





La inteligencia artificial (IA) fue definida en 1956 por John McCarthy, Marvin Minsky y Claude Shannon como “la ciencia e ingenio de hacer máquinas inteligentes, especialmente, programas de cálculo inteligentes”. En 1997, la IA fue presentada con Deep Blue, una computadora de IBM que fue capaz de ganarle en una partida de ajedrez al entonces campeón mundial Gari Kaspárov. Este hito marcó un antes y un después en el desarrollo de esta tecnología.[1]
El aprendizaje automático es un campo de la inteligencia artificial que puede, mediante una gran base de datos y algoritmos, aprender e identificar patrones de comportamiento para predecir posibilidades de ocurrencia casi sin intervención del humano. Puede realizar tareas sobre seguridad informática, traducción, reconocimiento del habla, tendencias y recomendaciones acerca de un producto o servicio.
El aprendizaje supervisado es una subcategoría del machine learning. Utiliza una serie de datos etiquetados para enseñar a los modelos a producir el resultado deseado. Estos datos contienen información sobre resultados correctos para que el modelo pueda aprender de la mejor manera.
El aprendizaje no supervisado utiliza datos sin etiquetar. A partir de esos datos, descubre patrones que pueden ayudar a resolver algún tipo de problema (111).
Los modelos se clasifican en a) aprendizaje supervisado, b) aprendizaje no supervisado, c) aprendizaje semisupervisado y d) aprendizaje reforzado. Es decir, estos algoritmos reciben y analizan los datos de entrada y predicen los valores de salida. En la medida que se introducen más datos en los algoritmos, en un principio las predicciones pueden ser más precisas, lo que da lugar al desarrollo de “inteligencia”.
Los modelos mencionados se definen como:
- Aprendizaje supervisado. Se da cuando el operador entrena al algoritmo y carga los datos de las entradas y salidas esperadas. Como el operador conoce las respuestas, corrige las predicciones realizadas por el algoritmo y es por ello que se alcanza una mayor precisión predictiva.
- Aprendizaje no supervisado. A diferencia del anterior, el operador no da la instrucción al algoritmo ni tiene la respuesta. Por el contrario, el propio algoritmo establece los patrones mediante el análisis de los datos existentes. En este proceso se deja que el algoritmo de aprendizaje no supervisado interprete grupos en los cuales se puedan clasificar los datos sobre la base de los patrones encontrados.
Ejemplos de algoritmos de agrupamiento incluyen el algoritmo de k-means, el agrupamiento jerárquico y el agrupamiento espectral. Otra estrategia que hace uso del aprendizaje no supervisado es la reducción de dimensionalidad (dimensionality reduction), que se utiliza para reducir la cantidad de variables o características en un conjunto de datos, mientras se conserva la mayor parte de la información relevante. Esto se logra mediante la extracción de características importantes o mediante la transformación de los datos en un espacio de menor dimensión. Las técnicas comunes de reducción de dimensionalidad incluyen el análisis de componentes principales (PCA).
- Aprendizaje semisupervisado (semi–supervised learning). Se utiliza un conjunto de datos que contiene tanto ejemplos etiquetados como no etiquetados. La idea es aprovechar la información de los ejemplos etiquetados para guiar el aprendizaje de los ejemplos no etiquetados. En este enfoque, los algoritmos intentan aprender patrones y estructuras utilizando tanto la información explícita de las etiquetas como la información implícita en los datos no etiquetados. El objetivo es mejorar el rendimiento del modelo al aprovechar la cantidad, potencialmente mayor, de datos no etiquetados disponibles.
- Aprendizaje reforzado (reinforcement learning). Es un enfoque por el cual un agente de aprendizaje interactúa con un entorno y aprende a tomar decisiones óptimas a través de su retroalimentación. En lugar de proporcionarse ejemplos etiquetados de antemano, el agente toma acciones en el entorno y recibe recompensas o penalizaciones según el resultado de sus acciones. El objetivo del aprendizaje por refuerzo es aprender una política o estrategia que maximice las recompensas a largo plazo. Es un enfoque comúnmente utilizado en problemas de toma de decisiones secuenciales, como los juegos, la robótica y el control de procesos (111, 112).
2.1. Algoritmos
Los algoritmos de aprendizaje automatizado que se emplean en este trabajo son:
- Algoritmos de clasificación binaria: representan una puntuación de predicción que indica la certeza del modelo usado. La tarea consiste en clasificar los datos como positivos y negativos. Para ello, el algoritmo contará con un umbral estipulado de corte para poder clasificar si un dato pertenece a la clase positiva (puntuación superior al umbral) o, en caso contrario, a la clase negativa (puntuación inferior al umbral). Por ejemplo, en la clasificación binaria solo se puede asignar un valor de 0 o 1. Un caso típico es la detección del email spam, donde: spam → será etiquetado con un 1; o no es spam → será etiquetado con un 0.
- Clasificadores multiclase: a diferencia de la categorización binaria, en la clasificación multiclase no hay un umbral (puntuación máxima o mínima) para asignar etiquetas o clases. Para llevar a cabo este proceso, este algoritmo calcula el promedio de la métrica entre todas las clases, lo que permite obtener una métrica de promedio macro o media ponderada. La métrica utilizada para evaluar su capacidad predictiva es la F1.
- Support vector machines (SVM): es un algoritmo que puede utilizarse tanto con modelos de clasificadores como de regresión (estos últimos se explicarán en páginas posteriores). Mapea los datos de entrada a un espacio de mayor dimensión para encontrar un hiperplano lineal que maximice la separación entre las clases. Además, puede emplear funciones de kernel para trabajar con patrones no lineales (112).
- Algoritmos de árbol de decisión: simulan la estructura de un árbol, donde cada bifurcación representa un resultado plausible de una decisión. Los nodos del árbol corresponden a pruebas realizadas sobre una variable específica, y las ramas indican los posibles resultados de dichas pruebas (113). Este algoritmo no fue utilizado para el análisis en este trabajo, pero sí lo fueron los algoritmos de decision forest y random forest, que pertenecen a este grupo. Estos se describen a continuación.
- Decision forest es un algoritmo de aprendizaje supervisado que utiliza múltiples árboles de decisión para realizar predicciones. Cada árbol en el bosque es una comparación donde se entrena al algoritmo con una muestra aleatoria del conjunto de datos y toma decisiones basadas en características relevantes. Luego, las predicciones de todos los árboles se combinan para llegar a una predicción final. La fuerza de esta técnica radica en su capacidad para manejar características de entrada tanto numéricas como categóricas, así como para lidiar con el sobreajuste y la falta de generalización. Este algoritmo puede aplicarse sobre variables de tipo continuas o discretas y datos etiquetados o no etiquetados.
- Random forest es un algoritmo dentro de los bosques de decisión que utiliza un enfoque de “ensamble”, en el que se generan múltiples árboles utilizando muestras aleatorias del conjunto de datos y subconjuntos aleatorios de características. Las predicciones de los árboles individuales se combinan mediante votación o promedio para obtener una predicción final (114, 115).
- Algoritmos de reducción de dimensionalidad: admiten la reducción de variables, trabajando con aquellas que permiten acceder a la información más exacta. Dentro de esta categoría se destacan los análisis de correlación, en los cuales la matriz calcula la relación entre las diversas variables y, a partir de esto, toma decisiones. El análisis de correlación es una técnica estadística utilizada para medir la relación entre variables. Su intensidad está determinada por el coeficiente de correlación, que varía entre -1 y +1. Es decir, se pueden presentar correlaciones negativas o positivas.
A continuación, se encuentran los análisis de componentes principales (principal component analysis o PCA), un método estadístico cuya utilidad radica en la reducción de la dimensionalidad de la base de datos (BDD) con la que se está trabajando. Se utiliza cuando es necesario simplificar la base de datos, por ejemplo, al elegir un número reducido de predictores para pronosticar una variable objetivo. Esta técnica forma parte de los algoritmos de aprendizaje no supervisado y solo emplea variables numéricas.
Por otra parte, están los análisis de la ganancia de información basada en la entropía de Shannon. Este análisis es particularmente útil cuando no es evidente cuánta información aporta cada atributo al resultado final. Es un buen método para obtener la relación entre las variables independientes y la variable objetivo, utilizando conceptos de entropía de la termodinámica aplicados a la información (Shannon, 1948). En este sentido, se puede obtener un ranking ordenado de las variables según la magnitud de su aporte de información hacia la variable objetivo. Se utiliza como un método alternativo al cálculo de las correlaciones estadísticas.
La entropía mide el grado de desorden o incertidumbre en un conjunto de datos, y se define como “pi, la probabilidad relativa de aparición de la propiedad i en el conjunto de datos”. Por ejemplo, p1 podría ser la probabilidad de tener cáncer de pulmón y p2 la probabilidad de no tenerlo en una población determinada. En la entropía de la teoría de la información vemos que se mide la confusión o el desorden de los datos que pertenecen a un conjunto para una variable aleatoria (VA) discreta con densidad de probabilidad p. Este valor indica la medida del desorden de la variable, que varía entre 0 y 1. Un valor de 0 indica un orden total, mientras que cuanto más cerca esté de 1, mayor será el desorden (116).
Fórmula 1. Fórmula de la entropía
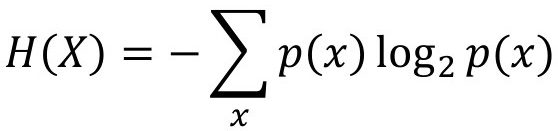
Fuente: adaptado de T. M. Cover, J. A. Thomas. Elements of Information Theory. 2nd. ed. Wiley, 2006.
Entonces, p es la probabilidad relativa de aparición de la propiedad x en el conjunto de datos. El logaritmo en base 2 se refiere a la cantidad de información codificada en bits (0 y 1). El valor calculado aquí es la medida del desorden de la variable explicada (la variable “objetivo” o “target”), con un valor que va de 0 a 1. Un valor de 0 indica un orden total, mientras que cuanto más cerca esté de 1, mayor será el desorden.[2]
Dentro de estos análisis de la ganancia de información basada en la entropía de Shannon encontramos los algoritmos de regresión logística, definidos como los métodos utilizados en el aprendizaje automático para modelar y predecir relaciones entre variables numéricas. Estos buscan encontrar la función matemática que se ajuste mejor a los datos observados, con el objetivo de poder realizar predicciones. Las técnicas pueden ser lineales o no lineales, y se basan en diversos algoritmos, como la regresión lineal, polinomial, logística, regresión de vecinos más cercanos, entre otros. Son ampliamente utilizadas en diversas áreas (economía, ingeniería y medicina) para comprender relaciones causales, hacer pronósticos y tomar decisiones informadas basadas en datos numéricos.
En particular, la regresión logística es un algoritmo de clasificación que utiliza una función logística para modelar la relación entre variables predictoras y la probabilidad de pertenecer a una clase específica. Los coeficientes se ajustan mediante optimización de máxima verosimilitud y se establece un umbral para clasificar nuevas instancias. Es ampliamente utilizado en problemas de clasificación binaria debido a su simplicidad, interpretabilidad y buen rendimiento (116).
Por otro lado, se encuentra el algoritmo bayesiano, basado en el teorema de Bayes, utilizado para calcular las probabilidades de una partición cuando se tiene conocimiento de un evento específico que ya ha ocurrido. Este enfoque clasifica cada valor de manera independiente de los demás, y así proporciona una predicción basada en la probabilidad de que un dato pertenezca a una categoría específica, según el conjunto de datos inicial. Utiliza el teorema de Bayes para modelar y realizar inferencias probabilísticas, actualizando creencias previas mediante la evidencia observada. De esta manera, combina información previa con datos recién recibidos para generar estimaciones más precisas. Los algoritmos bayesianos emplean distribuciones de probabilidad para representar la incertidumbre y calculan la distribución a posteriori a partir de la evidencia y el modelo. Son especialmente útiles cuando los datos son escasos o la incertidumbre es alta, lo que los hace aplicables en diversas áreas, como la clasificación, regresión, agrupamiento y toma de decisiones bajo condiciones de gran incertidumbre (113).
Algoritmos de agrupación (clúster): su funcionamiento se basa en la búsqueda de grupos dentro de los datos de manera iterativa, asignando cada punto a uno de los grupos representados por la variable definida (variable K). Dentro de esta agrupación, existe un subalgoritmo denominado A priori, el cual es un algoritmo de asociación que utiliza machine learning para analizar datos y buscar patrones o coocurrencias en una base de datos. Es decir, con base en el análisis de los datos obtenidos, evalúa la probabilidad de que otro dato sea seleccionado. Este tipo de algoritmo es ampliamente utilizado, por ejemplo, en el ámbito comercial, para predecir las compras de los clientes. Esto significa que, si un cliente ha comprado el artículo 1, es probable que también compre el artículo 2. Las reglas de asociación se componen de dos partes:
- Un antecedente (si): un elemento que se encuentra en el conjunto de datos.
- Un consecuente (entonces): un elemento que resulta de la combinación con un antecedente (112).
Cabe aclarar que este algoritmo no se utilizó en el análisis del presente trabajo.
Además están los algoritmos de redes neuronales, que se comprenden como unidades organizadas en capas, donde cada una se conecta a las capas adyacentes. En estas redes participan un gran número de elementos interconectados que trabajan de manera conjunta para resolver situaciones específicas. Su funcionamiento se basa en el aprendizaje a partir de ejemplos y experiencia, lo que permite modelar relaciones no lineales en los datos, especialmente cuando la vinculación entre variables es compleja o difícil de comprender. (Ejemplo: perceptrón multicapa o feedforward neural network) (117).
Figura 3. Esquemas de redes neuronales, basados en An Introduction to Neural Networks, C. C. Aggarwa
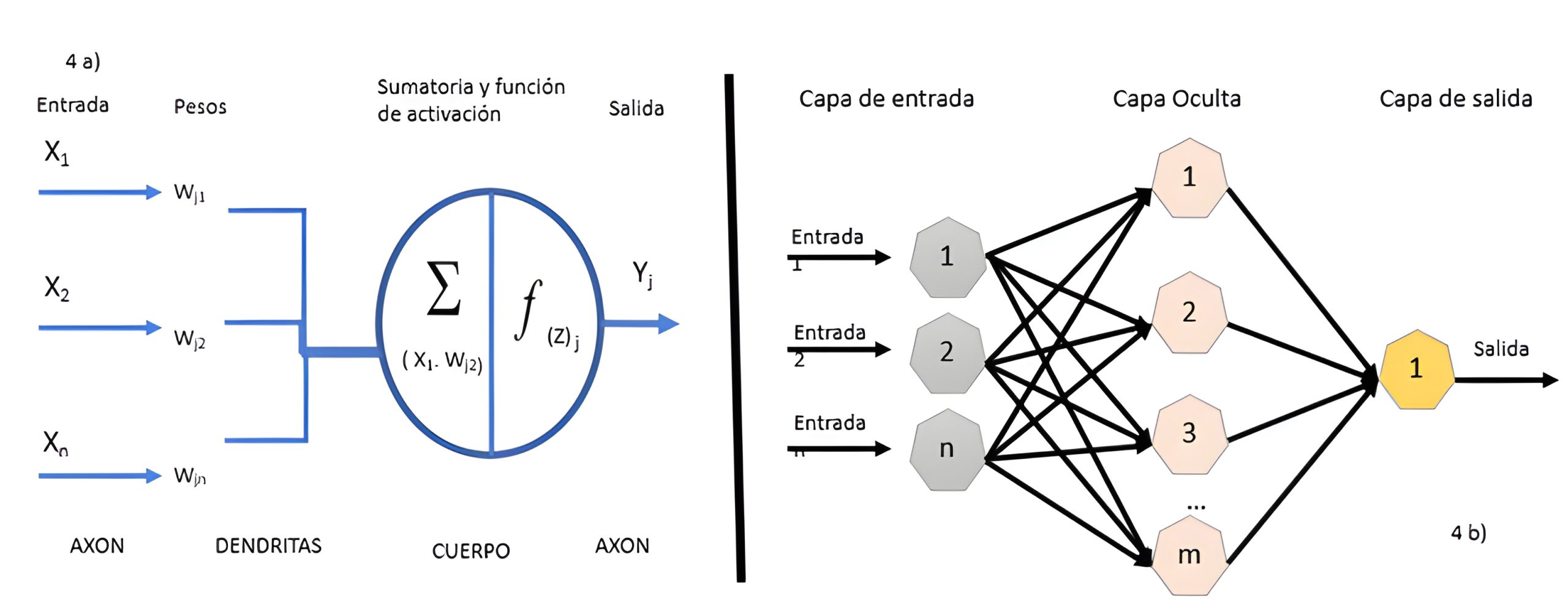
En el aprendizaje supervisado, la regulación o selección de un algoritmo para obtener mejores resultados puede ser el origen de un sesgo, debido a la participación humana. Por otro lado, en el aprendizaje no supervisado, las posibilidades de sesgos son menores porque el operador solo introduce los datos, y así permite que la máquina seleccione entre los algoritmos aprendidos y decida cuál es el más adecuado para analizar los datos y variables.
Existen métricas para la evaluación de los algoritmos, los cuales son medidores que permiten caracterizar su funcionamiento. Entre estas métricas se incluyen:
- Especificidad (accuracy): mide la proporción de predicciones correctas con respecto al número total de predicciones. Además, refleja los casos negativos clasificados correctamente por el algoritmo.
- Matriz de confusión: es una tabla que registra y visualiza las predicciones sobre un conjunto de datos categorizados, evaluando el rendimiento del modelo en términos de verdaderos positivos, verdaderos negativos, falsos positivos y falsos negativos. Es decir, cada columna representa el número de predicciones realizadas para cada clase, mientras que cada fila indica las instancias en la clase real. Esta métrica muestra el nivel de error y acierto del modelo utilizado de manera numérica.
Figura 4. Representación de la matriz de confusión

Fuente: Elaboración propia.
- El área bajo la curva (AUC): es una métrica que mide la capacidad del modelo para distinguir entre clases positivas y negativas. Cuanto mayor sea el valor del AUC, mejor será el rendimiento del modelo. Su interpretación se basa en los siguientes casos:
- AUC = 1: indica una clasificación perfecta, en la que todas las clases positivas y negativas son correctamente identificadas.
- AUC = 0: representa un escenario en el que todas las predicciones son erróneas, se clasificaron todos los positivos como negativos y viceversa.
- 0,5 < AUC < 1: el modelo tiene cierta capacidad para discriminar entre las clases positivas y negativas, logra resultados efectivos en término de verdaderos positivos (TP) y verdaderos negativos (TN).
- AUC = 0,5: el modelo no tiene capacidad de distinción entre clases, y su predicción es equivalente a una decisión aleatoria (118).
Figura 5. Representación del área bajo la curva
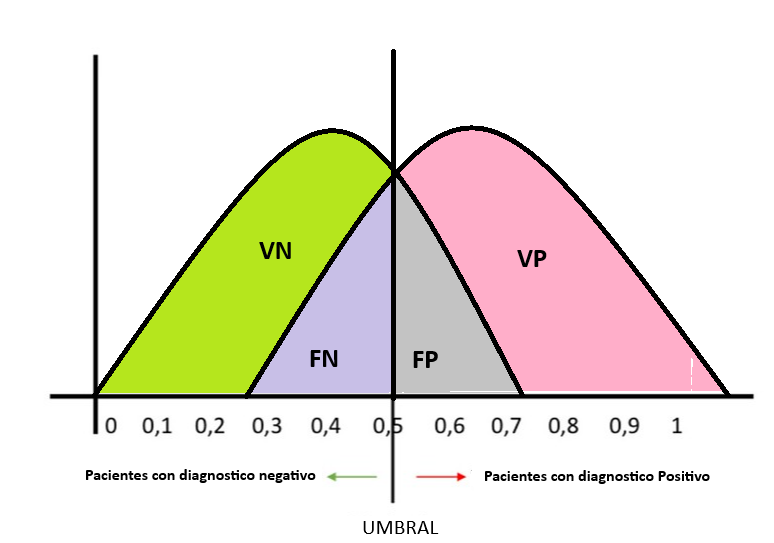
- Precisión y sensibilidad (recall): permiten evaluar la calidad de un modelo en tareas de clasificación. La precisión mide la proporción de predicciones relevantes entre las recuperadas, mientras que la sensibilidad (o recall) muestra la proporción de casos positivos que fueron correctamente identificados por el algoritmo.
Fórmula 2. Fórmula para sensibilidad (recall) = positivos reales (TP: true positives) sobre positivos reales (TP) más negativos falsos (FN: false negatives)
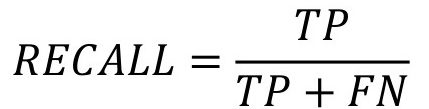
Fuente: elaboración propia.
- Puntuación F1 (F1 score): es una métrica de evaluación en el aprendizaje automático que representa el promedio armónico entre la precisión y la sensibilidad (recall). Esta puntuación se obtiene calculando la precisión y el recall (sensibilidad) del modelo, y refleja cuántas veces realizó predicciones correctas en relación con el conjunto de datos analizado (117, 119).
Fórmula 3
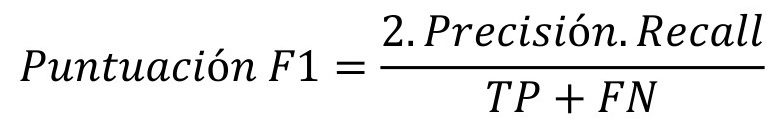
Fuente: elaboración propia.

