





Sofía Ares y Claudia Mikkelsen
Luego de los debates teórico-conceptuales arribamos al campo de la aplicación, abordando en primer término el diseño metodológico que nos permitirá medir la ruralidad y el bienestar. En consecuencia, dedicamos este capítulo a detallar los procedimientos implementados en cada instancia del proceso de investigación en torno a las ruralidades y al bienestar. Para ello primero nos detenemos brevemente en la relación entablada entre Sistemas de Información Geográfica (SIGs), técnicas y fuentes de datos cuantitativos. A continuación, describimos la construcción de los dos índices, el de ruralidad y el de bienestar en las ruralidades, con dos finalidades. En primer lugar, brindar herramientas para la comprensión de los resultados obtenidos en el sudeste bonaerense (Capítulos 6 y 7). En segundo término, para facilitar la aplicación de los procedimientos indicados en otros recortes territoriales.
Técnicas de análisis espacial y sistemas de información geográfica
Si bien las técnicas cuantitativas de sistematización y análisis de la información en Geografía son una constante a lo largo de su evolución, no es sino hasta la década de 1970 que comienza el desarrollo de los SIGs, herramienta central para el procesamiento de grandes volúmenes de datos georreferenciados. Estos procesos, herederos de los conocimientos sistematizados y profundizados desde mediados del siglo XX (Capel, 2012), adquieren cada vez mayor relevancia, sobre todo para un uso de los SIG que trascienda la mera construcción de cartografía temática y focalice –desde la teoría geográfica– en la aplicación de técnicas de análisis espacial. Sobre el particular, Linares afirma que “La clave para utilizar el SIG en tareas más complejas radica en la comprensión de los principios básicos que otorga la Geografía y que subyacen a las herramientas de modelización y análisis espacial” (2015, p. 1085); es decir, la relativa automatización de procesos complejos debe ir siempre acompañada de la reflexión teórica, conceptual, que sustenta el desarrollo de la disciplina y de los problemas de investigación sobre los que estamos trabajando.
Como heredero de los estudios que ponen el foco en la localización y la geometría (Capel, 2012), el análisis socioespacial se articula en torno a cinco conceptos: localización, distribución, asociación, interacción y evolución (Buzai y Baxendale, 2006). La localización da cuenta del lugar concreto de emplazamiento de los procesos y fenómenos que estudiamos. La distribución refiere a cómo esos procesos y fenómenos se encuentran repartidos en el territorio. En especial, es la noción de asociación la que está en el centro de los procedimientos para la identificación de semejanzas o diferencias entre áreas y, con ello, la posibilidad de acordar ciertos límites en el territorio. De este término se puede derivar el de regionalización, “pues cuando las unidades espaciales se encuentran altamente correlacionadas pueden pertenecer a una misma clase y esta, representada en un mapa, constituye una región formada por asociación de unidades espaciales (contiguas o sin contigüidad)” (Buzai y Baxendale, 2006, p. 56). La interacción refiere a los vínculos que se dan en el análisis de los elementos y acciones que constituyen a los territorios, expresa el movimiento, la dinámica. Por último, la evolución da cuenta de la temporalidad, del cambio en el devenir del espacio geográfico (Buzai, 2006).
Para trabajar desde el concepto de asociación, los procedimientos a seguir varían según se trate de bases de datos alfanuméricas o capas de información en formato raster o vectorial. En cualquier caso, la finalidad es aplicar procedimientos que permitan hacer compatibles los distintos formatos y así lograr el cálculo de una medida sintética para caracterizar y distinguir a los recortes territoriales entre sí, a partir de análisis que se concentren en la distribución territorial del índice o en las relaciones entre unidades espaciales a partir de ese indicador (Figura 1). A estas modalidades de análisis se le puede sumar la dimensión temporal (Berry, 1964), apelando entonces a la idea de evolución, con lo cual se estudian a lo largo del tiempo las variables o indicadores, como también las mediciones sintéticas (índices), permitiendo observar las variaciones en la distribución territorial en una escala temporal definida.
Figura 1. Modalidades de análisis de los indicadores sintéticos
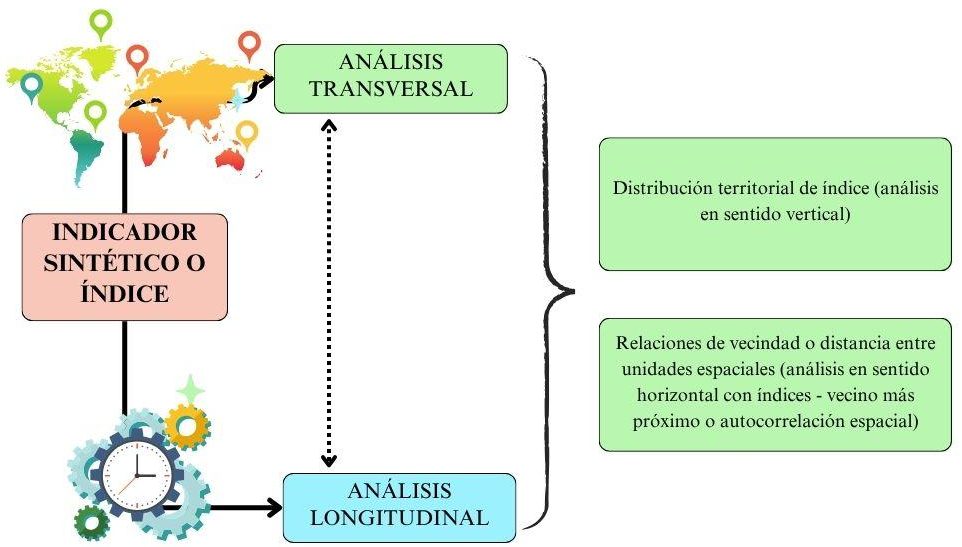
Fuente: Ares et al. (2024).
En relación con el concepto de asociación, la clasificación es otro término importante ya que “puede ser considerada como el procedimiento que permitirá agrupar objetos en clases a través de sus atributos coincidentes” (Buzai, 2003, p. 150). En pocas palabras, buscamos clasificar las unidades espaciales cuando realizamos el análisis de indicadores de forma individual o multivariada. No solo con la finalidad de visibilizar los procesos de distinción entre las unidades espaciales sino fundamentalmente para aportar a la interpretación de los procesos espaciales en estudio.
La clasificación es un procedimiento que siempre debe estar vinculado con la teoría, ya que es la forma de establecer cuáles son las propiedades relevantes que intervienen en el proceso de construcción del espacio geográfico. Como indica Harvey (1983), “Las clasificaciones se establecen con respecto a la medición realizada en un atributo, en vez de responder a la existencia o no existencia del atributo en cuestión (que por sí mismo pudiera considerarse como una sencilla medida nominal)” (1983, p. 342). Cualquier clasificación debe cumplir con ciertos requisitos, pero debe ser flexible, “ya que si se considera inamovible (por ser considerada muy buena) cristalizará una situación y desanimará la búsqueda de nuevas clasificaciones en una realidad cambiante” (Harvey, 1983, citado por Buzai, 2003, p. 150).
Estos aspectos brevemente abordados resultan fundamentales al momento de pensar en las fuentes de datos, en los indicadores que usaremos o en cómo construiremos una medida de síntesis. De un lado, a la hora de abordar un problema de investigación en particular nos vemos en la obligación de revisar la naturaleza de las clasificaciones; del otro, necesitamos en cada caso reflexionar acerca de nuestros procedimientos, tenerlos siempre como un modelo a partir del cual podemos proponer opciones que se acerquen cada vez más a la realidad. La clasificación comienza con el tratamiento inicial de las bases de datos, con el análisis univariado, el cálculo de medidas estadísticas simples y puede continuar hasta llegar a procedimientos de análisis multivariado.
Respecto de las bases de datos en formato raster, la clasificación de las unidades espaciales resultará de la asociación de capas de información, en tanto cada una corresponde a un atributo -simple o compuesto- y guarda su valor en un píxel. Por otra parte, las bases de datos en formato vectorial permiten en cada capa el análisis individual de los indicadores o su combinación.
Es tomando como base los lineamientos antes expuestos que en los siguientes apartados abordaremos en detalle los modelos de análisis propuestos para el estudio de la ruralidad y el bienestar, siempre teniendo como punto focal al territorio y al análisis socioespacial.
El Índice de Ruralidades: del concepto a la operacionalización
Entendemos la ruralidad como “las formas de vinculación que tienen los hombres y los grupos sociales con los espacios rurales, a partir de las cuales construyen su sentido social, su identidad y sus actividades productivas” (Sili, 2005, p. 45). Para responder a preguntas tales como ¿qué es la ruralidad?, ¿cómo se mide?, ¿con qué dimensiones y variables?, proponemos la operacionalización de la ruralidad, condición que posteriormente nos permite clasificar los territorios. Este primer paso es imprescindible para la toma de decisiones teóricas y metodológicas, tal como las aplicamos en la construcción del IR para el sudeste de la provincia de Buenos Aires (Capítulo 6), la que probablemente requiera ajustes para su adaptación a otros recortes territoriales.
Para nuestra área de estudio, consideramos que la operacionalización a través de tres indicadores –densidad de población, uso del suelo y accesibilidad– es adecuada para mostrar las diferenciaciones en el territorio. Se trata de una propuesta para un IR que se construye por la combinación de indicadores procedentes de capas en formato raster. El proceso se detalla en la Figura 2.
Figura 2. Diagrama metodológico para el cálculo de un Índice de Ruralidad
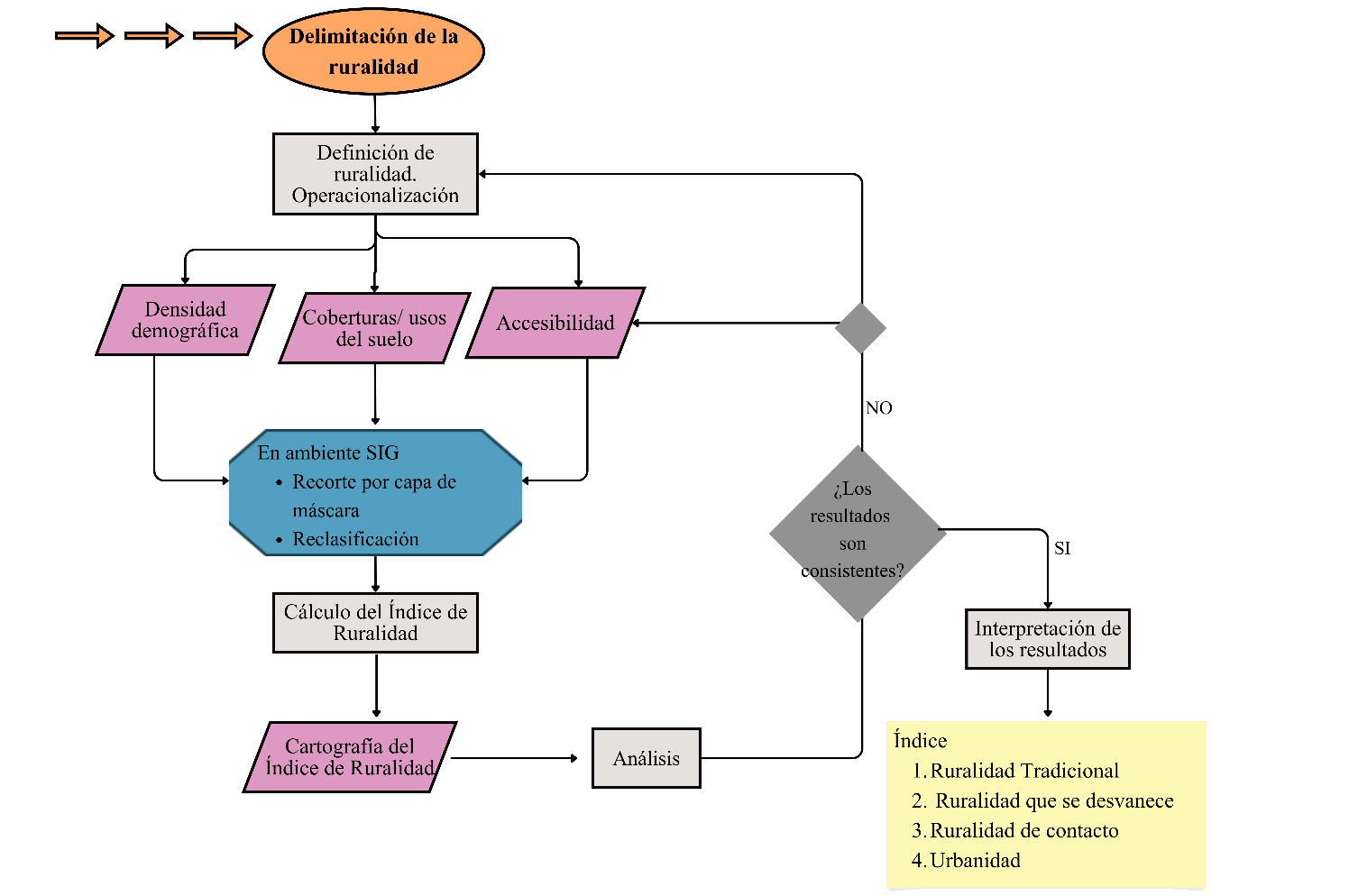
Fuente: elaboración propia.
La información en formato raster se puede trabajar a partir de la superposición temática, como indican Buzai y Baxendale (2006). Como estamos ante matrices de datos cuantitativos, es posible aplicar todo tipo de operaciones lógicas o aritméticas, a través de las cuales se puede lograr algún tipo de medida sintética, como se verá a través del cálculo del IR en el Capítulo 6. Para aplicar estos procedimientos no solo se debe trabajar con capas que estén en la misma escala y proyección, sino que además cada píxel debe contar con un número que lo identifique de forma unívoca.
El trabajo técnico comienza con la revisión de las capas raster disponibles. Estas pueden estar en escalas diferentes a la elegida (el total nacional, el continente, el mundo entero). Por lo tanto, el primer paso es delimitar el área de estudio a partir de recortes con una capa de máscara.
Luego, como paso previo a la superposición y aplicación de cálculos, es habitual realizar reclasificaciones de las capas temáticas. Estas tienen por finalidad simplificar las capas raster y de este modo generar otras con menos categorías o con una clasificación ad hoc al objetivo de investigación. Es a través de la reclasificación que se arriba a la confección de mapas de tratamiento (Buzai y Baxendale, 2006), como procedimiento que precede a la construcción de cartografía de síntesis, es decir, la que resulta de la combinación de dos o más mapas.
En el caso del IR, las tres capas de tratamiento son los insumos para su obtención como un promedio ponderado entre ellas. La ponderación dependerá de las características del índice que se desea calcular, como también del área en la que se está trabajando y de la información que se encuentre disponible. Dependiendo del recorte de estudio y de los indicadores elegidos podría trabajarse sin asignar pesos diferenciales.
IR = (Cx1 * py1 + Cx2 * py2 + Cx3 * py3)
Donde: Cx es cada capa raster y pyi es la ponderación correspondiente.
Una vez generada la capa resultante del cálculo, se puede proceder a la elaboración de cartografía temática, cálculo de estadísticas zonales u otros procedimientos adecuados al objetivo de investigación.
La medición del bienestar social
Tradicionalmente el bienestar social se ha medido con tres enfoques, el contable, el utilitarista y el de indicadores sociales. El tercero es el de aplicación más extendida en tiempos recientes, es el que sostiene la propuesta desarrollada en lo que sigue y que se aplica en el Capítulo 7. Desde lo conceptual se entiende que “Un indicador social es una herramienta estadística válida para la descripción y el análisis de la realidad socioeconómica y para las comparaciones entre diferentes unidades territoriales” (Pena, 1994, p. 211 citado por Núñez Velázquez y Rivera Galicia, 2003, s/p). Bauer, también referido en Núñez Velázquez y Rivera Galicia (2003), agrega que los indicadores sociales permiten establecer dónde se posicionan los grupos sociales y hacia dónde se dirigen, teniendo en cuenta valores y objetivos. Como se sostiene en el documento de PREVAL/PROGENERO (2004, p. 10), “la palabra indicador, que proviene del latín indicare (señalar, avisar, estimar), alude a hechos o datos concretos que prueban la existencia de cambios conducentes hacia los resultados e impactos buscados”. En consecuencia, se puede decir que un indicador es una estadística, un número que provee información más allá del dato concreto, permitiendo un conocimiento más comprensivo de la realidad que se pretende analizar.
La revisión presentada en el Capítulo 3 muestra que es notable la complejidad involucrada en la medición del bienestar, incluyendo en este proceso diferentes pasos que van desde la conceptualización hasta la operacionalización. Se trata de una labor que depende de la disponibilidad espacial y temporal de la información necesaria para su construcción, como así también de los acuerdos subjetivos que los investigadores deben hacer respecto de qué dimensiones e indicadores serán empleados. En tal sentido, la selección supone una retroalimentación entre el concepto (entendido como lo deseado o lo ideal), su operacionalización y la exploración de fuentes de datos secundarias (concebidas como lo posible o lo existente hasta el momento).
Los estudios de bienestar con enfoque territorial implican un nivel mayor de dificultad, dado que se suman como obstáculos las decisiones acerca de la escala, la falacia ecológica o el problema de la unidad espacial modificable (Velázquez, 2004). No obstante, son estudios esenciales que ofrecen miradas integrales al problema del bienestar, poniendo el eje en la territorialidad de las poblaciones involucradas. El territorio es el núcleo central de las investigaciones geográficas y su abordaje, indican Buzai y Montes Galbán, “no puede hacerse simplemente desde un punto de vista discursivo, sino que resulta necesario actuar de forma concreta sobre la realidad” (2021, p. 31). Por ello, los resultados obtenidos se convierten en conocimiento académico sobre las desigualdades, las brechas e injusticias espaciales y a su vez en posibles insumos para la gestión, la instrumentación de políticas específicas y su monitoreo. En particular, se debe considerar que herramientas como los SIG participan del proceso de investigación en sí mismo,
[…] se rescata aquí el papel de las prácticas geográficas como inicio y final de este proceso, el camino de salida y llegada, desde y hacia el nivel empírico. En este camino, el análisis espacial cuantitativo se transforma en el hilo conductor que toma las definiciones previas, el problema y genera resultados que se transforman en herramientas para su solución (Buzai y Montes Galbán, 2021, p. 31).
La posibilidad de encontrar recortes territoriales de relativa homogeneidad permite al profesional de la Geografía “delimitar al espacio geográfico o descubrir concentraciones. Ese trazado de áreas se transforma en una herramienta importante de planificación” (Buzai y Montes Galbán, 2021, p. 36). En consecuencia, se pasa del análisis de indicadores sociales en forma individual a la construcción de índices sintéticos que permiten definir y caracterizar recortes territoriales específicos. Los índices de bienestar se resuelven a través de distintas técnicas de base estadística, pudiendo o no tener ponderaciones que den cuenta de la relevancia de cada una de las dimensiones. En palabras de Núñez Velázquez y Rivera Galici (2003),
[…] un indicador sintético se define como la agregación de información a partir de un conjunto amplio de indicadores simples de contenidos diversos. En esta línea, la construcción de un indicador sintético de bienestar tiene sentido como medida única de la situación social en una unidad territorial para comparar dicho bienestar tanto en sentido transversal (entre diversas unidades territoriales), como longitudinal (evolución de la situación del bienestar a lo largo del tiempo en una misma unidad territorial) (s/p).
Actis Di Pasquale (2015) añade que:
[…] los índices sintéticos de bienestar social representan una medida que se obtiene mediante la agregación adecuada de un conjunto de indicadores sociales que pertenecen a las distintas dimensiones de ese concepto. Su elaboración no es sencilla, ya que los indicadores son de distinta naturaleza y provienen de diferentes fuentes de datos (p. 1).
Se puede marcar como una tradición en los estudios del bienestar la construcción de índices sostenidos en datos secundarios procedentes de diversas fuentes estadísticas oficiales y no oficiales, es decir, a partir de la generación de indicadores cuantitativos. Notamos que las propuestas procedentes de las Ciencias Sociales, como la Geografía, la Economía o la Sociología, se articulan con el enfoque territorial sumando opciones de análisis, las que colaboran en el estudio de la complejidad implícita en el bienestar social y su operacionalización.
Podemos sintetizar en cinco los pasos para la construcción de un índice sintético: selección de los indicadores; elección de la técnica de estandarización; de la ponderación; del método de agregación y validación. Todos ellos son fundamentales para construir una medida robusta, con capacidad para dar cuenta de las situaciones de bienestar que caracterizan al territorio (Actis Di Pasquale, 2015).
Un detalle importante al momento de diseñar un índice radica en la elección de indicadores que tengan la misma direccionalidad. Es decir, que tengan igual sentido, sea de beneficio o de costo. Los de beneficio son aquellos que “en sus puntajes máximos indiquen condiciones favorables” (Buzai y Baxendale, 2006, p. 270), con lo cual constituyen el punto de partida esencial para la obtención de medidas de bienestar, debido a la direccionalidad positiva que reviste el concepto (ver Capítulo 3).
En cuanto al método de agregación, Actis Di Pascuale (2015) concluye que el de la media ponderada es válido para la cuantificación de niveles de bienestar y además es de fácil interpretación. Se trata de un método en el que “se realiza solamente la agregación, con lo cual primero hay que estandarizar las variables y luego decidir y aplicar los factores de ponderación” (Actis Di Pascuale, 2015, p. 8).
Respecto de la ponderación, puede o no realizarse. Cuando se trabaja sin ponderación se asume que todos los indicadores tienen el mismo peso, tal como en este caso.
El cálculo de un índice simple, sin establecer ponderaciones diferenciales a cada indicador, resulta del promedio entre todos los indicadores estandarizados, sea por puntajes Omega o Z.
ÍNDICE SIMPLE = (I1+ I2+ I3) / 3
Se plantea que “en muchas ocasiones puede ser conveniente usar ponderadores idénticos cuando las variables estén altamente correlacionadas entre sí, sin que ello implique la presencia de redundancia explicativa puesto que esos elementos correlacionados explican aspectos diferentes del fenómeno en cuestión” (Schuschny y Soto, 2009, citados por Actis Di Pasquale, 2015, p. 8).
Una vez establecidas las dimensiones o dominios que serán empleados, y seleccionados los indicadores, se les asigna ponderación diferencial, esta es una decisión del investigador o del equipo de investigación, condicionada por el problema de investigación, por el contexto en el que se trabaja y por el comportamiento estadístico de las series de datos elegidas. De este modo, cuando decidimos trabajar con ponderación, la media ponderada surge de la sumatoria de los productos entre indicador y ponderación (la suma de ponderaciones debe ser 1 o 10 o 100).
ÍNDICE PONDERADO = (I1* p1) + (I2* p2) + (I3* p3)
El potencial del análisis territorial, combinando técnicas cuantitativas con los SIG, permite sintetizar las situaciones representadas por un amplio volumen de datos.
El tratamiento de información en formato vectorial implica el trabajo con bases gráficas y tablas alfanuméricas. Para la Geografía, en cualquier caso, estas se organizan con el formato de matriz de datos geográfica (Berry, 1964). En ella, en la intersección de cada fila y columna se define una celda, cada una de las cuales contiene una característica de un hecho geográfico (Berry, 1964, p. 5). Luego, cada conjunto de celdas puede analizarse en sentido vertical, comparando las unidades espaciales o en dirección horizontal, siguiendo la idea de inventario de localización.
A partir de la matriz de datos geográfica es posible implementar distintas técnicas de clasificación. Según se explica, cada unidad espacial “se diferencia de la contigua, y los procedimientos técnicos de clasificación son los que permitirán agruparlas de acuerdo a sus semejanzas a través de la intensidad encontrada” (Buzai y Baxendale, 2006, p. 269). Por lo tanto, para lograr la identificación de diferencias y delimitar el territorio, las tareas comienzan con la construcción de la Matriz de Datos Originales (MDO), luego transformada en Matriz de Datos Índice (MDI) como paso previo a la estandarización.
La matriz de datos o atributos se asocia con una capa gráfica utilizando un SIG. Dentro de este software o en alguna aplicación de hojas de cálculo, se realizan las operaciones aritméticas necesarias para obtener la Matriz de Datos Estandarizados (MDZ), a partir de la MDI. Mediante la estandarización se logra normalizar las distribuciones con igual promedio (0) y desvío estándar (1), lo que permitirá confeccionar mapas comparables y calcular una medida sintética (Buzai, 2003), como es el IBR que presentaremos en el Capítulo 7.
El IBR se calcula para los radios censales con distintos tipos de ruralidad que integran la región bajo estudio. Mostramos a continuación los pasos implicados en la confección del índice, reservando los detalles acerca de las fuentes de datos y selección de indicadores, como así también los resultados para el Capítulo 7, dedicado específicamente al bienestar en el sudeste bonaerense, recordando en cuanto a la replicabilidad que cada equipo de trabajo propondrá una medición adecuada al contexto de investigación.
Entendemos que es primordial plantear la distinción entre dimensiones, variables e indicadores deseables y posibles. Los primeros refieren a la construcción metodológica que los investigadores proponen como abarcativa de la realidad rural en estudio, y lo que entienden que es más apropiado para su operacionalización. La segunda, en cambio, alude a lo posible, teniendo en cuenta los datos disponibles en fuentes diversas, a veces inconexas, que relevan cierta información, repiten alguna u omiten otra y que no siempre refieren a la misma escala o nivel de desagregación espacial. A continuación, el problema más difícil de superar suele ser definir entre “lo mejor” y “lo posible” en un determinado contexto decisional. En este caso, la disponibilidad de información referida al tema de investigación a nivel de los radios censales del sudeste bonaerense es limitada, pero constituye el campo de lo posible. Siendo conscientes de esta situación es que se determina “lo mejor” con base en criterios preferenciales y cargados de subjetividad del equipo de investigación. A través de la intersección de ambas fases se determina la “solución óptima” (Romero, 1996).
La metodología propuesta para la medición del bienestar rural cuenta con su aplicación previa en otras escalas territoriales, como la nacional, la provincial y la regional (Ares et al., 2025; Mikkelsen et al., 2018; Mikkelsen et al., 2020). Cuando se decide trabajar a escala de radios censales, en ocasiones hay indicadores que solo se encuentran disponibles por ejemplo para departamentos o partidos, con lo cual su incorporación a un índice debe hacerse teniendo en cuenta las limitaciones implicadas. Constituye, sin embargo, una opción adoptada por otros investigadores, como es el caso de Velázquez et al. (2022), quienes señalan que “dado que la información a escala departamental es más fácil de obtener que la del radio censal, en algunos casos, es necesario realizar una adaptación de ambas” (2022, p. 630). En estas situaciones, los puntajes disponibles a escala de los partidos se asignan a cada uno de los radios que los constituyen (Velázquez et al., 2022).
La secuencia metodológica, una vez acordadas las dimensiones y variables con las que se trabajará, consiste en diseñar la MDO que luego se transforma en MDI. Si hay indicadores que, previo a su tratamiento, no siguen la direccionalidad positiva, se deben transformar en su complemento. A continuación, se estandariza la MDI sobre puntajes omega o zeta, conformando la MDZ (Buzai, 2003).
Según indica Buzai (2003), con la obtención de puntuaciones Z, “cada dato original se transforma en un puntaje que se desvía en valores positivos y negativos respecto de =0 siendo σ =1” (p. 112). De este modo, se logra la comparabilidad entre la totalidad de los indicadores.
Si se define emplear como estrategia de estandarización los puntajes Omega la fórmula será la siguiente:
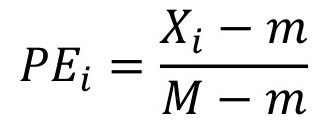
Donde PEi es el puntaje estándar, Xi es el dato original para estandarizar, mientras que m y M son respectivamente el menor y el mayor valor del indicador (Buzai, 2003).
Por su parte si se estandariza por puntajes Z, esta es la fórmula:
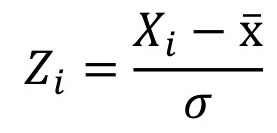
Donde: Zi es el puntaje Z de la variable Xi; Xi: es la variable por estandarizar; x̅ es la media y σ es el desvío estándar de la variable X para toda el área de estudio.
Finalmente, el índice, en nuestro caso el IBR, se obtiene mediante el promedio simple o ponderado de cada uno de los indicadores seleccionados.
Los procedimientos descritos se aplican en el Capítulo 7 y quedan representados de forma sintética en el diagrama representado en la Figura 4.
Figura 4. Diagrama metodológico para el cálculo de un Índice de Bienestar de las Ruralidades

Fuente: elaboración propia.
La reflexión teórico-conceptual, como también los pasos implicados en la operacionalización, selección de fuentes de datos y construcción de indicadores, constituye un momento esencial en todo proceso de investigación. Consideramos además que, al mismo tiempo, constituye un aporte para la posible aplicación de estas técnicas en distintos ámbitos, adecuando las operacionalizaciones a las características de cada territorio y de la sociedad que lo vive y construye. En nuestro caso la propuesta de aplicación se hace para el sudeste de la provincia de Buenos Aires, que toma rol protagónico en la tercera parte de este texto.
