





El presente estudio adoptó un diseño metodológico observacional, de cohorte, mixto y epidemiológico, utilizando una muestra no probabilística aleatoria. La muestra estuvo conformada por 2.000 habitantes de la Ciudad Autónoma de Buenos Aires (CABA) y del primer cordón del Gran Buenos Aires (GBA), con edades de entre 18 y 75 años, garantizando una representación equitativa del 50 % por sexo en los grupos de casos y controles. Las unidades de análisis incluyeron a 333 sujetos con diagnóstico confirmado de cáncer mediante histología, que formaron el grupo “CASO”, y a 1.276 sujetos seleccionados aleatoriamente de CABA y el primer cordón del GBA, que conformaron el grupo “CONTROL”.[1]
Asimismo, como criterios de inclusión, se estableció que los participantes fueran habitantes de CABA y del primer anillo del GBA, con edades entre 18 y 75 años, que aceptaron responder la encuesta y firmaron el consentimiento informado. También se incluyeron aquellos habitantes dentro del mismo rango etario que tuvieran un diagnóstico positivo de cáncer por histología (“caso”), así como a personas sanas en apariencia al momento de la toma de la encuesta (“control”).
En cambio, fueron excluidos los habitantes de CABA y del primer anillo del GBA, con edades de entre 18 y 75 años, que no hayan firmado el consentimiento informado, así como aquellos que no aceptaron responder la encuesta; y, por último, se prescindió de las personas que fueran personal de salud con título intermedio (técnico), superior o universitario.
Este trabajo se realizó en la Ciudad Autónoma de Buenos Aires y el primer cordón que la rodea. El primer cordón abarca los partidos de Avellaneda, Lanús, Lomas de Zamora, La Matanza (en parte), Morón, Tres de Febrero, San Martín, Vicente López y San Isidro.
Figura 6
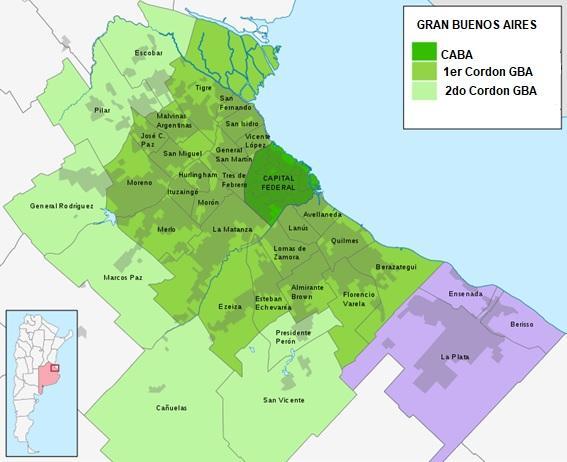
Fuente: Adaptado del INDEC. Última actualización: 31/1/2023.
Se utilizó como instrumento de recolección de datos una encuesta anónima, mixta y de opciones múltiples, a partir de la cual se obtuvieron 2.600 respuestas. Para acceder a la población definida como grupo “caso”, se solicitó autorización a los comités de ética de los hospitales participantes, incluyendo el Hospital de Clínicas, el Hospital María Curie, el Centro Médico Austral, el Hospital Narciso López de Lanús y el Hospital Luisa C. de Gandulfo de Lomas de Zamora. Los casos correspondieron a pacientes tratados en estos hospitales durante el período del estudio, que abarcó los años 2016 a 2018.
La población del grupo “control” estuvo compuesta por personas de las mismas comunidades donde se originaron los casos, pertenecientes al mismo ámbito geográfico y temporal del estudio. Los controles fueron seleccionados sin considerar sus hábitos o antecedentes, con el objetivo de minimizar posibles sesgos muestrales.
3.1. Análisis de los resultados[2]
En el presente trabajo de investigación, los resultados se obtuvieron mediante el análisis de un conjunto de datos procesados utilizando técnicas de aprendizaje automático (machine learning) dentro del campo de la inteligencia artificial.[3]
Se aplicó una encuesta y se realizó la codificación de los tipos de cáncer y enfermedades utilizando la Clasificación Internacional de Enfermedades (CIE-10) (véase Tabla AI2 en Anexo I). También se registraron antecedentes familiares y el uso de medicamentos (véase Listado N.° 1 en Anexo I). Una vez creada y completada la base de datos, se procedió a su depuración aplicando los criterios de inclusión y exclusión previamente definidos. Se eliminaron los registros con anomalías o datos incompletos. En el caso de un registro sin información de edad, pero con diagnóstico confirmado de cáncer, se asignó la edad promedio del conjunto de datos, que fue de 40 años.
- Cánceres (variables target u objetivo: casos)
C-18: colon, C-34: pulmón, C-44: piel, C-50: mama, C-55: cuello de útero, C-61: próstata, C-91: linfoma, C-95: leucemia.
- Cánceres en general (todos de los que se obtuvieron casos en la muestra)
C-06 : boca y lengua, C-18: colon, C-55: cuello de útero, C-63: epididimal (testículo), C-16: estómago, C-22: hígado, C-39: laringe, C-91: linfoma, C-95: leucemia, C-81: linfoma no Hodgkin, C-76: liposarcoma, C-50: mama, C-38: mediastino, C-43: melanoma, C-45: mesotelioma, C-41: osteosarcoma (columna vertebral), C-56: ovario, C-25: páncreas, C-44: piel, C-61: próstata, C-34: pulmón, C-20: recto, C-68: riñón, C-46: sarcoma de Kaposi; C-62: testículo, C-55: útero, C-67 vejiga, y C-23: vesícula.
Tabla 1. Cantidad de cánceres por diagnóstico
| Suma diag. C06=4 | Suma diag. C16=7 | Suma diag. C18=43 | Suma diag. C20=2 |
| Suma diag. C22=2 | Suma diag. C23=1 | Suma diag. C25=4 | Suma diag. C34=21 |
| Suma diag. C38=6 | Suma diag. C39=2 | Suma diag. C41=1 | Suma diag. C43=4 |
| Suma diag. C44=19 | Suma diag. C45=2 | Suma diag. C46=2 | Suma diag. C50=101 |
| Suma diag. C55=30 | Suma diag. C56=3 | Suma diag. C57=1 | Suma diag. C61=41 |
| Suma diag. C62=3 | Suma diag. C63=1 | Suma diag. C71=1 | Suma diag. C76=1 |
| Suma diag. C81=1 | Suma diag. C91=10 | Suma diag. C95=14 |
Fuente: elaboración propia: output pc.
- Cantidad de sujetos por cada análisis
Tabla 2. Cantidad de sujetos dentro del grupo “casos” (suma diag. cáncer) y grupo “control” (suma diag. no cáncer) para el primer análisis de resultados
Suma diag. no cáncer = 1276 | Suma diag. cáncer = 329 |
Fuente: elaboración propia: output pc.
3.1.1. Primer análisis de los resultados
Se identificaron las variables del trabajo y se obtuvo un total de noventa y una. Se aplicó un programa desarrollado en Python que utiliza conceptos de la teoría de la información de Shannon, a partir del cual se realizó una selección de variables objetivo.
Con el apoyo de la herramienta Azure Machine Learning©, se generó un ranking de las variables independientes que mostraron una mayor correlación, tanto positiva como negativa, con la variable dependiente cáncer (también denominada “objetivo” o “target”).
Para el análisis, se consideraron los 329 diagnósticos de cáncer registrados, de los cuales se seleccionaron ocho grupos con un número significativo de casos (véase Listado 1 de variables en el Anexo II) y un total de 1276 controles.
3.1.2. Segundo análisis de los resultados
El siguiente análisis se realizó para identificar posibles variables omitidas en el primer análisis, repitiendo el proceso previo de reconocimiento de variables, con un total de 849. De este modo, se pudo constatar que el conjunto de variables predictoras aumentó de 88 a 849 (véase Listado 2 de variables en el Anexo II).
Tabla 3. Cantidad de sujetos dentro del grupo “casos” (suma diag. cáncer) y grupo “control” (suma diag. no cáncer) para el segundo análisis de resultados
Suma diag. no cáncer = 1609 | Suma diag. cáncer = 340 |
Fuente: elaboración propia: output pc.
- La denominación “caso” y “control” solo es para identificar la diferencia en la muestra obtenida, no hace referencia a la denominación metodológica de los estudios analíticos (casos y controles).↵
- Véase Anexo I para la codificación de las variables.↵
- Aclaración: la base de datos digital fundada en la encuesta estuvo a cargo del Ing. Claudio Milio, quien luego trabajó con el conjunto de datos junto con el Lic. Jorge Kamlosfky.↵

