores atuantes na saúde e tecnologia, com 26 das 44 publicações. Ainda áreas comumente não associadas à bioética, como administração, se fizeram representar na amostra. Tal fato evidencia o grande valor do uso de dados para a administração de instituições privadas, que buscam formas mais efetivas e lucrativas de atuação com o auxílio de Big Data. Em alguns casos, não foi possível identificar a área do primeiro autor com base nas informações presentes no artigo.
Figura 3 – Quantidade de artigos selecionados por área do primeiro autor.

Fonte: Gráfico elaborado pelos autores com base nas informações dos artigos encontrados na pesquisa.
4.2. Os aspectos éticos
A literatura passou por um processo de análise de conteúdo em que foram identificados e classificados os aspectos éticos já tratados na literatura científica. A Tabela 1 sistematiza uma adaptação dos resultados da pesquisa, mostrando os desafios identificados no conjunto de artigos científicos analisados de forma agregada.
Tabela 1 – Lista de aspectos éticos relacionados ao uso de Big Data encontrados na literatura
Aspectos éticos |
Qualidade, representatividade, validez, apropriação do conhecimento |
Incerteza e imprevisibilidade |
Opacidade |
Tomada de decisão baseada em dados e responsabilidade moral |
Conflito entre interesses individuais e coletivos |
Cooperação |
Percepção pública |
Injustiça e desigualdades |
Preconceito, estigma e injustiça |
O meio ambiente |
Segurança digital e mecanismos de proteção |
Autonomia |
Consentimento |
Privacidade e confidencialidade |
Condição humana |
Modulação comportamental |
Mercantilização da privacidade |
Fonte: Esquematização realizada pelos autores a partir dos aspectos éticos sobre o uso de Big Data em saúde identificados na literatura.
Toca agora abordar de forma mais direta os conflitos morais resultantes do uso de Big Data em saúde. Na maneira como aqui serão abordados, os tópicos não pretendem ser exaustivos, embora reflitam uma classificação do estado atual da presente discussão ética na literatura científica. Eles foram aqui organizados de maneira a orientar a atenção do leitor a grandes eixos que demandam atenção. Dessa maneira, ao analisar os aspectos éticos do uso de Big Data em saúde, foi apontado que é preciso refletir de maneira mais integral sobre Big Data e (1) a produção de conhecimento; (2) a coletividade; (3) meio ambiente; (4) regulação; (5) tecnologias preditivas.
O capítulo se encerra marcando a importância de orientar o debate para que as referências e ferramentas de análise sejam adequadas às maneiras específicas com que o desenvolvimento e aplicação desse novo tipo de tecnologia alteram as dinâmicas sociais no Sul Global.
4.3 É preciso refletir sobre Big Data e… a produção do conhecimento
Qualidade, representatividade, validade, apropriação do conhecimento
Big Data é, sobretudo, um grande evento epistêmico, uma nova forma de se produzir conhecimento. Os propósitos, meios de produção e de validação do saber adquirem características próprias que demandam avaliação, principalmente se orientam decisões quanto à saúde de indivíduos e populações. A discussão acerca da qualidade e representatividade; validade; e apropriação do conhecimento assim produzidos aqui serão tratados em conjunto, de forma a caracterizar de forma mais orgânica o fenômeno Big Data em suas inovadoras disposições epistêmicas e suas consequentes repercussões éticas.
Um aspecto importante a ser levado em consideração se refere à qualidade dos dados utilizados e os próprios algoritmos que realizam as análises. A qualidade e integridade dos dados têm grande influência sobre os resultados. Dados de origens obscuras, coletados de forma desorganizada ou mal estruturada, ou de fontes inverídicas geram resultados não confiáveis. A tendência crescente de uso de Big Data para tomada de decisões ignora que a qualidade na coleta de dados pode variar muito, o que traz evidentes aspectos éticos (Mittelstadt, Floridi, 2016).
Adicionalmente, também constitui um desafio quanto ao uso dos dados a falta de representatividade, que diz respeito à capacidade que a amostra tem de representar o universo que se pretende conhecer. Mesmo quando possuem processos que garantam a qualidade da coleta até a análise, as bases de dados podem apresentar severas limitações quanto a sua representatividade. Vieses de seleção podem excluir grupos vulneráveis, que passam a não figurar em bases de dados por falta de acesso às tecnologias da informação ou aos cuidados de saúde, por exemplo. Dessa maneira, peculiares formas de comportamento, padrões séricos e doenças podem não estar adequadamente representadas em sua distribuição no universo populacional. Caso não haja preocupação com vieses durante todo o processo de coleta e uso dos dados, a falta de representatividade de determinados grupos ou parcelas da população pode, além de comprometer as possíveis inferências e predições baseados nos dados, contribuir para discriminação e/ou falta de atendimento/cuidado para determinados grupos não representados.
A falta de representatividade pode ainda agir como retroalimentação de distorções sociais existentes, contribuindo para a aceleração da lacuna digital que representou o ponto de partida (Mittelstadt, Floridi, 2016). A falta de representatividade, a exclusão e os mecanismos de concentração de poder são intrinsecamente relacionados.
Levando em consideração todos esses aspectos relacionados à qualidade e representatividade dos dados, fica evidente que se não realizadas com todo o rigor necessário, pesquisas clínicas e científicas podem perder sua validade. Se o uso de tecnologias de aprendizado de máquina em pesquisa clínica torna seus percursos metodológicos opacos aos critérios científicos de reprodutibilidade, o conhecimento produzido tem problemas quanto à validação (Manrique de Lara, Peláez-Ballestas, 2020).
A validade se torna um tópico de importância ética, uma vez que decisões são tomadas a partir de um conhecimento assim produzido. O objetivo mesmo de todo o investimento em Big Data é justamente a capacidade de identificar associações estatísticas antes desconhecidas entre fenômenos. Fazê-lo, sem a devida atenção aos critérios de validade, qualidade e representatividade, tem como risco derivar relações causais injustificadas de fenômenos meramente correlacionados, de modo que a qualidade da análise se torne não satisfatória. Em outras palavras, dois fenômenos associados, que podem inclusive ter uma causa comum ainda desconhecida, podem ser imaginados como sendo derivados um do outro. Como muitos dos algoritmos de aprendizagem de máquina podem tornar impossível auditar todo o caminho percorrido para identificar as relações entre fenômenos, é possível que conclusões equivocadas e enviesadas passem a ser tomadas como verdadeiras. Isso poderia ocorrer mesmo que para o público e até mesmo para experts fosse difícil comprovar problemas com a validade do conhecimento produzido (Überall, Werner-Felmayer, 2019).
Ainda, para avaliar e utilizar as tecnologias, sempre em expansão, a apropriação do conhecimento também surge como preocupação. A formação adequada para a interpretação das informações por vezes é rara ou mesmo inexistente e isso deve ser discutido em caráter emergencial (Bassan, Harel, 2018). Nesse sentido, a dimensão educativa desse fenômeno deve ser revelada.
Precisamente, essa temática relativa à produção e apropriação do conhecimento é tratada num Relatório do International Bioethics Committee da Unesco (IBC) intitulado “Relatório do IBC sobre Big Data e Saúde”, e que é resultado de dois anos de discussões de bioeticistas de todo o mundo convocados por essa organização. O documento trata da importância ética dessas novas vias epistêmicas que representam o conhecimento obtido a partir de Big Data. O Comitê destacou que, uma vez que os métodos de Big Data podem constituir poderosos geradores de hipóteses para pesquisa, também esta fase deve observar os mais altos padrões éticos, com a preocupação na proteção de dados e excelência em sua utilização. Já existem, nesse sentido, algumas orientações de melhores práticas na pesquisa com Big Data, que incluem, por exemplo, a criação de comitês com representação de pacientes para a governança de biobancos e sua participação nos processos de acompanhamentos de informações sobre as pesquisas com tais dados (Unesco/IBC, 2017)
Embora, por um lado, aponte possíveis criticidades quanto à qualidade do conhecimento produzido, o relatório alerta que posições regulatórias que diminuam a circulação dos dados podem se apresentar como obstáculo para pesquisa e produção do conhecimento. Apesar de mencionar, por vezes, a importância da propriedade dos dados pessoais e dos direitos provenientes destes, o IBC afirma que esses conceitos tradicionais podem ter se tornado inadequados. É necessário, de acordo com o documento, que se desenvolva uma nova estrutura normativa com novos conceitos, de modo a equilibrar os interesses envolvidos e não atrapalhar a produção do conhecimento (Unesco/IBC, 2017).
Assim, reconhecendo os desafios conceituais e práticos que envolvem as medidas para a necessária proteção dos dados, o IBC aponta para a necessidade de medidas que ao mesmo tempo garantam a segurança, autonomia e privacidade, e viabilizem o compartilhamento de dados para o bem comum (Unesco/IBC, 2017).
Outro aspecto destacado pelo Relatório do IBC sobre a temática é a educação da população, imprescindível para resultantes sociais desejáveis, para o exercício da autonomia na participação da produção do conhecimento e, consequentemente, para que os resultados possam refletir adequadamente o objeto analisado (Unesco/IBC, 2017). Esse capítulo retoma adiante, mais detalhadamente, o tema da autonomia.
A seleção do corpo de textos teve por critério a relação entre Big Data e saúde. Talvez por esse motivo, nossa amostra não tenha detectado uma discussão crescente na literatura, principalmente das ciências da informação, quanto à integridade científica e ao uso de Big Data para a produção de artigos e textos científicos. Os algoritmos e aplicações, que inicialmente eram utilizados no meio acadêmico para funcionalidades mais simples, como detecção de plágio, atualmente, em função do aprendizado de máquinas, já estão sendo usados inclusive para produção de textos. Labbé & Labbé (2013) mostraram como aplicativos que compõem textos a partir de palavras extraídas de artigos científicos têm sido utilizados para a publicação. Cabanac, Labbé, Magazinov (2021) propuseram mais recentemente rastrear expressões linguísticas inadequadas, resultado de traduções e paráfrases malfeitas realizadas com auxílio de inteligência artificial (IA), como indicadores de artigos não originais.
O uso de IA para composição de textos que depois são apresentados como originais a revistas científicas é um aspecto epistêmico importante, com evidentes ramificações éticas, mas que não emergiu nos artigos analisados. O tema tem sido crescentemente debatido nas temáticas de integridade científica, compreendida como um conjunto de valores e condutas responsáveis dos pesquisadores que resguardam a produção do conhecimento, sua reprodutibilidade, condições de colaborações científicas, etc.
Incerteza e imprevisibilidade
Outros aspectos epistêmicos de importante significado ético são a incerteza e a imprevisibilidade intrínsecas à produção de conhecimento a partir do uso de Big Data. Sem dúvida, conjugadas a suas implicações na autonomia, estas emergem como uma das questões éticas mais críticas relacionadas à aplicação de tais tecnologias no campo da saúde.
A escala de conjugação e entrecruzamento de dados de diferentes fontes, tamanhos e aspectos faz com que não possa ser dado a pleno conhecimento os processos de análise (Überall, Werner-Felmayer, 2019). Não se trata apenas de desconhecer aquilo que fazem os algoritmos. Da maneira como transitam atualmente, é virtualmente impossível identificar quais informações são obtidas e de que maneiras estas serão reutilizadas em algum momento futuro (Mittelstadt, Floridi, 2016). Assim, é também imprevisível a gama futura de riscos (e também de benefícios) de uma pesquisa e/ou de uma análise.
De certa maneira, apesar dos riscos não mensuráveis, a incerteza e a imprevisibilidade são intrínsecas e indissociáveis do conhecimento produzido a partir de Big Data. Mais do que isso, elas são mesmo a razão de ser de todo o fenômeno, uma vez que aquilo que se busca é justamente conhecer padrões de comportamento não previsíveis ou identificáveis por outras tecnologias de análises de dados.
O que resta claro é que um tipo de tecnologia que tem a incerteza como motor epistêmico se relaciona impondo severos limites à autonomia dos sujeitos. Uma decisão autônoma sobre o uso de dados pessoais requereria conhecimento e garantias sobre usos, riscos e anonimidade, o que, no presente contexto de ausência de regulações eficazes, é impossível (Cesare et al., 2018).
Opacidade
Intimamente relacionada aos aspectos anteriores, a opacidade figura como uma das questões derivadas de especificidades epistêmicas das tecnologias de Big Data. O termo se refere à indisponibilidade e inacessibilidade do processo de geração de conhecimento por meio de análises de Big Data, o que por sua vez inabilita a verificação da veracidade e adequação de seus resultados. A quantidade massiva de dados e operações envolvidas na análise e uso de algoritmos que contam com aprendizado de máquina são alguns dos fatores que promovem esse efeito de opacidade. Como resultante, as informações, inferências e predições, que crescentemente guiam processos de tomadas de decisões, advém de análises que não são reprodutíveis ou auditáveis.
Apesar de contar com um programa inicial, o aprendizado de máquina, como o próprio nome sugere, utiliza-se de recursos que permitem que o algoritmo faça operações para as quais não foi projetado. Ao contrário, ao identificar padrões e comportamentos, a máquina os “aprende” e passa a aplicá-los em suas análises e operações. Assim, embora originalmente desenvolvidas por humanos, as máquinas evoluem de forma autônoma, o que impossibilita conhecer e avaliar o percurso para a obtenção do conhecimento (Manrique de Lara, Peláez-Ballestas, 2020).
O aprendizado de máquina tem sido aplicado nas mais diversas utilidades e contribui para a realização de tarefas complexas, como a tradução de textos, por exemplo. O avanço dessas funções, no entanto, passa a colocar como próximas do real questões ontológicas e éticas aventadas antes por ficção científica. Recentemente, Blake Lemoine, um desenvolvedor do Google, tornou pública sua percepção de que LaMDa, um projeto de IA que desenvolvia junto à companhia, deve ser considerada uma pessoa. O desenvolvedor argumentou que por meio do diálogo, a IA demonstrou ser senciente e expressou o interesse em não ser desligada, o que, segundo ele, deve ser respeitado. Apesar da impressionante capacidade adquirida de dialogar e mesmo de inventar uma fábula em que a LaMDA é retratada como uma coruja sábia que protege os animais enfrentando um monstro que os perturba (e cabe aqui perguntar se somos nós humanos carnais os monstros da história), a companhia descarta os argumentos. Por meio de comunicados públicos, a Google afirmou que a IA demonstrou apenas a habilidade de dialogar como foi programada por meio de tecnologias de modelagem linguístico-computacional (Tiku, 2022).
Ainda que a senciência em máquinas não seja, ou nunca venha a ser, real, a percepção muito concreta de que se dialoga com uma pessoa tem implicações éticas reais. As inteligências artificiais podem reproduzir vieses, contribuir com a manipulação, indução de discursos de ódio, desinformação e acirramento de conflitos (Tiku, 2022). No campo da saúde, a desinformação e o risco de confundir uma IA com o cuidado oferecido por um profissional de carne e osso em telemedicina, por exemplo, são aspectos a serem refletidos.
Tendo em vista a operação dos algoritmos e o aprendizado de máquina, o risco não é somente de sermos iludidos e passarmos a agir sob a impressão de estarmos interagindo com uma pessoa. Mesmo quando buscamos conscientemente analisar a operação desses algoritmos, o exame frequentemente é muito dificultado pela quantidade de dados ou pela complexidade das operações. Consequentemente, com o uso de Big Data, as tecnologias desempenham suas funções em uma rotina semelhante à obtenção de resultados a partir de uma “caixa opaca”. Na computação, o termo remete a sistemas cujo funcionamento interno se ignora em função da alta complexidade, importando nesse tipo de cenário apenas a entrada e o resultado obtido ao final. Evidentemente, a tomada de decisões baseada nesse tipo de informações que não podem ser auditadas apresenta importante dimensão ética (Canales, Lee, Cannesson, 2020).
Tomada de decisão baseada em dados e responsabilidade moral
Levando em consideração os aspectos anteriormente trabalhados, fica evidente a necessidade de olhar, a partir da bioética, a tomada de decisão em saúde baseada em uma nova forma de obter conhecimento cujos usos e aplicações são fundamentalmente imprevisíveis, e cujos processos de produção são frequentemente opacos à verificação, inclusive para avaliar aspectos como validade, representatividade, etc.
Isto se revela ainda mais urgente se considerado que as tecnologias de Big Data são preditivas e, quando alimentadas por grandes quantidades de dados, podem apresentar alta precisão. É justamente por este motivo que as tecnologias de Big Data são crescentemente utilizadas como auxiliares ou até mesmo soberanas nos processos de tomada de decisão. Do ponto de vista moral, no entanto, a autonomia de algoritmos e inteligências artificiais apresenta um desafio adicional. Como tratar da responsabilidade moral de uma decisão feita por um algoritmo?
Essa pergunta é ainda mais importante quando se trata de padronização de procedimentos em cuidados de saúde porque, mesmo considerando a inédita habilidade de analisar dados, as inteligências artificiais possuem capacidade de contextualização limitada e não compreendem a inexistência dos absolutos morais. Essas limitações e a dificuldade na responsabilização por resultados negativos são alguns dos limitantes na tomada de decisão por máquinas (Ienca, Ignatiadis, 2020).
Além da dificuldade em identificar o responsável por eventuais erros, a auditabilidade do processo da tomada de decisão também é um fator central a se considerar. Esse é um aspecto inclusive importante na reflexão sobre a regulação ética em pesquisa. Isso porque, enquanto as pesquisas realizadas com seres humanos passam por crivos éticos, as conclusões tiradas de pesquisas com dados secundários não passam normalmente por esse tipo de revisão (Wang et al., 2020).
4.4. É preciso refletir sobre Big Data e… a coletividade
Conflito entre interesses individuais e coletivos
Quando se trata dos efeitos coletivos dessas novas tecnologias, a literatura analisada aponta que uma das primeiras dificuldades concerne o balancear entre os benefícios coletivos pelo compartilhamento de dados e os danos e riscos que podem afetar o indivíduo (Bassan, Harel, 2018). Isso é especialmente importante quanto às informações de saúde.
O avanço do conhecimento em Big Data depende de uma disponibilidade massiva de dados. Se por um lado, o uso massivo de dados médicos, por exemplo, pode evidenciar relações e padrões séricos desconhecidos, conduzindo à descoberta de novos tratamentos, com promissores benefícios coletivos, por outro, existe a exposição dos indivíduos a riscos quanto à violação de confidencialidade e privacidade, e à consequente exposição dos mesmos a estigma e preconceitos. Indivíduos em situação de vulnerabilidade se encontram ainda mais expostos e demandam mais proteção.
É frequente que na literatura, assim como no já mencionado Relatório do IBC (Unesco/IBC, 2017), haja uma compreensão de que a proteção à privacidade, tal como conhecemos até o momento, tornou-se algo ultrapassado diante dos potenciais benefícios. Em última instância, chega-se a argumentar que a defesa da privacidade é paradoxal, porque prejudica o interesse do indivíduo em ter sua saúde cuidada (Montgomery, 2017).
O argumento ganha muito fôlego no campo da saúde porque as práticas de saúde são historicamente orientadas pela estatística. Seguindo o argumento de quanto mais dados, maior o sucesso terapêutico (o que nem sempre é verdadeiro), os dados passam a aparecer em diversas argumentações não mais como dados de indivíduos, mas como dados sobre indivíduos. Nessa perspectiva, Montgomery (2017) defende que dados sejam vistos não como propriedade ou garantia individual, mas como bem comum.
Essa interpretação é problemática. Primeiramente, porque em contextos periféricos, por exemplo, é fácil imaginar que a quantidade de dados seja suficiente e o que falte mesmo sejam recursos materiais (Neff, 2013).
Outro aspecto a ser observado é que nem sempre quem fornece dados é aquele que se beneficia dos mesmos. Os maiores beneficiados são as grandes companhias, inclusive seguradoras de saúde e indústrias farmacêuticas, que auferem lucros a partir das informações. Nesse caso, uma vez que o objetivo de uma empresa é ser lucrativa e não gerar bem-estar social, é inapropriado esperar que as companhias sejam movidas pelo interesse em proteger indivíduos. Daí a importância de serem reguladas. Dessa maneira, a tomada de decisões baseada nesses dados pode acabar por refletir outros interesses que não o interesse público. Consequentemente, o enquadramento da discussão na oposição entre interesse individual e coletivo, que apela aos indivíduos para que abram mão de suas privacidades, na verdade atende interesses dos chamados guardiões dos dados. Estes, que curiosamente, obtêm lucros na comercialização dos dados que supostamente custodiam.
Na verdade, a privacidade possui funções sociais importantes que vão desde a formação de laços comunitários ao exercício democrático (Cohen, 2013; Pyrrho, Cambraia, Vasconcelos, 2022), de maneira que esse aparente conflito entre bem individual e coletivo não descreve o balanço de benefícios e malefícios da perda de privacidade. Tais aspectos serão retomados no tópico mercantilização da privacidade, mais adiante.
Cooperação
Ainda sobre a relação entre a coletividade e o uso das novas tecnologias, emerge a questão/dimensão ética da cooperação no acesso a dados. Considerando o valor estratégico informacional, observam-se tendências de monopolização de acesso aos dados tanto por parte de governos quanto entidades privadas. Em determinados casos, inclusive por razões de segurança, por um lado, é bom que bancos de dados de informações pessoais estejam isolados e não compartilhando informações. Todavia, levando em consideração o argumento de que o benefício só se torna coletivo na medida em que há compartilhamento de informações (devidamente consentidas e com as medidas de segurança necessárias aplicadas), a monopolização do acesso é algo maléfico. Nesse sentido, a coletividade seria beneficiada mediante cooperação entre os mais diferentes repositórios, e considera-se que aquilo compartilhado, ou seja, os dados podem/devem ser considerados um bem comum (Lawler, Maughan, 2017).
Evidentemente, a perspectiva de que dados pessoais, especialmente biológicos e genéticos, não pertencem aos indivíduos de quem são oriundos e que não devem ser protegidos pelos repositórios, mas, em vez disso, amplamente compartilhados, representa desafios importantes à privacidade dos indivíduos e expõe grupos populacionais inteiros ao risco do estigma. Tais problemas tornarão a ser tratados de maneira mais específica adiante.
Percepção pública
Outro aspecto de significado ético tratado na literatura é a necessidade de cuidar da percepção pública sobre as tecnologias de Big Data. A preocupação frequentemente expressa é aquela de que danos a essa imagem podem indispor os indivíduos às novas tecnologias, criando resistência à disponibilização de dados pessoais (Goodman, 2020).
Diversos fatores poderiam erodir essa imagem, como o temor público de que os dados pessoais sejam explorados economicamente ou de que seu uso pode expor indivíduos à discriminação ou prejudicar o acesso a bens e direitos (Manrique de Lara, Peláez-Ballestas, 2020). No campo da saúde, a discussão acerca do uso abusivo dos dados por companhias seguradoras de modo a restringir o acesso a cuidados médicos a quem mais precisa dela é recorrente (Manrique de Lara, Peláez-Ballestas, 2020).
De maneira geral, o argumento pode ser resumido como uma preocupação com o público de forma que este não se oponha ao compartilhamento de dados, o que, por sua vez, poderia significar um atraso para a ciência como um todo. A manutenção da confiança do público é importante, porque aspectos diretamente relacionados à qualidade, validade e representatividade do conhecimento obtido a partir de análises de Big Data estão em jogo.
É curioso, no entanto, que a abordagem do aspecto ético da percepção pública se dá de forma a parecer mais interessada em evitar uma não adesão à tecnologia, do que uma participação e debate coletivo sobre ela.
Esse tipo de crítica, que identifica que as abordagens da percepção pública estão mais preocupadas em promover aceitação do que com o genuíno debate, é recorrente a muitos esforços institucionalizados de reflexão ética sobre novas tecnologias. De fato, esse foi o cenário dos primeiros programas de estudos ELSI (do inglês Ethical, Legal and Social Implications Program) relacionados ao projeto Genoma Humano. Como um anexo ao projeto de pesquisa científica, os estudos ELSI foram financiados pelas mesmas fontes e foram concebidos como uma tentativa de evitar o rechaço social observado anteriormente com os organismos geneticamente modificados. Atuaram, assim, mais como relações públicas das novas tecnologias, do que como uma pesquisa por efetivas maneiras de evitar consequências sociais negativas das novas tecnologias. Programas semelhantes dificilmente apresentam independência e efetividade na orientação de políticas, funcionando como nada mais do que um esforço intelectual para promover a aceitação e adesão pública a novas tecnologias e não uma preocupação ética socialmente comprometida (Fisher, 2005).
Chama também a atenção que essa crítica também pode ser estendida aos artigos que tratam da percepção pública das tecnologias de Big Data, uma vez que na literatura analisada, como os exemplos acima ilustram, as tecnologias são representadas como fonte de benefício coletivo, enquanto o risco derivaria dos danos à percepção pública delas. De maneira oposta, as discussões deveriam se concentrar em estimular o debate e a visão crítica de maneira que as tomadas de decisão, nas esferas pública e privada, pudessem ser mais bem informadas.
Injustiça e desigualdades
Um dos mais importantes pontos, se não o mais importante, a se avaliar em uma nova tecnologia do ponto de vista ético é como sua introdução em contextos desiguais afeta a distribuição de benefícios, ou seja, se esta contribui ou não para incrementar injustiças.
No caso específico de Big Data, o desenvolvimento das tecnologias e a prática das análises envolvem muitos custos de aquisição e tratamento de dados, além de investimento em mão de obra altamente especializada e custo operacional alto de computadores capazes de processar todas as análises (Laviolle et al., 2019).
Dessa maneira, o investimento necessário é um fator limitante e pode excluir a vasta maioria dos interessados em pesquisar ou trabalhar com isso. Consequentemente, observa-se um efeito concentrador na mão de algumas grandes corporações ou governos. A chamada lacuna digital, termo que descreve a assimetria das relações entre aqueles que recolhem, analisam e se beneficiam dos aglomerados de dados e aqueles que são vistos como meras fontes dos dados, pode se tornar cada vez mais significativa nesse cenário (Andrejevic, 2014).
De maneira simples, a lacuna digital tem tendência a se retroalimentar pois, em função da elevada demanda por investimento, populações em condição de desvantagem financeira e social passam a ter acesso cada vez mais limitado aos benefícios trazidos por essas tecnologias, o que, por sua vez, faz com que as especificidades dessa população e suas necessidades sejam invisibilizadas nas amostras, gerando um efeito cumulativo de exclusão. É por esse processo que a lacuna digital, ou seja, a desigualdade entre os que fornecem dados e os que podem usufruir das suas vantagens, é tendencialmente crescente (Manrique de Lara, Peláez-Ballestas, 2020).
O Relatório do IBC, nesse sentido, alerta que, apesar de promissoras utilizações para o combate à pobreza, o acesso à tecnologia ainda apresenta muita disparidade, tanto entre estratos sociais diversos, quanto entre países periféricos e centrais. Há uma demanda elevada por infraestrutura e recursos humanos para fazer funcionar as ferramentas e provedores necessários a essas tecnologias. Adicionalmente, existe uma grande disparidade entre habilidades tecnológicas, alfabetização digital e a existência de conteúdo local relevante entre países centrais e periféricos (Unesco/IBC, 2017), o que demanda esforços educacionais e de produção e apropriação do conhecimento como medida mitigadora de injustiças.
Decorrente dessa diferença de contexto, o fluxo de informação se dá dos países periféricos para os centrais e já desenvolvidos tecnologicamente, o que ocorre sem garantias de retornos de benefícios. Em função dessas dinâmicas, a lacuna digital se constitui como um dos maiores desafios para a democratização da informação e de seus benefícios, interferindo nos termos em que se desenvolvem as relações internacionais e na soberania dos países periféricos (Unesco/IBC, 2017).
É significativo que, nesse ponto, o relatório identifique a possibilidade de incremento da injustiça, mas não aponte os mecanismos com os quais as próprias tecnologias podem atuar como fatores adicionais de concentração de poder e renda. Uma das mais importantes dinâmicas concentradoras de capital relacionada ao uso massivo de dados, a mercantilização da privacidade, será abordada mais adiante em um tópico específico.
Preconceito, estigma e injustiça
Em adição às questões relativas ao incremento de disparidades, preconceito e estigma são outros fatores promotores de injustiça que podem resultar da utilização dos dados.
No campo da saúde, a prática de anonimização dos dados é frequentemente apontada como um tratamento de informações sensíveis em saúde para evitar a estigmatização. Essa solução, no entanto, não parece ser suficiente quando se trata de tecnologias de Big Data. Primeiramente, porque os indivíduos podem ser classificados e estigmatizados de acordo com perfis nos quais são caracterizados, independentemente se seus dados de fato tenham sido objeto de tratamento (Mittelstadt, Floridi, 2016). De forma mais grave, há uma crescente tendência de ataques desanonimizadores, possibilitados pela agregação e cruzamento de dados de diversas bases. Por razões estatísticas, quanto maior a agregação de dados mais facilitada é a reidentificação de usuários, que pode ocorrer a partir de dados mais individualizáveis como os de movimentação e geolocalização, mas também a partir de preferências em serviços de streaming ou de engajamento em redes sociais. Os sujeitos não somente podem ser identificados pelas novas técnicas, mas estas consentem inferências sensíveis como posicionamento político, orientação sexual, entre outras, o que pode inclusive representar riscos a depender dos contextos socioculturais dos sujeitos (Li et al., 2020; Ji et al., 2014; Abawajy et al., 2016).
Do ponto de vista dos dados de saúde, uma das preocupações mais frequentemente expressas é a possível disseminação de práticas discriminatórias provenientes de seguradoras, agentes de crédito e no ambiente de trabalho (Manrique de Lara, Peláez-Ballestas, 2020).
O funcionamento dos algoritmos também apresenta potencial discriminatório e incrementador de estigmas, já que eles podem conter vieses recebidos de quem os desenvolveu ou não possuírem as devidas medidas para evitar danos às análises. Por exemplo, vieses algorítmicos ou vieses de seleção na coleta dos dados apresentam grande possibilidade de acarretar danos discriminatórios, reforçando e ampliando injustiças já existentes na sociedade (Goodman, 2020).
Além disso, na hipótese desse tipo de viés, a própria situação de vulnerabilidade pode diminuir a capacidade dos sujeitos de reconhecer os mecanismos técnicos de coleta e de se proteger contra seus efeitos negativos (Mittelstadt, Floridi, 2016).
O risco de estigmatização é crítico quando o tema é saúde e de consequências especialmente cruéis em países em que o acesso a ela não é garantido como um direito universal. Nesses contextos, mesmo a contratação de planos de saúde, pode ser negado ou limitado por seguradoras por motivações econômicas. Concretamente, a preocupação é que condições preexistentes, tendências genéticas e práticas consideradas de risco (que podem ser inferidas por padrões de busca na internet, consumo, ou até mesmo por coletas de dados de familiares) podem ser usadas pelas seguradoras como justificativa para a exclusão dos indivíduos. Tais práticas, destinadas a aumentar a lucratividade das operadoras, podem, na vigência do fenômeno Big Data, ser intensificadas por métodos cada vez mais invasivos de investigação, com uso de informações pessoais vazadas ou até mesmo lançando mão do processo de classificação de indivíduos em perfis de risco. Assim, como o próprio IBC ressalta, a discriminação e o agravamento de injustiça contra grupos já vulnerabilizados é uma preocupação importante e que requer medidas regulatórias e protetivas (Unesco/IBC, 2017).
4.5. É preciso refletir sobre Big Data e… meio ambiente
A preocupação ética com os impactos ambientais não foi tratada na literatura científica analisada. O tópico, levantado exclusivamente pelo IBC, foi trabalhado a partir da perspectiva da sustentabilidade ambiental da nova tecnologia. A ausência desse problema nos artigos sobre as implicações éticas do uso de Big Data em saúde demonstra ainda uma visão compartimentalizada das questões e aponta a necessidade de ampliar a agenda bioética e aprofundar as discussões sobre as indissociáveis relações entre a saúde da população e o ambiente.
Os resultados ambientais negativos podem ser resumidamente atribuídos a dois fatores: consumo de energia, extração de matéria-prima e emissão de poluentes. O elevado poder computacional associado às análises de Big Data demanda alto consumo de energia, o que impacta negativamente o ambiente. Também não são desprezíveis os impactos causados pela prospecção de materiais para a construção e manutenção de parques tecnológicos que precisam ser constantemente renovados.
Os complexos necessários ao processamento massivo de dados estruturas são conhecidos como data centers e consistem em três subsistemas: o sistema de TI (composto por servidores, equipamentos de rede e dispositivos de armazenamento), o sistema de energia e o sistema de resfriamento (Marwah et al., 2010). As estruturas não apenas consomem uma quantidade significativa e progressiva de energia, mas com o crescimento de uma economia orientada por dados, têm acelerado as taxas de emissão de poluentes. Em face a isso, como tentativa de minimização dos impactos ambientais, têm sido desenvolvidas tecnologias de economia de energia em computação de alto desempenho, tecnologias de conservação de energia e busca por fontes renováveis de energia durante a construção e operação das estruturas (Rong et al., 2016).
Infelizmente, enquanto em outros subsistemas existem significativos esforços para ganhos em eficiência energética, o sistema de TI, responsável pelo componente de rede, não tem recebido a mesma atenção, o que, na contramão da tendência, tem levado à elevação do consumo nesse quesito (Bilal, Khan, Zomaya, 2013).
A demanda por energia não é a única preocupação ambiental. O processo de prospecção de matérias-primas, como os metais de terras raras para a produção de condutores e outros componentes essenciais aos equipamentos eletrônicos, tem impactos ecológicos significativos (Madaka et al., 2022).
A ampliação da agenda bioética implica reconhecer as múltiplas relações entre saúde, ambiente e sociedade. Dessa maneira, é preciso ponderar que se impactos ambientais são incrementados por práticas de saúde orientadas por Big Data, isto também provoca adoecimento da população. Tudo isso se dá de forma a afetar desproporcionalmente populações vulneráveis, tanto nos componentes ambientais, quanto nos de saúde, o que incrementa por sua vez as vulnerabilidades.
Mesmo que o uso de recursos e materiais necessários às análises de Big Data possam representar consequências ambientais negativas, o IBC destaca a possibilidade de resultados ecológicos positivos, uma vez que as pesquisas que lançam mão de aglomerados de dados podem ser um recurso para a busca por conhecimento a respeito do uso mais eficiente de recursos naturais (Unesco/IBC, 2017).
4.6. É preciso refletir sobre Big Data e… regulação
Segurança digital e mecanismos de proteção
Talvez a ressalva mais recorrente entre todas aquelas relacionadas ao uso de dados pessoais, dados sensíveis e de uma enorme quantidade de indivíduos seja a necessidade de segurança no armazenamento de todos esses dados (Überall, Werner-Felmayer, 2019).
Não são incomuns as notícias de vazamentos de dados de milhões de indivíduos por corporações dos mais variados segmentos. Somam-se a elas os relatos de indivíduos e até de governos inteiros expostos. Assim, é evidente o tamanho do desafio e responsabilidade para gestores de bancos de dados, especialmente os que possuem informações capazes de gerar discriminação e preconceito em caso de brechas.
Essa segurança, no entanto, não é um procedimento trivial. Conforme já discutido, as rotinas de anonimização não dão conta dos frequentes ataques e das consequências estatísticas e probabilísticas de reidentificação em função do grande número de dados. Os riscos da desanonimização voltarão a ser tratados mais especificamente no tópico a respeito da privacidade e confidencialidade.
As inúmeras possibilidades de análises e resultados, que podem ser obtidas a partir de um mesmo conjunto de dados, além da virtualmente infinita capacidade de agregar e cruzar novas fontes de dados, dificultam significativamente uma regulação específica para o uso de tecnologias de Big Data. Abordagens regulatórias e procedimentos éticos utilizados anteriormente se encontram atualmente desatualizados e despreparados para lidar com as realidades de Big Data (Lajaunie, Ho, 2018), havendo por vezes inconsistências regulatórias entre diferentes níveis de governo (Spector-Bagdady, Jagsi, 2018).
Se a liberdade dos indivíduos está ameaçada quando a coleta se dá por entes públicos, porque nem sempre existe transparência quanto à finalidade, ao atual uso dos dados, e ao possível destino das informações (Margetts, Dorobantu, 2019); em termos globais, no meio privado a situação atual é ainda mais grave. A regulação de atividades econômicas é, em geral, menor do que as governamentais. Assim, entidades que visam o lucro, sujeitas a pouca ou nenhuma ação regulatória externa a depender do país, atuam como agentes autorreguladores (Car et al., 2019).
A ausência de transparência sobre quais dados são coletados, por quanto tempo, para quem são vendidos e quais são seus usos, tornam os mecanismos de proteção virtualmente inócuos e obsoletos. É atualmente um desafio definir limites para este tipo de atividade e igualmente difícil propor maneiras de garantir que sejam cumpridos (Car et al., 2019).
Para exemplificar os presentes desafios regulatórios, basta mencionar que a coleta de dados, inclusive de saúde, em redes sociais é um problema de direito internacional, uma vez que enquanto as corporações agem digital e transnacionalmente, os Estados são limitados por suas jurisdições (Rothstein, 2015).
Quanto aos possíveis mecanismos de proteção, a ideia de propriedade tem forte apelo porque muitos indivíduos, grupos e povos expressam o forte sentimento que seus espécimes biológicos e dados lhes pertencem. Nessa perspectiva, a regulamentação teria como foco a relação entre quem fornece, utiliza e (sendo o caso) lucra com isso, garantindo clareza e limites à exploração econômica. Contudo, ainda que o conceito de propriedade seja claramente aplicável a bens materiais, quando transportado para o meio digital, é mais difícil identificar a quem pertence os dados se considerarmos reivindicações de propriedade intelectual sobre algoritmos de coleta, sobre as bases e suas análises. Garantir que a posse seja respeitada é ainda mais desafiador. Mesmo definindo que a propriedade é de determinada entidade ou indivíduo, ainda não é claro o que isso representa para a coleta e análise de dados (Mittelstadt, Floridi, 2016).
A temática é tratada pelo IBC no tópico “da propriedade à custódia e compartilhamento de benefícios” e reflete algumas das oposições frequentes na literatura, sobre se regulamos a coleta ou o uso de dados ou, em outros termos, se a solução se dá por um reconhecimento da propriedade dos dados aos indivíduos ou se se pretende regulamentar a custódia por companhias. A posição defendida no documento é que o conceito de propriedade dos dados, em termos de controle, envolveria “o direito dos sujeitos dos dados de impedir qualquer tipo de manipulação de dados…”, o que já não seria possível nos dias atuais (Unesco/IBC, 2017, p. 19). O argumento é que o conceito de custódia seria mais adequado, uma vez que envolve “a responsabilidade pela segurança e bem-estar de alguém ou algo e representa valores éticos como cuidado, custódia, proteção e confiança à custódia ou à guarda” (Unesco/IBC, 2017, p. 15).
A posição do IBC reflete uma postura cada vez mais predominante na comunidade científica que enfatiza a importância de compartilhar dados, em virtude da expectativa de que a ampliação do conhecimento trará efeitos benéficos para toda a humanidade. Nessa perspectiva, a propriedade pessoal dos dados não desponta como caminho possível ou desejável para resolver os desafios éticos e legais do uso de Big Data (Unesco/IBC, 2017).
De forma oposta, a resignação sobre a perda de autonomia e privacidade e o enfoque apenas nos benefícios esperados das novas tecnologias precisam ser mais bem refletidos em seus pressupostos. É justamente para pautar essa discussão que algumas dessas assunções serão retomadas para análise mais adiante no tópico comoditização da privacidade.
Autonomia
Como mencionado já em diversas partes desse livro, o tema da autonomia é central nas reflexões acerca do uso massivo de dados aglomerados, tendo estreita correlação com outros problemas éticos decorrentes desse recente fenômeno tecnocientífico. Presente desde o início das discussões éticas sobre Big Data, o primeiro registro da preocupação com autonomia e Big Data, em nossa amostra, data de 2015 (Rothstein, 2015).
Além disso, o tema foi também apontado como problema crítico no Relatório do IBC em 2017. Esse documento, além das questões relacionadas à autonomia e ao consentimento na aplicação das novas tecnologias informacionais de Big Data em saúde (primeiro desafio trabalhado), aborda medidas para a proteção e governança das bases de dados (Unesco/IBC, 2017).
O exercício da autonomia é prática complexa e relacional e o respeito à ação autônoma pressupõe como condições necessárias: a competência para entender e avaliar as informações relevantes; o acesso à informação; possibilidade de escolha entre diferentes opções; a consideração da variação nos valores individuais nas decisões; a voluntariedade das decisões; ausência de coerção; a garantia de que indivíduos sejam capazes de escolher os objetivos e meios para suas ações; e a ação em si tem de ser algo consciente (Jennings, 2009).
A autonomia de um indivíduo relaciona-se à sua capacidade de tomar uma decisão e, tradicionalmente, principalmente no âmbito da pesquisa, o consentimento se apresenta como sua principal forma de expressão e garantia. No entanto, este apresenta especificidades que precisam ser observadas durante a reflexão ética a respeito do uso de Big Data em saúde (Unesco/IBC, 2017).
Os artigos analisados apontam claramente que é possível que indivíduos não consigam mais decidir e atuar de forma a proteger seus próprios interesses no cenário criado pelas tecnologias do Big Data em saúde (Evans, 2017). Para essa restrição da autonomia, como já mencionado anteriormente, contribui especialmente a prática de caracterização por perfis. Isso porque esse tipo de classificação dos indivíduos na verdade tem por finalidade prever características e tendências comportamentais de grupos, o que acaba por afetar a autonomia e privacidade de todos, inclusive de indivíduos que decidam e (com chance ainda mais remota) consigam efetivamente permanecer em “isolamento total” de mecanismos de captura de dados pessoais. O motivo é que, mesmo sem ter seus dados coletados, indivíduos podem ser classificados a partir de características demográficas comuns ou similaridades genéticas com perfis de grupos já identificados (Mittelstadt, Floridi, 2016). Desse modo, nem o isolamento, nem a coleta de dados de forma anonimizada protege indivíduos de sofrerem discriminação num nível individual.
Muitas das abordagens, inclusive o relatório do IBC, acabam por concluir que há limitações já intransponíveis na capacidade de decidir a respeito do uso de dados pessoais, demonstrando, assim, uma resignação diante dessa erosão da autonomia. Nessa perspectiva, a solução mais frequente costuma ser aquela de consentimentos ampliados (que não passam de registros formais onde se assente a consciência da falta de liberdade), associados a uma busca por anonimização dos dados. Ambas as medidas, porém, focam em garantias aos indivíduos, enquanto o uso de Big Data se constitui em um problema de dimensões sociais que requer soluções à altura. Mais do que inócuas (Manrique de Lara, Peláez-Ballestas, 2020), as soluções de cunho individualista geram efeitos negativos, porque acabam por desmobilizar e prejudicar o enfrentamento das questões éticas em suas reais proporções, inevitavelmente, sociais.
Consentimento
Consentir é exercício autônomo, uma expressão de decisão livre e informada. Consequentemente, de maneira correlata ao exposto anteriormente, o uso massivo e entrecruzado de dados de diversas e crescentes fontes, em seu caráter incerto, desafia as atuais acepções sobre o que vem a ser um consentimento informado (Mittelstadt, Floridi, 2016).
A imprevisibilidade, característica da tecnologia, se apresenta como um fator complicador diante daquilo que compreendemos como condições para tomadas de decisão. A possibilidade de cruzamentos e acréscimos futuros nas fontes de dados, juntamente à incerteza quanto aos usos futuros colocam em pauta qual seria a forma adequada de consentimento nesse contexto. Em decorrência de toda essa indeterminação, ainda que incluída como etapa para o uso das tecnologias no presente, a concordância expressa com o compartilhamento futuro de dados pode ser questionada quanto a seu caráter de consentimento verdadeiramente livre e informado (Unesco/IBC, 2017).
Adicionalmente, especialmente quando formalizado por meio de termos de serviços e contratos de usos de aplicativos ou serviços, o consentimento é problemático. Com sua linguagem técnica e pouco transparente, a vinculação da aceitação dos termos ao uso e a extensão do texto proibitiva à leitura, esses instrumentos se constituem na prática em termos de adesão, e acabam por, em vez de garantir, efetuar restrições à real escolha dos usuários (Manrique de Lara, Peláez-Ballestas, 2020).
Além da pouca margem para real discordância, como são obtidos por vias eletrônicas, os meios para consentimento atuais não oferecem maneiras de verificar quem e em que condições se encontra quem consente, se são os usuários titulares que consentem, se esses são maiores e se, no momento em que concordam, estão em plena capacidade cognitiva e legal de fazê-lo (Unesco/IBC, 2017).
Adicionalmente, mesmo quando existente e vindo de sujeitos capazes, muito do consentimento obtido por quem realiza as coletas não é explícito ou compreensível, podendo figurar despercebido no meio de termos de serviços, o que os remove da condição de informados. Consequentemente, a coleta se dá sem que a maior parte das pessoas venha a perceber, usurpando assim a possibilidade de escolha sobre o quê, com quem e com que finalidade estão partilhando (Beier, Schweda, Schicktanz, 2019; Bassan, Harel, 2018).
Diversas abordagens têm sido propostas ao problema, ainda que, ao menos até o momento, nenhuma delas parece ser completa ou definitiva. Um exemplo é o consentimento amplo (broad consent), um instrumento concebido para ser flexível quanto ao seu escopo, no qual o uso dos dados passa a ser descrito de forma mais abrangente, operando em um nível mais alto de abstração. Por exemplo, no lugar de um paciente ceder seus dados e consentimento para diferentes pesquisas de câncer diversas vezes seguidas, por meio do consentimento amplo, ele passaria a consentir apenas uma vez que seus dados possam ser usados em pesquisas cuja finalidade seja o tratamento de câncer (Unesco/IBC, 2017).
Outra proposta de abordagem é o opt-out, ou seja, uma forma negativa de consentimento em que se trabalha com a hipótese de que os dados de saúde podem sempre ser usados para pesquisa a menos que um indivíduo expresse seu desejo de não participação (Unesco/IBC, 2017).
Sem ter mecanismos de regulação e controle para obtenção, entrecruzamento e uso de dados de secundários, as propostas acabam por ser inócuas, porque não garantem que as informações tenham sido obtidas de maneira ética na sua origem.
Privacidade e confidencialidade
O motivo pelo qual a violação da confidencialidade e privacidade é tão significativa do ponto de vista ético, é porque atenta contra a intimidade, a identidade e a autonomia dos indivíduos. A privacidade é um termo que designa o respeito a uma vida particular ou à intimidade que os indivíduos querem manter reservada para si mesmos ou, ao menos, para membros específicos de suas famílias ou relacionamentos.
O conceito está fortemente relacionado à liberdade e suas demonstrações como a liberdade de expressão, de associação, de movimento, de crenças, pensamentos e sentimentos, e de comportamento e intimidade. Já a confidencialidade designa o compromisso de guardar informações compartilhadas, um vínculo de confiança e uma obrigação que um indivíduo ou instituição assume no momento em que é receptor dessa partilha (Francis, 2008).
O tema é crucial ainda porque essas quebras de sigilo implicam em adicionais riscos para a saúde e integridade dos indivíduos, principalmente daqueles vulneráveis e sob risco de estigmatização. Assim, os motivos para respeitar a privacidade de um indivíduo são muitos e os possíveis riscos de que dados pessoais caiam em mãos erradas devem ser sempre reduzidos e mitigados (Dove, Özdemir, 2015).
Talvez o risco mais frequentemente mencionado por diversos autores é o de reidentificação após a coleta de dados. No começo, refletindo práticas anteriores e analógicos de uso de dados sensíveis, era comum que apenas técnicas de anonimização fossem empregadas e que estas fossem o suficiente. O risco de reidentificação, como já dito, porém, é crescente e suas consequências atingem diversamente indivíduos e grupos vulneráveis (Manrique de Lara, Peláez-Ballestas, 2020).
Enquanto as discussões científicas tendem a ressaltar os benefícios coletivos promissores do uso de Big Data, ressaltando a capacidade de auxiliar com novos conhecimentos na solução de problemas em todas as áreas de atuação humanas (Unesco/IBC, 2017; Lawler, Maughan, 2017; Hallowell, Parker, Nellåker, 2019), é muito importante reconhecer e debater o fato de que essas tecnologias significam riscos a diversas dimensões de nossas vidas.
Como já mencionado, um artigo publicado na Revista Nature Communications explicitou a ineficácia das atuais práticas utilizadas para anonimização de dados. Os resultados mostraram que em qualquer conjunto de dados, apenas quinze atributos demográficos são suficientes para reidentificar qualquer pessoa nos EUA, demonstrando que os atuais padrões da prática de anonimização são insuficientes (Rocher, Hendrickx, de Montjoye, 2019).
Os dados são objeto de ataques, mas também de comercialização pelos chamados data brokers, ou revendedores de informação, podendo ser adquiridos e usados para propagandas direcionadas, mas também para rastrear pessoas e seus hábitos pelos mais diversos motivos (Crain, 2018). É fácil imaginar que a divulgação do endereço de uma testemunha protegida, por exemplo, ou mesmo a orientação sexual ou religiosa pode colocar, em certos contextos, a vida de pessoas em risco.
Muitas das técnicas utilizadas ao longo do tempo para a proteção dos dados não se aplicam ao uso de Big Data, já que este frequentemente implica mudança e abertura de propósito, falta de limites para os dados, processamento não transparente, pouca proteção dos dados para ganhar o máximo de conhecimento possível e não transparência para indivíduos envolvidos como características fundamentais (Unesco/IBC, 2017). Mesmo diante de dificuldades, no entanto, é preciso ter em mente a necessidade de proteger os indivíduos. Nesse caso, a resignação em relação aos riscos e dificuldades que privilegia e exalta somente dos benefícios esperados não constituem uma postura ética adequada, mas um tipo de otimismo inconsequente, que coloca a todos em risco.
4.7 É preciso refletir sobre Big Data e… o uso de tecnologias preditivas
As tecnologias de Big Data servem sobretudo para prever e determinar comportamentos. Sendo esse seu principal intuito, importa eticamente, como já mencionado, conhecer a qualidade dos dados para saber a veracidade de suas conclusões. No entanto, de forma talvez mais significativa, importa como as tecnologias são utilizadas para induzir escolhas e condutas na população. Esse aspecto é crucial porque, independente do ponto de partida, os dados e algoritmos produzem efeito de verdade, reforçam cosmovisões, intensificam tendências comportamentais e, em última instância e de maneira dramática, alteram a compreensão que temos de nós mesmos como humanos.
Condição humana
Quando se trata do comportamento humano, atingido e conformado por essas novas tecnologias, um dos desafios relatados por alguns autores é que a discussão presente na literatura científica ainda não tem se atentado suficientemente para como essa transformação digital atua sobre nossa percepção do que é a condição humana (Überall, Werner-Felmayer, 2019).
O uso massivo de dados e de novas tecnologias de análise, juntamente com outras experiências de socialização online, conferem novas maneiras de interagir e existir em uma dimensão digital. Tal experiência, ou ao menos as novas narrativas sobre ela, já informam nossa compreensão da memória, da sociabilidade, do funcionamento da mente. Tais eventos se dão em retroalimentação. São exemplos importantes desse tipo de diálogo contínuo que reestrutura os saberes, a concepção da memória que se produz a partir da interação entre ciências da computação e a neurociência cognitiva (Oliveira, 2007).
Em contraste com essa preocupação de que as novas tecnologias de Big Data já nos transformam como seres humanos e que, mesmo diante da importância desse mutação, ainda faltam discussões, há questionamentos se deveríamos realmente nos basear nessas interpretações, e na capacidade descritiva que têm essas análises, para tratar do comportamento das pessoas. Argumenta-se que os processos decisórios pautados por Big Data podem não ter acesso à variedade e profundidade das dimensões da realidade humana (Peirce et al., 2020). Segundo essa perspectiva, qualquer resultado, por mais completo que seja, é apenas uma parte daquilo que tenta descrever, um recorte que não representa o todo. As extrapolações, assim, podem ter consequências desastrosas (Cesare et al., 2018).
Em resumo, é possível, por um lado, que as transformações estejam ocorrendo de forma rápida demais e irrefletida. Por outro, podemos estar reestruturando nossa maneira de decidir, nos baseando em informações apenas parcialmente verdadeiras.
Modulação comportamental
A modulação de comportamentos se caracteriza como a utilização de dados com o intento de induzir e moldar o comportamento dos indivíduos dos quais se obteve as informações.
Apenas conhecer os padrões e preferências de consumo não basta, é preciso fazer consumir, aumentar o engajamento, prender a atenção, aumentar o tempo de interação. Algoritmos são utilizados assim para reforçar visões de mundo, padrões de relacionamento e comportamento (Dhar, 2017). De forma agravada, comumente, gera-se uma via de informação, ou seja, o processo de vigilância não se limita a coletar a informação disponível, mas cria novas janelas, os chamados cookies de rastreamento, que coletam mais dados, gerando uma retroalimentação contínua do poder de manipulação dos indivíduos.
De maneira mais concreta do que se gostaria crer, o nexo entre a modulação do comportamento e a concentração de poder político e econômico atinge escalas planetárias e ameaça os regimes democráticos (Arga, 2020). Vazamentos recentes mostram como algoritmos e dados massivos contribuíram para o Brexit e para a eleição de líderes de conduta autoritária. Ainda de maneira mais significativa, durante a pandemia vimos a disseminação seletiva de notícias que, circulando em bolhas digitais, reforçaram o negacionismo, a não adesão a medidas profiláticas como o distanciamento social e a vacinação. A discussão sobre Big Data e modulação comportamental no âmbito da bioética é indispensável e demanda urgentemente mais pesquisas, porque a manipulação das informações e do comportamento social constitui novas causas de adoecimento e morte na sociedade digital (Pyrrho, Cambraia, Vasconcelos, 2022).
Mercantilização da privacidade
Talvez a principal novidade do ponto de vista ético em relação ao uso de Big Data, e que de alguma forma faz emergir todos esses pontos anteriormente colocados, é a comercialização de agregados de dados e de tecnologias preditivas, aquilo que é chamado de mercantilização da privacidade (Zuboff, 2019b).
O fenômeno se caracteriza pela crescente comercialização de dados obtidos por entes privados. Nesses casos ocorre um desvio da finalidade, uma quebra na confiança e frequentemente uma violação ao consentimento de quem forneceu o dado sem ter plena consciência de que ele seria usado para outros fins (Mittelstadt, Floridi, 2016; Dove, Özdemir, 2015).
No campo da saúde, isso é especialmente sensível, uma vez que o uso de dados anonimizados obtidos a partir de prontuários e outros registros não é suficiente para evitar esse problema. Os dados de saúde privados e compartilhados em nome de uma relação de confiança com profissionais de saúde passam a ser comercializados. A prática gera valor econômico sem consentimento e corrompe a motivação coletiva das práticas de saúde pública (Manrique de Lara, Peláez-Ballestas, 2020).
A mercantilização da privacidade e a modulação do comportamento, aspectos com profundas implicações para a questão da justiça, não figuram no Relatório do IBC. Dessa maneira, embora o documento expresse continuamente a preocupação com a injustiça, a discriminação, a dificuldade de apropriação do conhecimento em contextos periféricos, a necessidade de compartilhamentos de benefícios, o mecanismo perpetrador de injustiça nessas tecnologias passou ao largo da análise do Relatório.
É possível aventar ao menos duas razões para que o documento produzido pelos experts em bioética não mencionasse tais aspectos. A primeira delas, é que esse posicionamento pode ter sido resultado de uma necessária negociação em contextos multirrepresentativos, como de fato é o Comitê. Outra explicação pode ser a própria temporalidade da discussão. A autora mais reconhecida que pauta o tema da mercantilização da privacidade, Zuboff (2019b), ganha notoriedade com a publicação de seu livro The Age of Surveillance Capitalism: The Fight for a Human Future at the New Frontier of Power em 2019, posterior ao relatório do IBC, portanto.
A discussão iniciada pela autora estadunidense teve uma recepção bastante significativa e representa uma crítica dura à nova face do capitalismo neoliberal caracterizada justamente pelo processo de mercantilização da privacidade. Adiante, a presente discussão tentará delinear alguns eixos a partir dos quais futuras leituras podem aprofundar as maneiras como esse novo contexto pode afetar os modos de vida nos países e contextos periféricos. A compreensão sobre o tema parece bastante significativa, uma vez que as tecnologias de Big Data, em contínua expansão, terão cada vez mais importância no campo da saúde, com implicações bioéticas cada vez mais importantes.
4.8. É preciso refletir de forma socialmente comprometida!
O ponto de vista defendido até aqui é que todos esses conflitos levantados pelo uso massivo de dados pessoais remetem em última instância a uma erosão dos direitos à intimidade e à liberdade. Isso é tema a ser refletido pela bioética, pelos resultantes do fenômeno para a saúde e vida das pessoas. O que se quer destacar, no entanto, é que a defesa do direito à privacidade como fio condutor dessa discussão, não contrasta interesses individuais e coletivos, mas pelo contrário precisa ser pautada pela importância social dessas prerrogativas dos indivíduos. Mais do que isso, as reflexões bioéticas, principalmente aquelas alicerçadas na preocupação com a injustiça dos contextos periféricos onde são produzidas, devem ser pautadas pela busca e desvelamento dos mecanismos concentradores de poder e perpetuadores de discriminação e vulnerabilidades.
Isso porque fica suficientemente claro que existe um risco aumentado de que a periferia do sistema, quer sejam partes periféricas de países centrais ou todo o sul geopolítico, sirva apenas como fazendas de dados (Carr, Llanos, 2021), ou seja, encarada apenas como fonte, local onde o dado é somente coletado como se fosse uma matéria-prima. Neste modelo que mercantiliza os dados, enquanto a commodity é extraída da periferia, a agregação de valor por meio da análise e os benefícios gerados pelo processo se concentram nas regiões centrais. Os efeitos de perpetuação de injustiças são evidentes.
Justamente por essa razão, é necessário defender uma abordagem à privacidade que tenha um forte componente social. É sobre essa dimensão coletiva que está claramente alicerçada a bioética latino-americana, principalmente naquelas vertentes cujo foco de atenção ética e teórica é a vulnerabilidade social, das quais são exemplo a Bioética de Intervenção (Garrafa, Porto, 2003) e a Bioética de Proteção (Schramm, 2008).
Em específico, a bioética desenvolvida no Brasil é profundamente devedora do movimento de redemocratização do país e do papel que a reforma sanitária desenvolveu nesse processo. Na redemocratização, debatia-se a absoluta necessidade de universalização do acesso aos direitos, principalmente, aquele de acesso à saúde como mecanismos promotores de cidadania, decorrentes diretamente do reconhecimento da dignidade das pessoas. Nesse cenário, era claro o papel do Estado em reconhecer e prover a saúde como condição necessária à cidadania, mas também ficava evidente que não era o investimento em novas e avançadas tecnologias terapêuticas que reverteria a então crítica situação de saúde pública. O que se percebeu então foi uma limitação das terapêuticas na diminuição dos índices de morbimortalidade do país (Porto, Garrafa, 2011).
A reforma sanitária afirmava a importância de cuidar da vulnerabilidade para o restabelecimento da saúde. No entanto, não se tratava somente daquela vulnerabilidade biológica agravada pela doença, mas principalmente da vulnerabilidade social e econômica que geram doença. Importavam a condição de vida, o acesso à água limpa, ao esgotamento sanitário, hábitos e moradia. O foco teórico e de investimento tornou-se a prevenção e a atenção básica (Porto, Garrafa, 2011).
Em consequência dessa influência, a bioética produzida no Brasil, é pensada a partir e sobre a saúde pública. A bioética de proteção enfoca sua reflexão para compreender e combater os processos de vulneração (Schramm, 2008), a Bioética de Intervenção afirma seu compromisso com os vulneráveis e dedica sua atenção principalmente às situações persistentes em bioética, resultantes de injustiças e iniquidades em saúde que já não deveriam existir (Garrafa, Porto, 2003).
O que se pretende demonstrar com a discussão do fenômeno de Big Data neste livro é que também a análise bioética acerca das novas tecnologias, as chamadas situações emergentes segundo classificação proposta por Garrafa (1996), também precisa ser socialmente comprometida e territorializada, como nos clamam a fazer Feitosa e Nascimento (2015).
É a compreensão da importância social da privacidade que proporcionou o que se considera ser o principal resultante dessa pesquisa, ou seja, a identificação de uma categoria/conceito que serve de chave interpretativa e permite a compreensão do fenômeno de Big Data. É a partir da leitura bioética da categoria proposta por Zuboff (2019b), a comodificação da privacidade, que se identificam como principais controvérsias éticas aquelas relacionadas à justiça e à acumulação de poder. É somente a partir dessa consciência da dimensão social do fenômeno, que se realiza a defesa da privacidade, mas por suas funções necessárias aos laços coletivos e às liberdades democráticas. É o mesmo olhar que denuncia os efeitos maléficos da mercantilização da privacidade e dos possíveis riscos para corpos e países periféricos, de nos tornarmos todos fazenda de dados, cada vez mais excluídos das condições de beneficiários das novas tecnologias. Trata-se de identificar os propósitos e mecanismos segundo os quais o uso de dados aglomerados opera a perpetuação da injustiça por meio de um processo de expropriação/acumulação de um poder/valor: isso se dá por meio da mercantilização da privacidade e é a análise bioética socialmente enraizada que nos ajuda a desvelá-la.
Privacidade e mercado
Um bom exemplo da mudança de paradigma na coleta e uso de dados pessoais para fins comerciais é o de casas automatizadas. Zuboff (2019b) exemplifica o assunto falando que nos anos 2000 um grupo de pesquisa colaborou para criar uma casa consciente, com sensores e computadores para tal. Eles entendiam que estavam iniciando um campo de conhecimento totalmente novo e, por conta disso, assumiram que os direitos e poder sobre esse conhecimento pertenceriam de forma exclusiva aos moradores. Cerca de duas décadas depois, casas inteligentes já são uma realidade, entretanto, cada peça de hardware que compõe o sistema de uma casa inteligente vem com uma política de privacidade, um contrato de termos de serviço e um contrato de licença para usuário final. Neles, os sujeitos formalmente abdicam das impressões digitais que suas vidas cotidianas geram. Como reforça Zuboff (2019b):
Esses documentos revelam consequências opressivas para a privacidade e a segurança, nas quais informações sensíveis do indivíduo e da casa são compartilhadas com outros dispositivos inteligentes, departamentos não identificados de corporações e terceiros, para propósitos de análise preditiva e vendas a outras partes não especificadas (Zuboff, 2019b, p. 17).
Com isso, fica claro que os direitos têm sido usurpados e reivindicados de forma unilateral, às custas de experiências alheias e do conhecimento que flui destas (Zuboff, 2019b).
A mercantilização da privacidade consiste no mecanismo central da era de vigilância do capitalismo. Este período, nas palavras de Zuboff (2019b), consiste em:
Uma nova ordem econômica que reivindica a experiência humana como matéria-prima gratuita para práticas comerciais dissimuladas de extração, previsão e vendas; Uma lógica econômica parasítica na qual a produção de bens e serviços é subordinada a uma nova arquitetura global de modificação de comportamento; Uma funesta mutação do capitalismo marcada por concentrações de riqueza, conhecimento e poder sem precedentes na história da humanidade; A estrutura que serve de base para a economia de vigilância; Uma ameaça tão significativa para a natureza humana no século XXI quanto foi o capitalismo industrial para o mundo natural nos séculos XIX e XX; A origem de um novo poder instrumentário que reivindica domínio sobre a sociedade e apresenta desafios surpreendentes para a democracia de mercado; Um movimento que visa impor uma nova ordem coletiva baseada em certeza total; uma expropriação de direitos humanos críticos que pode ser mais bem compreendida como um golpe vindo de cima: uma destituição da soberania dos indivíduos (Zuboff, 2019b, p. 7).
Respondendo a uma lógica de mercado sem precedentes, a mercantilização da privacidade se trata da utilização de mecanismos de vigilância para apropriação da privacidade, que passa a ser tratada como matéria-prima, commodity plena e indistintamente transacionável. Os dados são captados nas mais diferentes atividades, agregados e comercializados como aglomerados. Como uma commodity, a privacidade, apesar de ser pessoal, é vendida independentemente do indivíduo que produz os dados. O que interessa é a capacidade de prever e induzir o comportamento, principalmente de consumo, de determinado segmento do mercado (Zuboff, 2019b).
A gravidade do evento e suas possíveis implicações para os Direitos Humanos foi já alertada anteriormente e a singularidade do fenômeno é resumida de forma cristalina por Albuquerque:
A captura da experiência humana que passa a ativo mercadológico é sem precedentes, igualmente, essa espécie de poder que emerge dos meios digitais do capitalismo de vigilância também é único na história (Albuquerque, 2020, p. 41).
Essa nova realidade de mercado afeta de forma ainda mais intensificada países periféricos, nos quais a população, além dos desafios apontados até aqui quanto ao Big Data, acumula injustiças diárias, situações de vulnerabilidade. Essas pessoas têm pouco ou nenhum mecanismo de, primeiramente, compreender o que lhe está sendo retirado e de, finalmente, resistir a isso.
Segundo Zuboff (2019b), “essa lógica transforma a vida comum na renovação diária de um pacto faustiano do século XXI”. Isso porque é quase impossível se livrar da forma que esses sistemas funcionam. Ainda mais quando ficamos dependentes de categorias como monopólio e privacidade no debate do tema, sendo que são termos insuficientes para identificar e debater os pontos mais cruciais e sem precedentes de tal regime.
O acesso democrático aos benefícios oriundos do desenvolvimento tecnológico, já se mostrava algo distante (Garrafa, Costa, Oselka, 1999). Com a inserção do capitalismo de vigilância e sua nova lógica de mercado, o acesso democrático a todos os benefícios de Big Data se torna virtualmente impossível.
Muitos dados são coletados com a justificativa de que contribuirão para o aprimoramento de produtos e serviços. No entanto, o que se obtém é um superávit comportamental do proprietário. Esses dados são agregados e comercializados com a finalidade de alimentar avançados processos de “educação” de inteligência de máquina. Com o desenvolvimento do mercado da predição de comportamentos, as corporações, que se utilizavam de sobras dos dados para adivinhar preferências de consumos, passaram a usar complexos algoritmos para moldar os comportamentos de indivíduos em escala. Nada mais previsível do que comportamentos induzidos (Zuboff, 2019b).
Na existência do capitalismo de vigilância, os dados não são apenas desviados de sua função original. São criadas vias de dados para que a experiência digital se converta em combustível de análises e predições que, por sua vez, são utilizadas para fins lucrativos de quem controla esse sistema. Os usuários que produzem os valiosos dados, recebem em troca serviços gratuitos ou a promessa de uma experiência personalizada de consumo.
A manipulação e vigilância dos comportamentos têm se mostrado um negócio rentável. Quanto menos salvaguardas jurídicas existem, como no caso dos países periféricos, maior é a chance de acumulação de dados e, consequentemente, de enriquecimento de poucos às custas de muitos.
Coletar dados e utilizá-los para criar perfis específicos para anúncios comerciais não é mais suficiente no capitalismo de vigilância, o próximo passo já vem sendo dado, trata-se de influenciar o comportamento de indivíduos de modo a maximizar o ganho econômico, conforme exposto no trecho a seguir:
Pressões de natureza competitiva provocaram a mudança, na qual processos de máquina automatizados não só conhecem nosso comportamento, como também moldam nosso comportamento em escala (Zuboff, 2019b, p. 19).
Apesar da já substancial e expansiva intrusão na privacidade, a vigilância dos indivíduos é cada vez mais normalizada e aceita, e tem se desdobrado em modulação comportamental massiva. A contínua vigilância, necessária para moldar comportamentos, representa um grande risco para a liberdade de expressão, de movimento e reunião. A consequência é uma profunda ameaça que paira ao mesmo tempo sobre as liberdades individuais e os sistemas democráticos.
A percepção pública destes riscos tem aumentado após recentes denúncias sobre o uso deletério de mídias digitais. Por meio de algoritmos, são criados filtros que, lançando mão de vigilância e modulação comportamental, criam bolhas que reforçam as cosmovisões de indivíduos e colaboram com o desenvolvimento de práticas racistas e extremistas, por exemplo (Cohen, 2013).
Com o caso da Cambridge Analytica, compreendemos que esses efeitos são pretendidos para agir em escala global. A empresa, contratada para interferir no processo eleitoral dos Estados Unidos e no Reino Unido, lançava mão de mecanismos digitais de arquitetura de escolha, um termo mais ameno para a modulação comportamental (Bartlett, 2018).
É facilmente imaginável que em outro contexto de poder global, sem a disseminação de falsas notícias e negacionismo pelas mídias digitais, a própria pandemia de COVID-19 poderia ter tido um curso diferente. Essa é uma outra maneira com que a realidade de Big Data e circulação de dados começa a afetar a saúde das populações.
Ainda mais recentemente, com os chamados Facebook Files, tomamos conhecimento de programações destinadas a direcionar conteúdo apologético à anorexia e que tinham adolescentes do gênero feminino como alvo. Com o vazamento de documentos de grandes corporações do mundo digital, foi revelado que as corporações possuíam pleno conhecimento das negativas consequências para a saúde mental dos adolescentes expostos a redes sociais (Horwitz et al., 2021). Esse é um tema de interesse crucial para a bioética, porque essa é uma nova maneira com que grupos inteiros da população, expostos a manipulação inconsciente de seu comportamento, passam a experimentar agravos que em breve constituirão importantes problemas de saúde pública.
A coleta de dados e informações pessoais vem sendo debatida em órgãos reguladores e é algo que divide opiniões. Apesar de a vigilância tradicional, por assim dizer, aquela que envolve a gravação de áudio e vídeo por alguém, ser algo repudiado e constantemente rechaçado judicialmente caso feito sem autorização, a vigilância por parte de grandes corporações é realizada e aceita. Diversas corporações coletam dados muito além dos necessários para o funcionamento de seus aplicativos e, como já apresentado, utilizam-se disso para a criação de vias de dados nas quais é garimpado enorme lucro e poder.
É necessário que a dimensão digital detectada na análise da literatura realizada nesta pesquisa seja de fato percebida em sua extensão. A abordagem regulatória que foca meramente na proteção dos indivíduos, como faz inclusive o Relatório do IBC, não é suficiente para pautar todos esses desafios.
No contexto regional, a regulação brasileira sobre proteção de dados, representada pela LGPD (BRASIL, 2018), apesar de ter esse nome, resguarda o segredo industrial e comercial acima do direito ao acesso aos dados pessoais em seu artigo 9. O normativo prevê tantas isenções para a obrigação de obtenção de consentimento do proprietário dos dados, inclusive para realização de estudos e pesquisas, que nem mesmo essa preponderância dos interesses individuais pode ser afirmada. O estudo dessa legislação não é objeto deste livro, mas é premente que haja maiores pesquisas e debates bioéticos a respeito das plenas consequências da abordagem regulatória regional sobre dados pessoais.
Considerados todos esses aspectos, a dimensão estrutural que a comodificação inspira, caracterizando possível uma nova fase do capitalismo, não pode ser plenamente compreendida por uma oposição entre interesses individuais ou coletivos. Indivíduos e sociedade têm igual interesse em limitar a capacidade de modulação do comportamento por parte de grandes corporações. Esse é um risco para liberdades individuais, mas também para as democracias em função da acumulação de poder e riqueza. É importante realizar, no entanto, que esse risco atinge diversamente as populações. Enquanto centralmente o foco está na medicina personalizada e em possibilidades técnicas de anonimização e proteção de dados, na periferia, a vida cotidiana das pessoas vulneráveis se converte em fazendas de dados.
Privacidade, mercado, autonomia e a modulação comportamental
A privacidade parece inadequada diante da necessidade de fazer da informação um bem comum.
A proteção e defesa da privacidade continuam a ocupar um espaço central no debate bioético em torno de novas tecnologias, como é o caso das práticas data-cêntricas de saúde (Mehta, Pandit, 2018), mas também quanto a temas como a genômica e o uso de informações genéticas (Cech, 2019), e a neurociência (Leefmann, Levallois, Hildt, 2016), por exemplo. De nenhuma forma é consensual, na academia ou na percepção pública, a visão de que a privacidade é algo da qual devemos desistir.
O processo livre de decisão a respeito de como, com quem e o quanto da esfera íntima se deseja compartilhar, proporcionada pela existência da privacidade, nos permite ter relações próximas e significativas e também aquelas mais distantes. A existência da privacidade consente a graduação dos diferentes níveis de relação, das mais íntimas, às mais formais, segundo escolha que somente a preservação da privacidade permite. A privacidade, assim, é fundamental em todos os níveis: para a formação dos indivíduos, para o tecido social e, em última instância, para o pleno exercício democrático, uma vez que a vigilância prejudica a possibilidade de dissenso (Pedersen, 1997; Roessler, Mokrosinska, 2013; Cohen, 2013).
As violações da privacidade afetam, portanto, muito mais do que as vidas dos indivíduos. Sua defesa não é obsoleta, egoísta ou paradoxal.
Mesmo em momentos como a pandemia de COVID-19, o necessário aumento no fluxo de dados, com vistas a diminuir a propagação do vírus, tem um custo alto para a privacidade dos indivíduos e também para a coletividade com consequências futuras ainda imprevisíveis. A Organização Mundial de Saúde alertou que atentados contra direitos humanos e liberdades fundamentais são um risco. Usos discriminatórios e de cerceamento de liberdades e autonomia são algumas das preocupações. O órgão destacou que o mais sério risco, no entanto, é normalizar as medidas de violação da privacidade tomadas por motivação excepcional (WHO, 2020).
Em contraste, é comum perceber nos artigos uma leitura de que também o exercício da autonomia se configura como um direito, ao menos em parte, permanentemente perdido. Isso porque a agregação de dados e a busca por relações e causalidades imprevistas, finalidades do uso de Big Data, impossibilitam uma manutenção total da privacidade e autonomia. O Relatório do IBC (Unesco/IBC, 2017), por exemplo, procura propor meios alternativos de consentimento, conforme já mencionado, como o opt-out ou o consentimento amplo. De forma geral, a manifestação do IBC reflete a compreensão de que tais perdas são irreversíveis, mas que elas gerarão ganhos em conhecimento e o compartilhamento dos benefícios em nível coletivo que justificam a diminuição desses direitos.
A discussão no Relatório, mas também em grande parte da literatura, parece girar em torno de uma contraposição entre os interesses individuais e coletivos. A conclusão costuma ser a de que o uso de Big Data se converte em benefício social. Nessa perspectiva, porém, residem dois problemas: primeiramente, conforme já mencionado, a questão da garantia de direitos como a autonomia e privacidade, mesmo se tratando de prerrogativas individuais, é estruturante para a sociedade; finalmente, não está sempre demonstrado de forma inequívoca que os resultantes finais do uso de Big Data são de fato sempre benéficos para a sociedade. Observados os interesses comerciais gigantescos, a acumulação de riquezas observada nos últimos anos e a concentração de poder em figuras do mundo corporativo que controlam comportamentos sem o devido mandato democrático, esse benefício coletivo é um campo de disputa.
O Relatório é rico em recomendações concretas a respeito de uma regulamentação do uso de forma a evitar efeitos negativos do uso de Big Data. É sugerido à ONU a liderança no processo de governança internacional, a ser seguida por agências nacionais, do uso de dados; a Agência Internacional de Energia e as Agências de Meio Ambiente são chamadas a agir para economizar recursos ambientais raros; a OMS é chamada a controlar as aplicações em saúde e se recomenda a criação de um sistema de vigilância global para controlar o uso de dados em saúde; a Unesco é solicitada a promover uma convenção sobre a proteção sobre a privacidade e a OCDE recebe a recomendação de desenvolver uma estrutura de compartilhamento dos benefícios das aplicações de Big Data (Unesco/IBC, 2017). Contudo, não se menciona uma recomendação que enfrente a modulação dos comportamentos dos usuários, que mitigue o perigo democrático no uso dessas tecnologias e que vigie as práticas de oligopólio e monopólio na mercantilização de privacidade.
Quanto à modulação do comportamento, na literatura, é identificada a aguda capacidade de determinar comportamentos e percepções que se pode adquirir a partir do uso de dados. Essas mudanças que atingem as formas humanas de consumir, se relacionar, se expressar, enfim de estar no mundo, também a maneira de se compreender nele. Isso, como compreendem alguns autores, precisa ser estudado também em sua dimensão ética (Überall, Werner-Felmayer, 2019). Outros autores, como Arga (2020), são mais enfáticos ao alertar que a capacidade preditiva tem sido usada com fins de controle e vigilância, e levam a uma grande concentração de poder em nível global.
Embora haja um tom otimista na literatura e no próprio Relatório do IBC quanto aos efeitos coletivos do fenômeno Big Data, diversos autores expressam a preocupação com um aumento das desigualdades econômicas, com a exclusão de pessoas de baixa renda de oportunidades, e com a perpetuação de preconceitos e estigma, em função de vieses presentes nos algoritmos (Madden et al., 2017). Ao falar de dados sensíveis, como informações sobre saúde, as discriminações resultantes da liberação de dados para companhias de seguro ou empregadores são bastante mencionadas (Manrique de Lara, Peláez-Ballestas, 2020; Gürsoy et al., 2019). Existe ainda o risco de que informações oriundas da prática de categorizar os indivíduos em perfis possam criar estigmas e prejudicar grupos de pacientes e cidadãos, devido a alguma doença, estilo de vida, ou qualquer fator que gere custos extras para as operadoras de saúde (Dorey, Baumann, Biller-Andorno, 2018).
Cada uma dessas possíveis implicações aponta para a possibilidade de que essas tecnologias incrementem injustiças de diversas formas, todas passando pela concentração de poder, e exclusão e exploração de vulneráveis. Isso não significa que as tecnologias não possam ser usadas de forma a trazer benefícios, mas é preciso que cessem os discursos neutrais sobre as tecnociências, e que seus riscos se tornem evidentes, de forma que regulamentações atentas possam ser desenvolvidas de forma a mitigá-los.
É necessário que as regulamentações quanto à coleta, armazenagem, uso e análise dos dados se preocupem principalmente com os riscos incrementados de grupos e sujeitos vulneráveis, para que os avanços científicos e tecnológicos, em geral, e o compartilhamento de dados, especificamente com Big Data, possam ser traduzidos efetivamente em bem comum.
A leitura não neutral das implicações éticas de novas tecnologias nos ajuda na tomada de decisões adequadas a nossos contextos, em níveis individuais e políticos. É preciso refletir as novas maneiras com as quais a injustiça se reproduz, e elas são profundamente relacionadas à opacidade das informações.
Ao detectar que ainda não produzimos em nossa região suficientes reflexões sobre Big Data, nos pareceu importante oferecer nossa modesta colaboração para transformar esse quadro. Por isso, trazemos ao público, em forma de livro, uma análise bioética latino-americana comprometida com a justiça social, para ser lida também por latino-americanas e latino-americanos.
Que a informação científica produza saúde e que seja um instrumento de emancipação e não de exploração. É para esse projeto que queremos contribuir.
Referências
Abawajy, J. H., Ninggal, M. I. H., Herawan, T. “Privacy Preserving Social Network Data Publication”. IEEE Communications Surveys & Tutorials, 18(3): 1974-1997, 2016.
Albuquerque, A. “A privacidade na era dos algoritmos sob a ótica dos direitos humanos”. In: Neto, A. B. S., Almeida, G. H. C. B. (org.). Norma, linguagem e teoria do direito: reflexões para a compreensão do direito do século XXI. Goiânia: Editora Espaço Acadêmico, 2020. p. 36-57.
Andrejevic, M. B. “The Big Data divide”. International Journal of Communication, 8(1): 1673-1689, 2014.
Arga, K. Y. “COVID-19 and the futures of machine learning”. OMICS: a journal of integrative biology, 24(9):512-514, 2020.
Bartlett, J. The people vs tech: how the internet is killing democracy (and how we save it). Londres: Random House. 2018.
Bassan, S., Harel, O. “The ethics in synthetics: statistics in the service of ethics and law in health related research in Big Data from multiple sources”. Journal of Law and Health, 31(1):87-117, 2018.
Beier, K., Schweda, M., Schicktanz, S. “Taking patient involvement seriously: a critical ethical analysis of participatory approaches in data-intensive medical research”. BMC Medical Informatics and Decision Making, 19:90, 2019.
Bilal, K., Khan, S. U., Zomaya, A. Y. Green data center networks: challenges and opportunities. In: 2013 11th International Conference on Frontiers of Information Technology. IEEE, pp. 229-234, 2013.
BRASIL. Lei n. 13709, de 14 de agosto de 2018. Dispõe sobre a proteção de dados pessoais. Diário Oficial da União, Brasília (2018 ago. 15). Disponível em: https://bit.ly/40KpGTP (Acessado em 20 de setembro de 2022).
Cabanac, G., Labbé, C., Magazinov, A. “Tortured phrases: A dubious writing style emerging in science. Evidence of critical issues affecting established journals”. Arxiv, 2021.
Canales, C., Lee, C., Cannesson, M. “Science without conscience is but the ruin of the soul: the ethics of Big Data and artificial intelligence in perioperative medicine”. Anesthesia and Analgesia, 130(5):1234-1243, 2020.
Car, J., Sheikh, A., Wicks, P., Williams, M. S. “Beyond the hype of Big Data and artificial intelligence: building foundations for knowledge and wisdom”. BMC Medicine, 17: 143, 2019.
Carr, M., Llanos, J. T. “Data: Global governance Challenges”. In: Weiss, T. G., Wilkinson, R. (ed.). Global Governance Futures. Londres: Routledge, 2021. digital file (sp).
Cech, M. “Genetic privacy in the ‘Big Biology’ era: the ‘autonomous’ human subject”. Hastings Law Journal, 70(3):851-886, 2019.
Cesare, N., Lee, H., McCormick, T., Spiro, E., Zagheni, E. “Promises and pitfalls of using digital traces for demographic research”. Demography 55(5):1979-1999, 2018.
Cohen, J. E. “What privacy is for”. Harvard Law Review, 126(7):1904-1933, 2013.
Crain, M. “The limits of transparency: Data brokers and commodification”. New media & society, 20(1): 88-104, 2018.
Dhar, V. “Should we regulate digital platforms?” Big Data, 5(4):277-278, 2017.
Dorey, C. M., Baumann, H., Biller-Andorno, N. “Patient data and patient rights: Swiss healthcare stakeholders’ ethical awareness regarding large patient data sets – a qualitative study”. BMC Medical Ethics, 19: 20, 2018.
Dove, E. S., Özdemir, V. “What role for law, human rights, and bioethics in an age of Big Data, consortia science, and consortia ethics? The importance of trustworthiness”. Laws, 4(3):515-540, 2015.
Evans, B. J. “Power to the people: data citizens in the age of precision medicine”. Vanderbilt Journal of Entertainment and Technology Law, 19(2):243-265, 2017.
Feitosa, S. F., Nascimento, W. F. “A bioética de intervenção no contexto do pensamento latino-americano contemporâneo”. Revista Bioética, 23(2): 277-284, 2015.
Fisher, E. “Lessons learned from the Ethical, Legal and Social Implications program (ELSI): Planning societal implications research for the National Nanotechnology Program”. Technology in Society, 27(3): 321-328, 2005.
Francis, L. P. “Privacy and confidentiality: the importance of context”. The Monist, 91(1):52-67, 2008.
Garrafa, V., Costa, S. I. F., Oselka, G. “A bioética no século XXI”. Revista Bioética, 7(2): 207-212, 1999.
Garrafa, V., Porto, D. “Intervention bioethics: a proposal for peripheral countries in a context of power and injustice”. Bioethics, 17(5-6):399-416, 2003.
Garrafa, V. “Ampliação e politização do conceito internacional de bioética”. Revista Bioética, 20(1):9-20, 2012.
Garrafa, V. “Bioética das Situações Persistentes e das Situações Emergentes”. Fragmentos de Cultura, 6(21): 51-52, 1996.
Garrafa, V. “Da bioética de princípios a uma bioética interventiva”. Revista Bioética 13(1):125-134, 2005.
Goodman, K. W. “Ethics in health informatics”. Yearbook of Medical Informatics, 29(1):26-31, 2020.
Gürsoy, G., Harmanci, A., Tang, H., Ayday, E., Brenner, S. E. “When Biology Gets Personal: Hidden Challenges of Privacy and Ethics in Biological Big Data”. Pacific Symposium on Biocomputing, p. 386-390, 2019.
Hallowell, N., Parker, M., Nellåker, C. “Big Data phenotyping in rare diseases: some ethical issues”. Genetics in Medicine, 21(2):272-274, 2019.
Harayama, R. M. “Reflexões sobre o uso do Big Data em modelos preditivos de vigilância epidemiológica no Brasil”. Cadernos Ibero-Americanos de Direito Sanitário, 9(3):153-165, 2020.
Horwitz, J., Wells, G., Seetharaman, D., et al. “Facebook files series”. Wall Street Journal, Nova York, 2021. Disponível em: https://bit.ly/42byGlM (Acessado em 15 de dezembro de 2021).
Ienca, M., Ignatiadis, K. “Artificial intelligence in clinical neuroscience: methodological and ethical challenges”. AJOB Neuroscience, 11(2):77-87, 2020.
Jennings, B. “Autonomy”. In: Steinbock, B (ed.). The Oxford Handbook of Bioethics. Oxford: Oxford Academic, 2009. p. 72-89.
Ji, S., Li, W., Srivatsa, M., He, J. S., Beyah, R. Structure based data de-anonymization of social networks and mobility traces. In: Chow, S. S. M., Camenisch, J., Hui, L. C. K., Yiu, S. M. (eds). International Conference on Information Security, 8783: 237-254, 2014.
Labbé, C., Labbé, D. “Duplicate and fake publications in the scientific literature: how many SCIgen papers in computer science?” Scientometrics, 94(1):379-396, 2013.
Lajaunie, C., Ho, C. W. L. “Pathogens collections, biobanks and related-data in a one health legal and ethical perspective”. Parasitology, 145(5):688-696, 2018.
Laviolle, B., Denèfle, P., Gueyffier, F., Bégué, É., Bilbault, P., Espérou, H., et al. “The contribution of genomics in the medicine of tomorrow, clinical applications, and issues”. Therapie, 74(1):9-15, 2019.
Lawler, M., Maughan, T. “From Rosalind Franklin to Barack Obama: data sharing challenges and solutions in genomics and personalised medicine”. The New Bioethics, 23(1):64-73, 2017.
Leefmann, J., Levallois, C., Hildt, E. “Neuroethics 1995–2012: A bibliometric analysis of the guiding themes of an emerging research field”. Frontiers in human neuroscience, 10: 336, 2016.
Li, H., Chen, Q., Zhu, H., Ma, D., Wen, H., Shen, X. S. “Privacy leakage via de-anonymization and aggregation in heterogeneous social networks”. IEEE Transactions on Dependable and Secure Computing, 17(2): 350-362, 2020.
Madaka, H., Babbitt, C. W., Ryen, E. G. “Opportunities for reducing the supply chain water footprint of metals used in consumer electronics”. Resources, Conservation and Recycling, 176: 105926, 2022.
Madden, M., Gilman, M., Levy, K., Marwick, A. “Privacy, poverty, and Big Data: a matrix of vulnerabilities for poor americans”. Washington University Law Review, 95(1):53-125, 2017.
Manrique de Lara, A., Peláez-Ballestas, I. “Big Data and data processing in rheumatology: bioethical perspectives”. Clinical Rheumatology, 39(4):1007-1014, 2020.
Margetts, H., Dorobantu, C. “Rethink government with AI”. Nature, 568: 163-165, 2019.
Marwah, M., et al. “Quantifying the sustainability impact of data center availability”. ACM SIGMETRICS Performance Evaluation Review, 37(4): 64-68, 2010.
Mehta, N., Pandit, A. “Concurrence of Big Data analytics and healthcare: A systematic review”. International journal of medical informatics, 114(1): 57-65, 2018.
Mittelstadt, B. D., Floridi, L. “The ethics of Big Data: current and foreseeable issues in biomedical contexts”. Science and Engineering Ethics, 22(2): 303-341, 2016.
Montgomery, J. “Data sharing and the idea of ownership”. The New Bioethics, 23(1):81-86, 2017.
Neff, G. “Why Big Data won’t cure us”. Big Data, 1(3):117-123, 2013.
Oliveira, A. “Uma breve história da pesquisa da memória”. In: ___. Memória, cognição e comportamento. São Paulo: Casa do Psicólogo. 2007, p. 17-36.
Organização das Nações Unidas para a Educação, a Ciência e a Cultura – UNESCO/ International Bioethics Committee – IBC. Report of the IBC on Big Data and health. Paris: United Nations Educational, Cultural and Scientific Organization, 2017. Disponível em: https://bit.ly/3oShRhu (Acessado em 15 de dezembro de 2021).
Pedersen, D. M. “Psychological functions of privacy”. Journal of Environmental Psychology, 17(2):147-156, 1997.
Peirce, A. G., Elie, S., George, A., Gold, M., O’Hara, K., Rose-Facey, W. “Knowledge development, technology, and questions of nursing ethics”. Nursing Ethics, 27(1):77-87, 2020.
Porto, D., Garrafa, V. “A influência da Reforma Sanitária na construção das bioéticas brasileiras”. Ciência & Saúde Coletiva, 16(1):719-729, 2011.
Pyrrho, M., Cambraia, L., Vasconcelos, V. F. “Privacy and Health Practices in the Digital Age”. The American Journal of Bioethics, 22(7): 50-59, 2022.
Rocher, L., Hendrickx, J. M., de Montjoye, Y. A. “Estimating the success of re-identifications in incomplete datasets using generative models”. Nature Communications, 10: e3069, 2019.
Roessler, B., Mokrosinska, D. “Privacy and social interaction”. Philosophy & Social Criticism, 39(8):771-791, 2013.
Rong, H., Zhang, H., Xiao, S., Li, C., Hu, X. “Optimizing energy consumption for data centers”. Renewable and Sustainable Energy Reviews, 58: 674-691, 2016.
Rothstein, M. A. “Ethical issues in Big Data health research: currents in contemporary bioethics”. Journal of Law, Medicine & Ethics, 43(2):425-429, 2015.
Schramm, F. R. “Bioética da Proteção: ferramenta válida para enfrentar problemas morais na era da globalização”. Revista Bioética, 16(1): 11-23, 2008.
Scimago Journal and Country Rank (SJR). International Science Ranking: all subject categories. 1996-2020. Disponível em: https://bit.ly/3oYp4wn (Acessado em 01 de Dezembro de 2021).
Sohrabi, C., Mathew, G., Franchi, T., Kerwan, A., Griffin, M., Del Mundo, J. S. C., et al. “Impact of the coronavirus (COVID-19) pandemic on scientific research and implications for clinical academic training – a review”. International Journal of Surgery, 86(1):57-63, 2021.
Spector-Bagdady, K., Jagsi, R. “Big Data, ethics, and regulations: Implications for consent in the learning health system”. Medical Physics, 45(10):e845-847, 2018.
Tiku, N. “The Google engineer who thinks the company’s AI has come to life”. Washington Post, 11 jun. 2022. Disponível em: https://bit.ly/3LFMmQy (Acessado em 11 de junho de 2022).
Überall, M., Werner-Felmayer, G. “Integrative biology and big-data-centrism: mapping out a bioscience ethics perspective with a S.W.O.T. Matrix”. OMICS: A Journal of Integrative Biology, 23(8):371-379, 2019.
Wang, S., Bonomi, L., Dai, W., Chen, F., Cheung, C., Bloss, C. S., et al. “Big data privacy in biomedical research”. IEEE Transactions on Big Data, 6(2):296-308, 2020.
World Health Organization (WHO). Joint statement on data protection and privacy in the COVID-19 response. 19 nov 2020. Disponível em: https://bit.ly/3LFmzIh (Acessado em 12 de setembro de 2022).
Zuboff, S. A era do capitalismo de vigilância: a luta por um futuro humano na fronteira do poder. Rio de Janeiro: Intrínseca, 2019b.
- No nível regional, a pesquisa foi realizada na base virtual “Literatura Latino-Americana e do Caribe em Ciências da Saúde” (LILACS), no endereço https://bit.ly/40UCNSi e internacionalmente, a pesquisa foi realizada na prestigiosa base Pubmed, no endereço https://bit.ly/4261o7K.↵
- Os artigos incluídos no corpo de análise foram aqueles apontados como resultado pelos critérios de busca até novembro de 2020.↵

