





En este capítulo vamos a explicitar los resultados más significativos obtenidos a partir del procesamiento de los datos. Debe recordar el lector que al abundante material obtenido automatizadamente tuvimos que filtrarlo por atributos y enlaces.
¿Qué hubiera sucedido si conservábamos la totalidad del universo capturado? En nuestro caso no hubiéramos contado con la capacidad de cómputo necesaria para esas cantidades, por lo demás la información producida no hubiera respondido a nuestros objetivos que apuntaban a trabajar comparativamente sobre geolocalizaciones urbanas, de modo que se seleccionaron aquellos datos relacionados directamente con las hipótesis y objetivos expresados.
Dicho brevemente este capítulo tiene cuatro momentos. Vamos a analizar en primer lugar la configuración de vínculos de red social de las 5 ciudades seleccionadas inicialmente. Como dijimos, se descartaron algunas que se había propuesto al principio de nuestra indagación ya que una vez concluida la captura de datos se establecieron usuarios cuantitativamente no significativos para poder realizar las comparaciones que nos habíamos propuesto. Hemos obtenido material de geolocalización de prácticamente usuarios de las ciudades más importantes del planeta y todos esos datos han sido marginados para continuar eventualmente.
Analizaremos entonces los datos de Buenos Aires, San Pablo, Barcelona, Rosario y Córdoba. De las tres primeras se trabajó luego con la élite de usuarios con mayor centralidad de grado.
Luego, en un segundo momento, se presentarán los hallazgos cartográficos de las territorializaciones que se lograron al procesar las geolocalizaciones de los grupos de usuarios que se habían seleccionado previamente: el objetivo central era correlacionar los checkins de los usuarios con mayor centralidad de grado con el resto de la comunidad de usuarios de 4SQ®.
En tercer lugar se señalaran elementos en proceso de elaboración sobre la posible articulación formal entre los dos apartados anteriores, es decir, entre la capa topológica de configuraciones y la capa topológica de territorializaciones, esbozándose líneas de para continuar avanzado en próximos desarrollos y que problematizan la cuestión de las tendencias alrededor de los centroides urbanos.
Por último se presenta una encuesta web cuantitativa no probabilística que consideramos debería ser comprendida como contexto de los datos anteriores.
Topologías de redes en 4SQ®
Como desarrollamos en el apartado metodológico realizamos una larga y lenta recolección de usuarios y enlaces que nos demandó aproximadamente 2 años. Luego de la recolección hubo que realizarse la estructuración de los datos y posteriormente el control. Del control se encontraron anomalías (usuarios con más de 10 usuarios por anillo) que debieron ser detectadas y subsanadas mediante códigos que se escribieron a tal fin.
Consideramos que, dados los sesgos que podrían esperarse del método bola de nieve, la incorporación del mayor número de nodos posible a nuestra capacidad de recolección y procesamiento, nos acercaría progresivamente a una tendencia asintótica respecto a la cual a mayor volumen de datos se obtendrían menos novedades de sentido. Indudablemente, los datos acerca de la cantidad real de usuarios, sus enlaces y atributos registrados en 4SQ nos hubiera servido, pero no obtuvimos esa ni otra información de los responsables de la plataforma[1].
A continuación procesamos y estructuramos los atributos por usuario de Foursquare® y luego se extrajo información para aquellos que habían ingresado en la configuración de su perfil su usuario de Facebook®. Se intentó la misma operación con Twitter® pero dificultades técnicas relativas a la API de esa aplicación nos hicieron desistir de esa toma de muestra.
Como se expresa en la ilustración de abajo, clasificados los usuarios por sus sexos declarados en el perfil, volvimos a obtener un leve predominio masculino semejante al conseguido durante la encuesta y en otras investigaciones sobre la plataforma 4SQ®, citadas en el estado del arte:
Ilustración 21
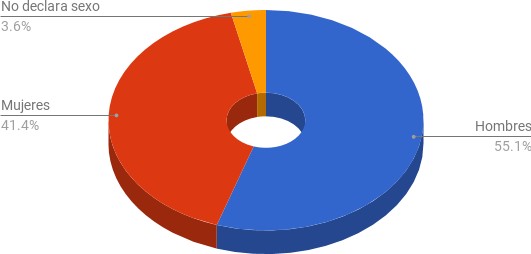
Perfil de género obtenido en la lectura de la API de 4SQ®.
Respecto a los idiomas declarados en los perfiles se obtuvieron un total de 52 idiomas, que una vez rankeados por cantidad de usuarios y dispuestos gráficamente nos mostró una distribución exponencial, con los principales idiomas agrupándose en un efecto mateo, que fueron el español y el inglés, y una cola larga que incluyó portugués, turco, polaco, francés, alemán, tailandés, holandés y otros, muchas veces con variedad de subtipos.
Ilustración 22
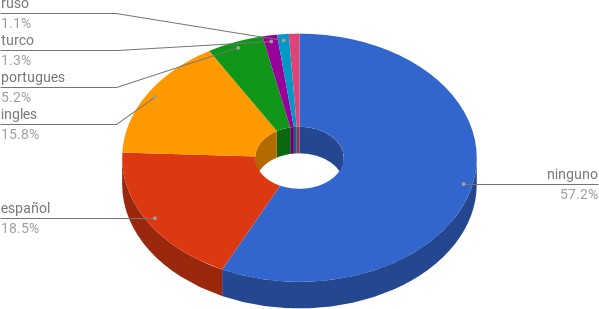
Principales idiomas declarados por los usuarios recolectados en la toma de muestra.
Como se puede visualizar más de la mitad de los usuarios no completa el perfil del idioma, situación que se podemos extender al resto de los atributos solicitados al inscribirse en la plataforma.
A continuación ofrecemos los perfiles de usuarios recolectados y procesados de las ciudades sobre las que realizamos las interpretaciones:
Ilustración 23
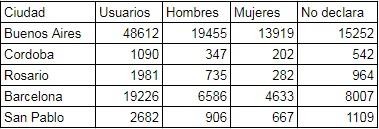
Usuarios discriminados por género después de la selección de la base total obtenido.
Las ciudades de Buenos Aires y Barcelona fueron las más productivas en usuario y relaciones de amistad. Podemos reconocer también que existió un interés mayor de los usuarios por dejar registrado género respecto a su idioma. Las causas pueden ser muchas (se da por sobreentendido a partir del nombre, razones lúdicas, de diseño de pantalla, de orden de aparición en el protocolo de creación de perfil, de orden psicológico, etc.), sin embargo el 40 % aproximadamente no declaró su sexo.
Se procedió luego al matizado específico con software para Análisis de Redes Sociales. Se obtuvieron así, de los 73591 usuarios, un total de 61064 enlaces. Es decir que para cada usuario existía en promedio un poco menos que un enlace. Debería resultar llamativo este primer hallazgo, ya que como dijimos este tipo de redes debería proveernos de volúmenes de enlaces al menos decenas de veces superiores respecto a los usuarios, sin embargo debe tenerse en cuenta que se recortó una red topológica con un criterio geográfico, lo que dejó por fuera de la matriz a todos los enlaces de amistad que apuntaran por fuera de cada ciudad. Es decir que se descartaron por este método los triángulos de enlaces de amistad que existen entre usuarios de distintas ciudades declaradas en el perfil.
Si bien el abrupto sesgo generado recorta la abundancia de enlaces notablemente respecto a las expectativas creadas en la fase de observación participante, y siendo los links los elementos que a su vez enriquecen el análisis de redes sociales, nos sitúa en un lugar inmejorable para conocer las relaciones topo- geográficas que nos interesaban investigar de acuerdo a nuestros objetivos.
La figura que sigue permite ver parte de una captura de pantalla en la que se muestran tal como aparecen los datos en el programa Gephi. Por motivos de diseño de esta presentación se excluyen algunas columnas de atributos cargados en la base. Sin embargo otro hallazgo fue que la tasa de llenado de atributos fue mucho más baja de lo esperado (escolaridad, religión, etc.) aun respecto a los datos de género e idioma (aproximadamente el 2 -5 %).
Ilustración 24
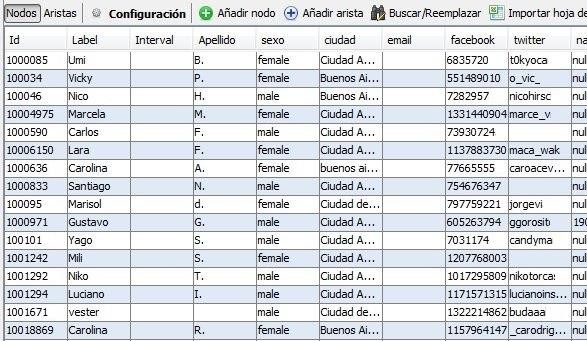
Captura de pantalla de parte de los datos obtenidos en bruto de la recolección de datos. Los datos fueron modificados para mantener el anonimato de los usuarios.
Luego de recortar la red de usuarios pudimos establecer las propiedades redológicas de cada ciudad. En la tabla de abajo se expresan los valores obtenidos para las diferentes propiedades de red en cada una de ellas.
Ilustración 25

Propiedades de las redes de las ciudades seleccionadas.
Analizaremos la tabla con algún detalle y en el capítulo siguiente expresaremos las principales conclusiones, sin embargo es imposible un desglose absoluto de uno y otro que no implique cierta dificultad de comprensión.
En la primera columna de datos específicos de redes sociales, luego de los descriptos usuarios y sus vínculos bidireccionales (ya que al ser A amigo de B por defecto B es amigo d A) reconocemos el Grado medio de la red, una métrica de grafo que expresa el número promedio de conexiones entre todos los usuarios, siendo las conexiones en este caso las relaciones de amistad que se obtuvieron de las 10 al azar que ofrece la plataforma en cada anillo de lectura.
Se trata de una red que podríamos clasificar como de un grado reducido respecto a otras, en las que la cantidad de enlaces supera evidentemente a la de los nodos. ¿Qué pasaría si tuviéramos a disposición todos los usuarios y enlaces que tienen registrado 4SQ®? Desde ya no podemos saberlo, pero seguramente, si representáramos en un gráfico del grado en el eje Y con la cantidad de usuarios en el eje X, obtendríamos una curva de distribución de grados que tendría una pendiente mucho más empinada, lo que es lo mismo que decir que tendríamos nodos mucho más cargados de enlaces que en nuestra base de datos.
Siguiendo la lectura de la tabla, al avanzar en la columna siguiente de los valores y encontramos otra métrica del grafo que parece contradecir a la columna anterior. Se trata del diámetro de red, que en este caso se ubica en un intervalo de 9-23 nodos, si consideramos la totalidad de las ciudades.
Esto constituye una evidencia interesante y sobre la que debemos hacer un breve alto en el camino analítico. Consideremos que si la mayoría de los usuarios estuviera enlazado más o menos al azar, siguiendo una lógica browniana de interacción (Cohen, 1986), deberíamos esperar diámetros mucho mayores para una red de casi 50 mil usuarios como la que tenemos delante, solo considerando a Buenos Aires. ¿Qué nos dice este valor obtenido? Debe ponerse en relación con los otros, pero a primera vista nos induce a considerar que algunos nodos deben presentar posiciones claves en la configuración general de la red de cada ciudad, puntos de la estructura donde deben integrarse caminos entre nodos que deberíamos considerar relativamente asilados siguiendo lo analizado al observar los valores conseguidos para los grados medios.
Luego, avanzando a la siguiente columna, encontramos los datos conseguidos para valorar la modularidad (Newman, 2006), que es otra medida de la estructura del grafo y que expresa la fuerza de la división de los grupos, comunidades o clústeres en una red.
El valor de la modularidad se encuentra por definición en el intervalo (-5, 1) y será positivo si el número de links dentro de los clústers supera el número esperado, sobre la base del cálculo aleatorio. Dicho de otro modo la modularidad refleja la concentración de los nodos dentro de los grupos, en comparación con la distribución al azar de los enlaces entre todos los usuarios, independientemente de los reconocidos para los módulos. En esta caso se utilizó una resolución de 1.0 (cuanto menor, más comunidades) y se consideraron los pesos de las aristas.
La siguiente columna nos informa sobre la densidad del grafo, que es la proporción entre el número de conexiones que existen en una red y el número de conexiones que serían posibles dentro la misma red (Velázquez, 2005). El valor de la densidad de una red oscilará siempre entre 0 y 1 siendo en este caso que las ciudades presentan con este sesgo metodológico una densidad baja. En este caso se registraron densidades iguales o superiores a 0,001, conjunto dentro del cual podemos incorporar a Córdoba y Rosario. El resultado es congruente con otras observaciones en las que se rankea ciudades y se las relaciona con la densidad.
La columna siguiente nos muestra la longitud media de camino (LMC), métrica que nos informa el número promedio de enlaces que hay que recorrer a través del camino más corto para todos los posibles pares de nodos de una red. Es decir, se deben evaluar todos los posibles recorridos de nodo a nodo, de cada nodo con los restantes de la matriz, de ahí extraer los más cortos para cada par y luego establecer la media.
Indudablemente para trabajar con redes sociales con tal cantidad de usuarios y ciudades se necesita un programa de computación acorde a la cantidad de cálculos necesarios. Se trata de una medida sofisticada de la eficiencia en el transporte de información a través de una red, que en este caso nos dice que en términos de trazo grueso, la LMC tiene una distancia en enlaces aproximada a la mitad del diámetro. Esto significa que esa sería la media de pasos que debería recorrer una novedad para difundirse entre los individuos. Claro está que el significado de esta métrica debe ser puesta en relación con las otras.
Las dos últimas columnas están relacionadas entre sí: la cantidad de triángulos y el Coeficiente Medio de Clústering o Coeficientes de Agrupamiento Medio (CMC) que mide la densidad local y le pone valores entre 0 y 1. Es una medida global, pero que indica la probabilidad de que dos vecinos de un tercer nodo de la red, escogidos aleatoriamente, estén conectados entre sí. Es un valor importante, porque ha sido considerado como uno de los indicadores de vitalidad de una red social.
Regresando a la interpretación de la tabla de datos, en nuestro caso podría decirse que dentro de esta configuración de red, la probabilidad de que dos usuario que se conocen tenga otro usuario formando un triángulo con ellos es de aproximadamente 1/20.
Ilustración 26
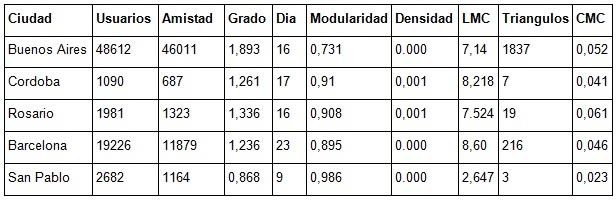
Valores de red para las ciudades comparadas.
Como se ve en la ilustración de arriba, posteriormente se seleccionaron los nodos más conectados (centralidad de grado) de cada ciudad y con ellos se reevaluaron las propiedades de red. El objetivo fue evaluar la progresión de las propiedades topológicas. Mostramos acá los resultados para la ciudad de Buenos Aires.
Nótese que en ciudad, al seleccionarse el grupo del 10% de usuarios con mayor grado de centralidad, aumenta el grado medio y consecuentemente la LMC tiende a disminuir. Otro elemento significativos es el de la relativa estabilidad de las comunidades (removiendo el 90% de los usuarios eliminamos sólo la mitad de los triángulos), lo que se relaciona con el aumento del CMC.
Se trata de una tendencia a no descuidar analíticamente, porque nos está diciendo que a medida que avanzamos sobre los usuarios mejor conectados en grado de centralidad, tenemos un mejor agrupamiento y velocidad de transporte de novedades, lo que también es un índice de que aumentaría la probabilidad de que se produzca efecto pequeño mundo dentro de ese rango de usuarios, y por lo tanto, aumente la resiliencia de la red a estímulos externos.
Podemos observar que, seleccionados esos usuarios más conectados en Buenos Aires obtuvimos un aumento en el grado medio, la modularidad y la densidad. Esta situación es esperable debido a la metodología por medio de la cual se extrajeron los nodos de la red: si nos apresuráramos podrías confundir clusterización con sesgo de muestra.
Luego decidimos evaluar la perdida de nodos y enlaces a medida que descartábamos grados de centralidad. Como se observa en la figura que sigue, en una primera fase hay una pérdida moderada de usuarios y relaciones de amistad, que en pocos grados de evolución tiende a estabilizarse, para volver a perder nodos y enlaces cuando nos encontramos con mayores valores de grado, en la cúspide de la elite de usuarios.
Ilustración 27
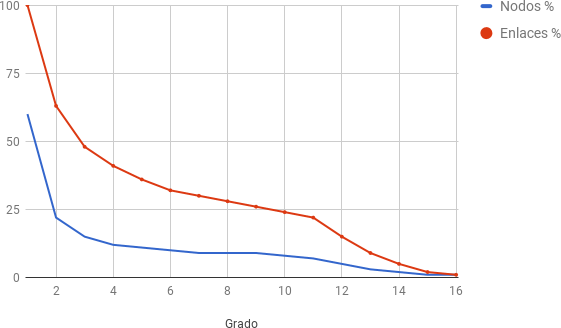
Esquema que representa la reducción del porcentaje de usuarios y relaciones de amistad en 4SQ® de Buenos Aires. Eje Y porcentaje de Usuario, el Eje X al Grado topológico.
El siguiente problema fue determinar aproximadamente cuál sería la muestra más adecuada a obtener del descremado previo de usuarios de Buenos Aires, dado que nuestro objetivo es aislar a los usuarios con mayor grado y compararlos con el resto de los usuarios de cada ciudad. Para determinar eso consideramos que la vitalidad o resiliencia podría ser un factor a tomar en cuenta. Fue así que relacionamos el CMC como variable dependiente a medida que movíamos el grado de la red, como se puede ver en la figura que sigue:
Ilustración 28
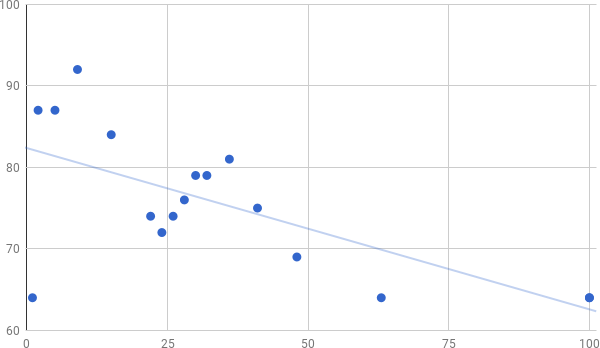
Esquema que representa la evolución del Coeficiente Medio de Clustering (CMC). Eje Y: CMCx100, Eje X: Porcentaje de enlaces respecto al total de Buenos Aires.
La observación de la ilustración nos orienta hacia la percepción que nos interesa extraer de este cuadro, a saber: podemos retirar más del 95% de los usuarios y la vitalidad de la red se mantiene relativamente estable, y por lo tanto podemos esperar que también que el resto de las propiedades de red lo hagan. Dicho de otro modo las relaciones de amistad entre usuarios más activos en el enlazado mantienen una estructura integrada y funcional.
Por último aislamos al 1% de los usuarios con mayor centralidad de intermediación de la ciudad de Buenos Aires para analizar la propiedad de la red- elite, tal como se puede observar en la tabla que sigue:
Ilustración 29

Propiedades de red del 1% de usuarios con mayor grado de centralidad.
Más allá de la discusión que hemos retomado en los antecedentes teóricos respecto a si se trata o no de la mejor medida para evaluar la capacidad de control que puedan tener algunos usuarios hubs para hacer circular o detener paquetes de información al resto de la red, tema que profundizaremos en las conclusiones, podemos reconocer que existe un grupo de usuarios claves que son los que integran la red.
Al relacionar los datos de la tabla podemos reconocer que en la élite mejor conectada de la red aumenta la proporción de enlaces respecto a la cantidad de usuarios, así como el grado medio. Tenemos entonces una red social más consistente. Es llamativo que aumente el diámetro y la densidad respecto a los mismos usuarios cuando están integrados al 10 % más conectado y a la totalidad de los usuarios de la ciudad.
Visualizar la tabla anterior como un grafo puede ayudarnos en su comprensión:
Ilustración 30
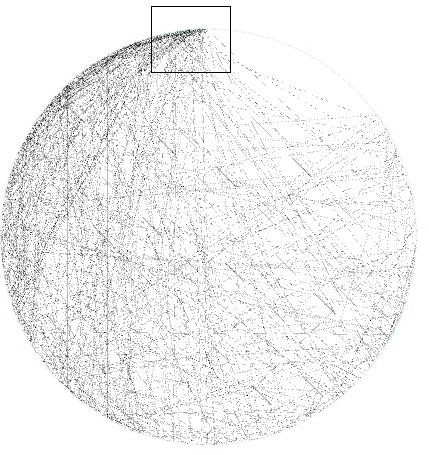
1% de los Usuarios con mayor centralidad de grado de Buenos Aires.
Ilustración 31
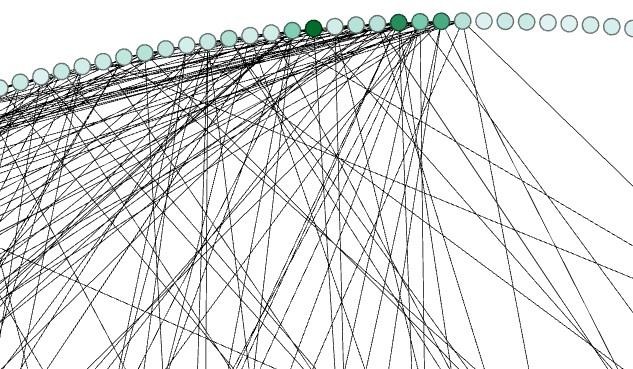
Ampliación del recuadro de la Ilustración 32. Los usuarios con mayor gradiente de color presentan mayor Centralidad de Intermediación.
Al volcar los datos en los programas adecuados para el procesamiento de los sistemas relacionales de nodos obtuvimos una primera dificultad que ya mencionamos para la confección de los grafos, a saber: la insuficiente capacidad de cálculo para integrar la totalidad de la muestra, debido a la conocida propiedad nética según la cual mientras la cantidad de nodos aumenta en forma lineal, la de enlaces entre estos lo hace exponencialmente de acuerdo a un factor específico, ya que hipotéticamente cada nuevo nodo puede agregar tantos vínculos como nodos preexistentes tenga la muestra.
Sin embargo esta dificultad fue menor, ya que nuestra hipótesis principal se propone que la centralidad de grado puede relacionarse con la distribución de las geolocalizaciones urbanas, por lo tanto trabajamos desde entonces con muestras seleccionadas por ciudad, siendo la ciudad de usuario aquella en la que el usuario se definía en su perfil y no su último check-in su geolocalización.
Por lo tanto la primera visualización de la ciudad de Buenos Aires que ofrecemos abajo no tiene mucho que aportar, excepto como ejemplo de lo complicado que puede llegar a ser desenredar la madeja de datos disponibles.
Ilustración 32
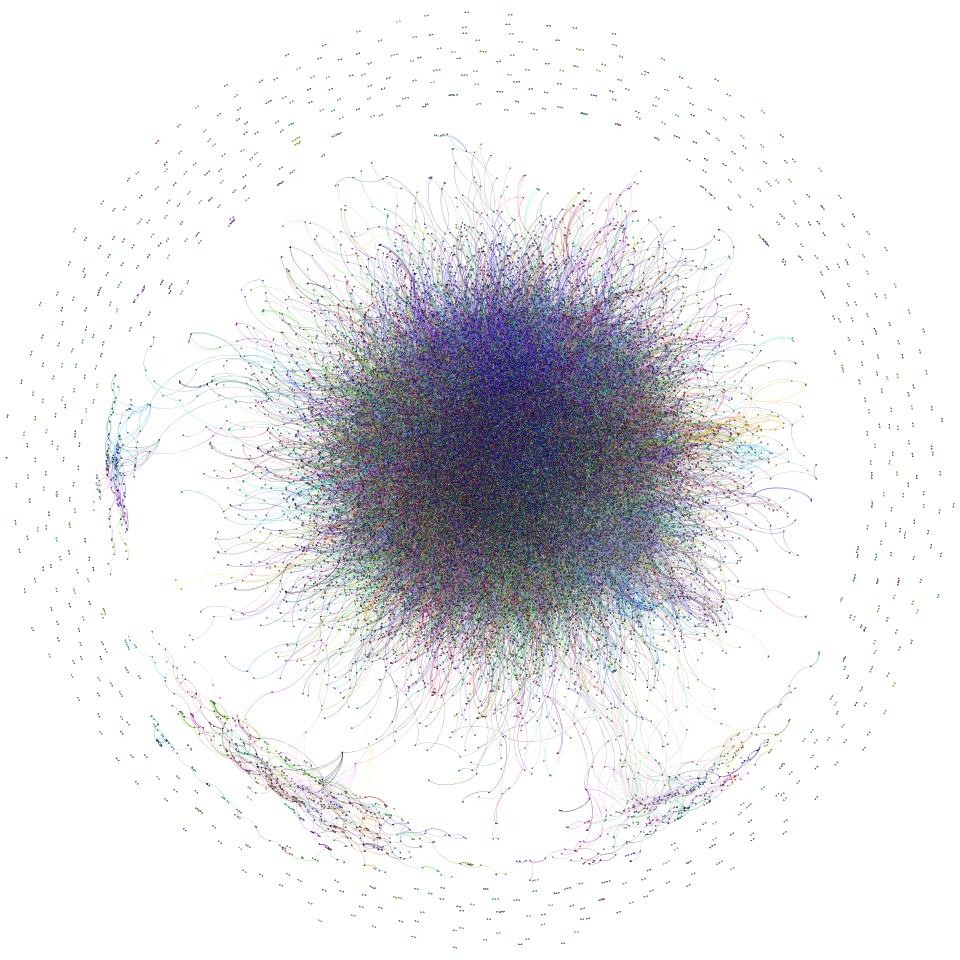
Totalidad de usuarios de 4SQ®, recolectados de Buenos Aires.
¿Qué observamos? Se trata de los usuarios coloreados con el algoritmo de agrupamiento Chinese Whisper, desplegados luego por el algoritmo Force Atlas. Ante todo descubrimos un gran agrupamiento centro, especie de imagen estelar, donde las fuerzas centrífugas de atracción han atraído a los usuarios más conectados entre sí, alejando de ese centro a los usuarios desconectados o escasamente enlazados con ese núcleo.
Dentro de este Sol central de nodos, rodeado de una especie de cinturón de nodos asteroides, se reconocen dos grandes subnúcleos, uno de ellos pareciera ser mayor que otros. Hay que aclarar que no se trata de una representación 3D, es decir que los nodos que podría imaginarse atrás de la imagen en realidad han sido desplazados hacia los costados del núcleo.
Luego observamos tres agrupamientos genéricos en el área circundante, entre los asteroides. Si imaginamos una información circulando en este sistema rápidamente comprenderemos que cualquier cosa que ingrese en el núcleo terminará más o menos velozmente difundiéndose por el resto de los usuarios, en cambio en caso de ingresar por un planetoide externo deberemos esperar una tardanza formal hasta inundar todo el sistema.
Desde el punto de vista metodológico el procedimiento de visualización es relativamente simple, sin embargo al momento de realizar la visualización y con el hardware disponible este proceso demandaba aproximadamente 3-4 días de procesamiento indetenido.
Por lo tanto es fácil de comprender que para operaciones más complejas el procesamiento de los datos de red necesariamente requerían en nuestro caso de menos usuarios y nodos, por lo que avanzamos sobre la extracción de los menos conectados.
El proceso se puede ver en la figura de abajo, donde progresivas eliminaciones de usuarios van seleccionado los usuarios clave.
Ilustración 33
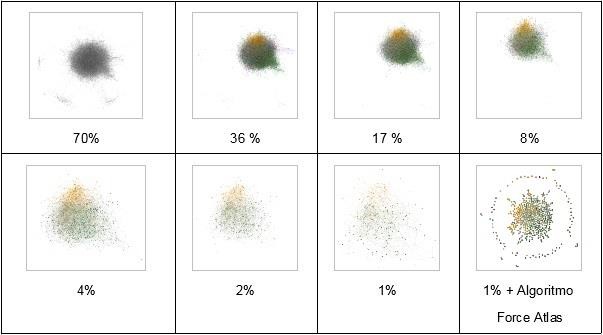
Esquema en el que se representan las visualizaciones con grados decrecientes de los usuarios de Bs As, basadas en Chinese Whisper, expresadas en porcentajes. El Algortimo Force Atlas se utilizó para visualizar desolapados la configuración de la élite más conectada.
Puede verse que a medida que se avanza en el descremado se mantiene aquella diferenciación de dos subnúcleos estructurales en el centro de la configuración, que persisten hasta la selección del 1% de nodos hubs. Son nodos que funcionan generalmente como la parte visible del iceberg de conexiones, que independientemente del tamaño de la submuestra que caracterizan estas redes, hacen que las propiedades se puedan extrapolar hacia otras escalas de la red.
Se trata de usuarios muchos más enlazados que el resto, cuyos vínculos fueron registrados por redundancia (amigos que volvían a encontrarlos como amigos), lo que significa además que existe un sesgo muestral, porque para que exista esa posibilidad deberían ser amigos próximos en anillos del usuario semilla.
Hecha esta aclaración y a los efectos de progresar en nuestra investigación vamos ahora a analizar a los nodos más conectados, así como el sistema que los integra. En la imagen que sigue se ilustran los usuarios más conectados de Barcelona. Al compararlos con las visualizaciones de Buenos Aires se puede observar que acá también tenemos usuarios con diferentes grados de centralidad, pero que no necesariamente esa propiedad se repite dentro del grupo élite. Es decir: vemos usuarios muy conectados en la red general de la ciudad, pero que ocupan posiciones marginales en la red formada solamente por los usuarios más conectados.
Ilustración 34
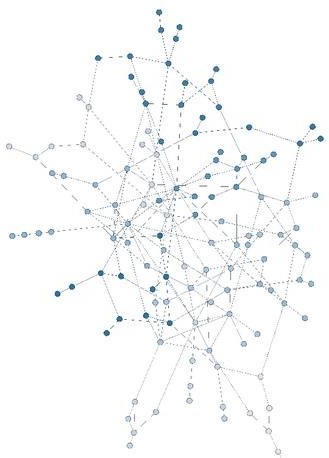
Usuarios más conectados de Barcelona. El gradiente aumenta con el grado de centralidad de cada nodo.
Para poder expresarnos adecuadamente generamos la ilustración que se puede ver abajo.
Ilustración 35
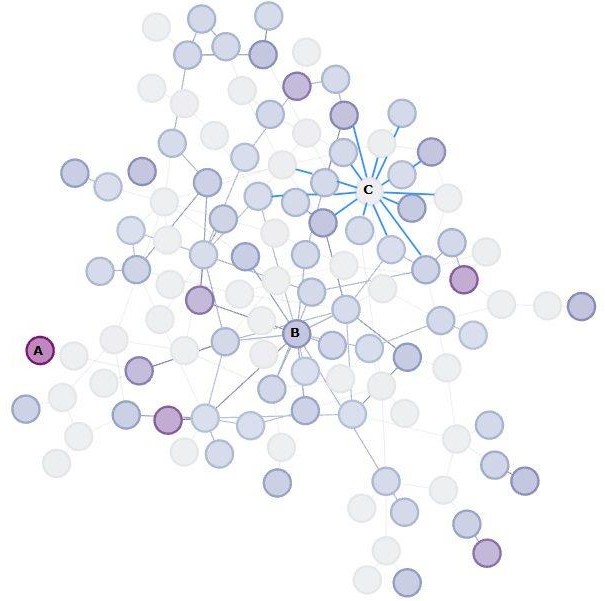
Configuración de vínculos de los usuarios con mayor grado de centralidad de Buenos Aires. El incremento de la intensidad de color se corresponde con el grado en los que se ve tres nodos que se usaran para su comprensión. Se señalan los nodos (A), (B) y (C) que se describen en el texto.
Observar con más detalle la topología de los nodos más conectados nos deja ver algunas cuestiones a resaltar, a saber: (A) es el usuario de mayor centralidad de grado, pero está pobremente conectado con la cúspide de los más conectados, (B) en cambio tiene una posición relativamente central y figuraría en una especie de segunda línea respecto al grado, en tanto que (C) está muy conectado en la élite, pero su grado general es bastante menor.
Pongamos un ejemplo. Supongamos una oficina central que coordina las acciones de una empresa. Supongamos que en ese sector trabaja el 1% de los empleados, pero son los que reciben la información del entorno (financiera, costos, ventas, decisiones de los accionistas, etc.) y deciden el curso del resto de la red, dada su capacidad de agrupar recursos informacionales a mayor velocidad que el resto dada sus características de nodos hubs. Ahora, si vemos dentro de la oficina, vamos a ver algunos que tienen muchos contactos, pero con los empleados de cuello azul, otros que tienen capacidad de intermediar entre los cuellos blancos de la oficina pero llevan la información hacia los que no están en la oficina, y por último, oficinistas que no tienen muchos contactos con el afuera, pero están intensamente conectados dentro de su grupo y por lo tanto tienen mayores probabilidades de participar en el reclutamiento de información crítica para producir transiciones de fase de estado en la red. El primero, el segundo y el tercero representan a los usuarios (A), (B) y (C).
Estas observaciones son claves para detectar sobre qué usuarios deberían hacerse intervenciones meméticas para distribuir información. Es evidente que algunos nodos, desde el punto de vista de (A), nos proveerán enlaces que llevarán rápidamente a grandes cantidades de nodos de baja calificación nética un paquete informacional determinado, en cambio (C), a pesar de su menor popularidad general, nos daría acceso rápidamente a los de la élite más conectada entre sí.
Por otro lado hay que considerar los restos flotantes de nodos aislados que se recolectan cuando se seleccionan a los más conectados. Muchas veces aparecen nodos con alto grado, y en otros islotes de usuarios que deben ser mesurados, porque son usuarios que van a difundir información a vastos sectores de la red.
Hasta acá podemos ver cierta auto-organización esperable en las redes en las que predomina la interacción entre los nodos, de modo que cada uno actúa según sus expectativas y las de los otros nodos. En la ilustración que sigue se visualiza un conjunto de nodos de la élite, pero que se encuentran aislados del centro general.
Ilustración 36
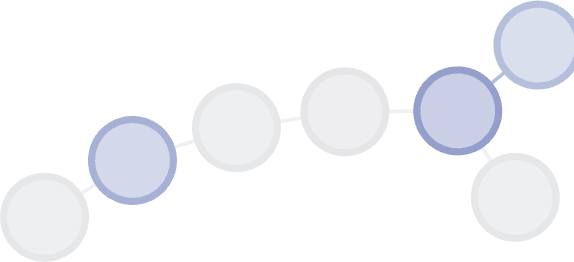
Ejemplo de islote de usuarios más conectados. 4SQ® Buenos Aires. El gradiente de color informa de la centralidad e grado de cada uno.
Puede verse que en los islotes se reproduce la situación descripta para el núcleo de individuos más y mejor conectados en la élite de la red. Uno de los lazos tiene tres enlaces y el mayor grado; tres usuarios, dos enlaces; y tres usuarios una sola relación dentro del grado. Debe considerarse que el gradiente de color informa sobre la capacidad de conexión de cada usuario con los usuarios de menor grado. En el caso de estos usuarios se trataría del 99 % de los usuarios de la ciudad.
Es de interés para esta tesis señalar que si quisiéramos producir cambios en esta estructura deberíamos tomar alguna decisión de intervención: o bien estimular algunos nodos con información nueva, o bien modificar las relaciones entre ellos, creando nuevas (por ejemplo integrando a la élite al nodo poco conectado en la cúspide) o destruyendo otras (por ejemplo aislando a los nodos de baja calidad estructural).
Sin embargo debe tenerse en cuanta que por fenómenos de auto-organización estas redes producen enlaces en los procesos de búsqueda, por lo tanto redes y nodos deberían ser comprendidos como elementos en definitiva intercambiables, como puede metaforizarse que sucede entre la masa y la energía en la física. Dicho de otro modo los procesos dinámicos de red producen relaciones de amistad y la aparición de nuevos usuarios, en u fenómeno que de producirse es trascendente a las intenciones locales de los usuarios.
El análisis del cambio estructural, entonces, es mucho más rico visto así que mediante los estudios ortodoxos basados en promedios, ya que se pueden hacer acciones a nivel local y predecir la consecuencia de esas acciones con modelado computacional.
Al mismo tiempo, si quisiéramos utilizar la red con el fin por ejemplo de difundir una novedad informacional, sería imprescindible que los usuarios mejor conectados fueran intervenidos, de hecho hemos podido, en este ejemplo, seleccionar un pequeño grupo de nodos con uno clave entre ellos (A) con capacidad de reducir en muy pocos pasos la modularidad de la red y consecuentemente distribuir exponencialmente información.
Ilustración 37
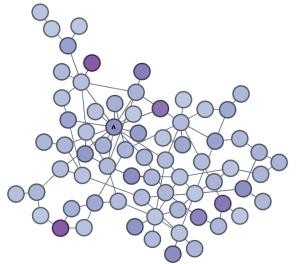
El usuario (A) podría ser el más significativo funcionalmente entre el total de usuarios recolectados de Buenos Aires, del total de usuarios mundiales recolectados en la muestra.
En la próxima visualización se aísla al usuario clave de Buenos Aires. Podemos ver rápidamente que no se trata de un individuo que permanezca al grupo de los de mayor grado en la élite, sin embargo evidentemente tiene la capacidad de reclutar usuarios importantes al momento de hacer circular un paquete informacional en la red de la ciudad.
Ilustración 38
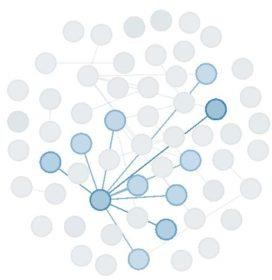
Visualización del usuario mejor conectado de toda la muestra.
Despejados los nodos con menor centralidad e intermediación podemos visualizar un grupo de usuarios que conectan a otros grupos de usuarios. Dentro de ellos se visualiza un usuario capaz de recolectar y distribuir información a 10 de los usuarios mejor integrados, de a su vez las seis decenas de usuarios con mayor centralidad de intermediación.
Lo específico de esta presentación es la búsqueda de patrones a partir de hubs sociales basados en grados. Para eso trabajamos filtrando los usuarios más conectados por grado de intermediación.
Hagamos un breve repaso en este punto antes de seguir avanzando. Al realizar las visualizaciones a partir de los datos obtenidos observamos que los nodos tienden a organizarse en clústers o grumos, que a su vez se conectan en otros clústers mayores y así hasta establecer una configuración global para cada ciudad o región estudiada.
Vemos a cada nodo en una configuración enlazada por nodos claves, nodos-hubs, que clásicamente se consideran que son los que permiten que la información se mueva de grumos en grumo: existe una larga tradición para visualizarlas, que en los últimos 20 años ha tenido una aceleración significativa, gracias al poder de cómputo aplicado al diseño en pantalla.
Las novedades informacionales en una comunidad urbana suelen requerir refuerzos por múltiples contactos sociales (por ejemplo, el célebre experimento de la acera de Milgram, cuanta más gente mire hacia arriba, más gente probablemente mirará), por lo que se podría conjeturar que un agente expuesto a muchos estímulos diferentes (por ejemplo, bares nuevos) será menos permeable a visitar a alguno de ellos.
En las figuras que siguen se verán a los usuarios de Buenos Aires, procesados por algoritmos de detección de comunidad, basados todos en los mismos nodos caracterizados por corresponder a usuarios definidos en su perfil como de la ciudad de Buenos Aires, pero que pertenecer al grupo con mayor centralidad de centralidad (1% más conectado).
Ilustración 39

Algoritmo Chinese Whispers + Algoritmo Force Atlas 2. Buenos Aires. 1% seleccionado por centralidad de grado (63 clústers).
Como se observa en la figura cada agrupación de nodos tiende a formar un grupo al transmitir la misma información y por lo tanto participa de alguna comunidad. Así es más probable que se difunda una información de las disponibles en Foursquare® (por ejemplo la inauguración de un museo).
Nótese que este grupo se trata de una especie de porción privilegiada en enlaces respecto al resto de la ciudad de Buenos Aires. Si bien existe 63 grumos diferentes, también podemos observar que existe un fenómeno de efecto mateo (Merton, 1968) o ganador se queda con todo, tal como se entiende al observar los nodos de color celeste, amarillos o violeta.
Este algoritmo nos enseña además la importancia de la configuración de una red en la propagación de una innovación, independientemente de las condiciones de ésta: es el proceso estocástico que definimos arriba como de conexión preferencial.
Esto es importante porque si quisiéramos difundir entre los usuarios de 4SQ® de Buenos Aires una idea, sería evidentemente productivo contactar a usuarios de cada una de esas tres agrupaciones que mencionamos.
La probabilidad que se difunda hacia el resto de los usuarios es evidentemente mayor. Expresado esto podemos acercarnos a nuestra segunda hipótesis de este trabajo, pero antes debemos hacer un breve paréntesis que nos ayude a entender otro algoritmo.
En la figura siguiente hemos utilizado el algoritmo de Markov (Leenders, 1995), que se utiliza también para detectar comunidades, basado en el concepto del camino aleatorio, que podríamos describir así: supongamos un caminante que está en un nodo y se mueve a otro en su vecindario de manera aleatoria; la secuencia que se produce es una cadena de Markov, donde los estados siguientes unos de otros se corresponden con los nodos visitados. El algoritmo es útil para evaluar la distribución de grados y la distribución de coeficientes medio de agrupamiento (CMC).
Ilustración 40
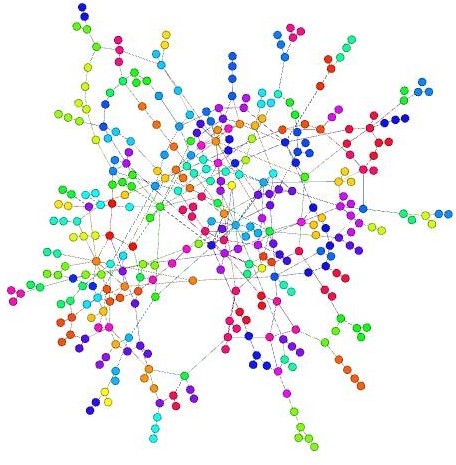
Markov Clustering + Algoritmo Force Atlas 2. Buenos Aires. 1% x centralidad de grado (255 clústers). Se muestran sólo los nodos conectados a la red.
Muchos investigadores han utilizado los modelos de Markov para estudiar la evolución en las redes sociales. Todos hemos tenido la experiencia de sentarnos en los cursos en las mismas posiciones, aun durante cuatrimestres enteros. Las preferencias de los alumnos por sentarse en los mismos bancos podrían ser representadas por un modelo de Markov estacionario y discreto y de ese modo predecir comportamientos de compañeros y el estatus de amistad.
El algoritmo bayesiano Markov es productivo para evaluar probabilidades marginales de eventos. ¿Qué sucede si cambiamos las posiciones de los bancos de un curso? ¿Qué sucede si algunos alumnos cambian sus posiciones al azar obligando a otros a reubicarse?
Haciendo predicciones en series heterogéneas de clústeres, la hipótesis básica subyacente a la teoría que sostiene el algoritmo de Markov es que sólo se necesita conocer el estado actual del sistema para predecir un estado futuro. Es decir: toda la información relevante del pasado se supone que se incluye en el presente y de ese modo con información mínima se pueden clasificar redes sociales.
En el caso de nuestra red podemos observar agrupamientos de nodos que nos habilitan algunas afirmaciones:
- El algoritmo de Markov (como otras propiedades de red) puede ser aplicado a nuestra muestra, con lo que se confirma nuestra primera hipótesis.
- Los grupos que selecciona este algoritmo son los que regulan la estabilidad de la estructura temporal, lo que indirectamente nos ayuda a aprobar nuestra segunda hipótesis que dice que un grupo de usuarios de alto conexionado correlaciona con la estructuración de la red
- La distribución de enlaces de nodos rankeados por el algoritmo (pocos muy conectados, muchos menos conectados) nos permiten afirmar la existencia de una power law, es decir que la configuración surge de un sistema de interacciones en el tiempo y por lo tanto la probabilidad de que se trate de un sistema con mayor resiliencia que otro exclusivamente azaroso.
Por último analizaremos el algoritmo de intermediación aplicado a los mismos usuarios de Buenos Aires del ejemplo anterior. El grado de intermediación (betweenness centrality) es una medida que cuantifica la frecuencia o el número de veces que un nodo actúa como un puente a lo largo del camino más corto entre otros dos nodos. La idea intuitiva es que, seleccionados dos usuarios al azar, y luego también al azar uno de los eventuales posibles caminos más cortos entre ellos, entonces los nodos con mayor intermediación serán aquellos que aparezcan con mayor probabilidad dentro de este camino.
Ilustración 41
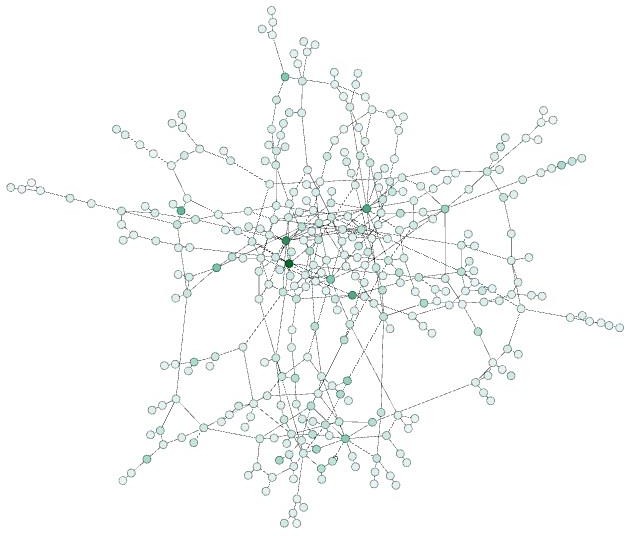
Visualización de nodos con mayor centralidad de grado en Buenos Aires. A su vez los de mayor intensidad de gradiente de color son los que presentan mayor grado de intermediación.
En la ilustración podemos observar un pequeño número de usuarios, una decena aproximadamente, señalados por una coloración más fuerte en verde, que revela su mayor grado de intermediación. Como ya dijimos estos individuos suelen tener un rol crítico en la estructura de la red ya que integran componentes arracimados por lazos cortos en estructuras más extensas, rol que generalmente implica que ocupan roles de reguladores del flujo de información.
Hemos expresado hasta acá los hallazgos realizados en función de los objetivos propuestos por esta tesis. Partiendo de una observación silvestre de la pantalla de nuestro celular, la inquietud nos llevó hasta recolectar decenas de miles de usuarios, filtrarlos y demostrar que pueden ser estudiados siguiendo los procedimientos del Análisis de Redes Sociales.
Luego seleccionamos un pequeño grupo y lo estudiamos de un modo más cercano, describimos propiedades complejas y establecimos que sus estructuras se repiten independientemente de las escalas y los medios que recurren para eso. Esto nos llevó al paso siguiente, que consistió ver dónde estaban nuestros usuarios, es decir su geolocalización.
Topologías territoriales: lo urbano en red
Si aceptamos por un momento que el juego propuesto por 4SQ® consiste en decir dónde se está, desde el momento en que el usuario se ubica en un lugar y que esa información está a disposición de los amigos de la plataforma para que se creen interacciones, de la que surjan luego ganadores, premiados, etc., es evidente entonces que no pueden soslayarse las geolocalizaciones.
Siendo éste el núcleo lúdico y al mismo tiempo el interés principal de la empresa para comercializar los datos que se generan a partir de estas dinámicas, debería ser aquel a que le prestáramos especial atención.
Afirmar esto no excluye la idea que nos anima respecto a que sobre el material recolectado debieran seguir buscándose de patrones de correlación que exceden a esta investigación, que combinarían eventualmente otros atributos de los nodos con geolocalizaciones o agrupamientos atributivos.
Hemos descrito la metodología de recolección de nodos enlaces y sus características, dentro de los cuales incorporamos el último check-in de cada usuario definido por su latitud y longitud.
A continuación, siguiendo la metodología que nos propusimos, se realizaron visualizaciones que expresaran cómo se distribuían estos comportamientos cartográficamente.
Ilustración 42
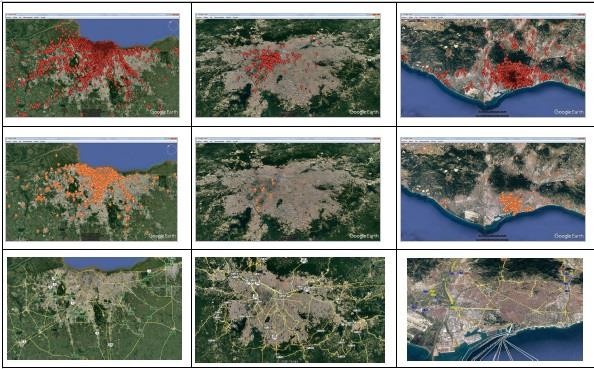
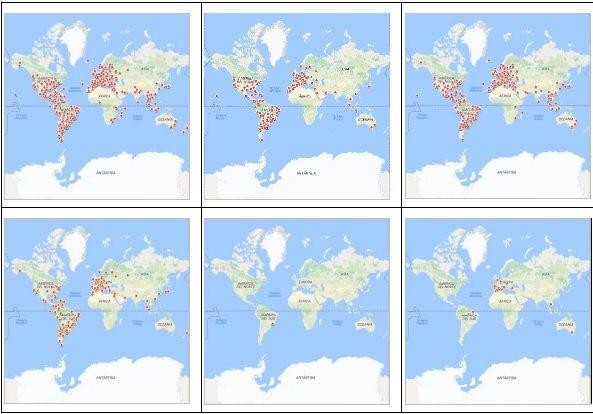
Buenos Aires, San Pablo, Barcelona. Arriba, el totalidad de usuarios geolocalizados. Abajo el 1% con mayor centralidad de grado (más conectados). En la fila de abajo se muestras las principales vías de comunicación urbana. Map data ©2017 Google.
En las figuras de la ilustración de arriba podemos observar los check-ins de los usuarios que, teniendo su perfil declarado en la ciudad referenciada, hicieron su última geolocalización en algún punto de la ciudad. Se puede reconocer que se verifican los fenómenos de fragmentación y descentralización que se han descrito para otras ciudades en los que se realizaron indagaciones semejantes, tal como se citó en los antecedentes y el estado del arte.
La ilustración nos muestra tres columnas y tres filas. En la fila superior se han cargado las geolocalizaciones en rojo de la totalidad de los usuarios de las tres grandes ciudades estudiadas: Buenos Aires, San Pablo y Barcelona. La cantidad de nodos hizo que fuera insalvable evitar solapamientos de check-ins, por lo que además de agregados deben suponerse muchos más usuarios donde a su vez se encuentran más arracimados. Independientemente de las estructuras urbanas propias de estas tres urbes, una vista a vuelo de pájaro nos permite detectar en cada ciudad un archipiélago de nodos con islas de diferente tamaño, que siguen aproximadamente una distribución power law de superficies, con unas pocas zonas intensamente coloreadas y una mayoría con una baja tasa de check-ins. En Buenos Aires, la primera ciudad a la izquierda, puede reconocerse un núcleo superior y central y líneas de check-ins que lo surcan desde y hacia sí, y que se pueden reconocer como las vías de conexión de la ciudad. Son la autopista Panamericana y las rutas 8, 7, 3 y 2, que hemos publicado en la tercera fila. En la figura intermedia, con los check-ins en color anaranjado, pueden reconocerse las mismas formas, que sin embargo representan solo al 1% de los usuarios mostrados en la fila de arriba.
Si repetimos la evaluación urbana en San Pablo, la ciudad mostrada en la columna central, reconocemos características similares: otra vez un centro alrededor del cual existe una dispersión en líneas tenues de geolocalizaciones. Nuevamente, si hacemos un salto hacia la tercera fila, vemos los anillos de caminos que apuntan hacia ese centro y lo integran al resto de la cartografía, y otra vez reconocemos al grupo de mayor grado de centralidad ocupando las mismas zonas.
Cuando vamos a las imágenes de Barcelona encontramos que en la primera de las filas, la que muestra la totalidad de usuarios recolectados, nuevamente aparece un centro significativo en lo que correspondería al centro urbano, que a diferencia de Buenos Aires se encuentra algo alejado de la costa. Sin embargo encontramos la misma dispersión en archipiélagos de islotes con distribución power law de superficies, la cual es más notable en el mapa de todos los usuarios que en la de los más conectados. Tambien encontramos las vías de comunicación principales rodeando y envolviendo al centro, e integrándolo con el resto de la cartografía.
Una descripción resumida nos permite sugerir una interpretación según la cual se puede reconocer que ambos mapas (el correspondiente a todos los usuarios, en rojo, y al del 1% más conectados, en naranja) tienen una patrón de distribución semejante, en el que se reconocen el centro de la ciudad y las principales vías de acceso al mismo.
Para la misma época hicimos una toma de muestra de geolocalizaciones de tweets en la ciudad de Buenos Aires, de modo que nos sirviera de comparación y control, y que puede verse en las imágenes de abajo.
Ilustración 43

Usuario de Twitter en enero de 2014. Geolocalizaciones. Android, IOS y Blackberry. © Colaboradores de OpenStreetMap. Dirigirse a openstreetmap.org.
En este caso se discriminaron los tweets según fueran realizados con sistemas con sistema Android, iOS (correspondiente a equipos Apple®) o Blackberry®. En este caso tambien puede reconocerse un núcleo, más notable para los usuarios de iPhone, que se han mantenido predominantemente en el área nuclear más abigarrado de la ciudad, con tendencia al norte acuático. Los otros grupos en los que se puede observar una menos especificidad es en el de los usuarios de Blackberry®, y quizás una explicación entre tantas sea la prácticamente desaparición de estos equipos en el mercado en pocos años.
En términos generales, ambas plataformas (4SQ® y Twitter®) comparten sitios de geolocalización y curvas de distribución de superficies.
Cuando repetimos el procedimiento en la superficie de la Argentina pudimos reconocer cómo el patrón de check-ins se extiende conservando características que podríamos conjeturar libres de escala hacia el norte, destacándose en la figura los conglomerados en las ciudades de Rosario y Córdoba que describiremos más abajo.
Ilustración 44
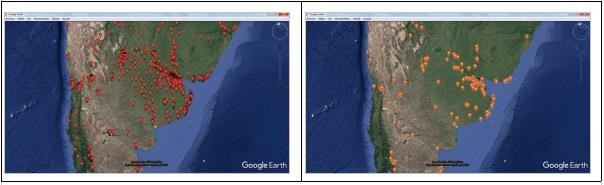
Argentina región centro. Usuarios totales y con mayor centralidad de grado (1%). Map data ©2017 Google.
Cuando repetimos el descremado de usuarios en otras metrópolis obtuvimos resultados dispares, posiblemente debido a factores relacionados también con el método de bola de nieve para obtener los datos.
Cuando extendimos el modelado de mapas a nivel planetario obtuvimos las ilustraciones que se ven a continuación.
Ilustración 45
Buenos aires, San pablo y Barcelona. Check-ins de usuarios totales y con mayor centralidad de grado (1%). Map data ©2017 Google.
En la fila superior se pueden ver los usuarios generales y en la inferior los más conectados por grado. Hemos colocado a los usuarios siguiendo el mismo orden que en la ilustración, anterior de modo que los últimos check-ins de usuarios de las ciudades de Buenos Aires, San Pablo y Barcelona pueden verse en rojo y anaranjado.
Lo primero que llama al análisis es la semejanza estructural: los usuarios de 4SQ® de estas ciudades tienen un comportamiento occidental urbano, repartiendo sus geolocalizaciones de un modo estructuralmente semejante. Reconocemos así mismo una predominancia leve de cada ciudad (los usuarios de Buenos Aires aparecen más geolocalizadas en su ciudad y así sucesivamente con las otras ciudades).
Cuando realizamos el mapa de las geolocalizaciones mundiales de los usuarios de Rosario y Córdoba no encontramos diferencias significativas en el patrón de check-ins de las grandes ciudades. Esto se puede explicar entre otras causas por el tipo de perfil de usuario de la plataforma al momento de la recolección de la muestra.
Ilustración 46
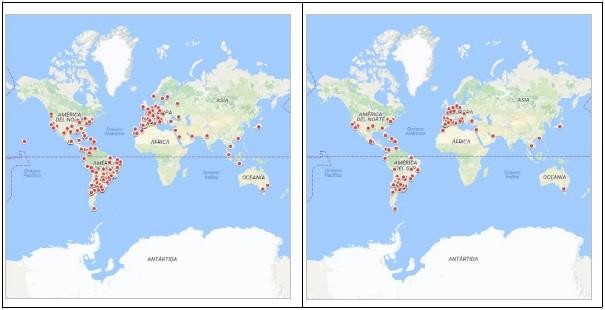
Usuario de Rosario y Córdoba. Check-ins globales. Map data ©2017 Google.
Nos propusimos obtener una forma de gráfica que resumiera los hallazgos, y que se expresaran mediante patrones sintéticos sin pérdida de información. Así se podría trabajar en una posible taxonomía de ciudades de un modo autónomo de las variables geográficas clásicas.
Utilizamos para eso el método de grilla o malla por ciudad, para crear las huellas “dactilares” de cada urbe y sus check-ins. A tal fin utilizamos el programa ArcGIS 10, con el objetivo de simplificar las observaciones de los mapas y facilitar su clasificación, simbolización e inducción de interpretaciones, tal como se puede ver en las figuras de abajo (Bugayevskiy y Snyder, 1995).
Ilustración 47
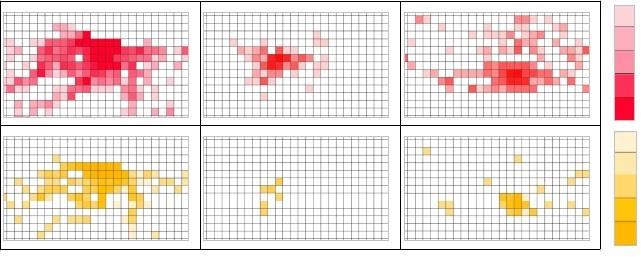
Grilla de usuarios totales y de la elite con mayor centralidad de grado. Buenos aires, San Pablo y Barcelona. Se usó un gradiente de 5 colores, donde el gradiente de colores expresa la cantidad de check-ins incrementados por unidad, salvo en el último que expresa 5 o más.
Ilustración 48
Buenos Aires, San Pablo, Barcelona. Selección aleatoria de usuarios (1%) y su ubicación. Map data ©2017 Google.
Por últimos hicimos pruebas de control con usuarios elegidos al azar de las tres ciudades investigadas, y encontramos un patrón de geolocalización semejante (es de esperar por la propiedad libre de escala) aunque con mayor dispersión, probablemente porque los usuarios menos conectados tengan mayores probabilidades de adoptar comportamientos alternativos.
Centroides y ciudades
La cuestión que sigue es parte de un proceso en curso. Hemos decidido colocarlo acá para poder agrupar y evitar dificultades en la explicación de un tema frágil conceptualmente.
Un centroide es un punto que define el centro geométrico de una figura, un objeto tridimensional o de un mapa. Su localización puede determinarse a partir de fórmulas semejantes a las utilizadas para determinar el centro de gravedad o el centro de masa del cuerpo.
Las topologías de áreas geográficas constan de centroides y secciones del mapa delimitadas por perímetros poligonales dentro de los cuales se mantiene una misma característica, que varían según el interés de la investigación. La geografía ha establecido centroides urbanos basados en geometría y en actividades específicas, que son puntos de las ciudades referenciales, que funcionan como “centros de gravedad” alrededor de una variable determinada, por ejemplo distancias al subte o a un hospital.
Para cada interés se puede establecer a un centroide propio de la cartografía estudiada o utilizar centroides básicos establecidos a partir de variables geométricas respecto a los bordes formales de las ciudades realizados en investigaciones precedentes. Los centroides sirven para conjeturar fuerzas centrípetas y centrífugas y las tensiones asociables a dichas fuerzas.
Por ejemplo el centroide puede referirse al área dentro de la cual se mantiene un mínimo de distancia respecto a una estación de subterráneo o el punto alrededor del cual se incluyen a todos los bares de una ciudad.
Ilustración 49
Esquema en que se representan dos Centroides y sus perímetros.
Uno de nuestros objetivos fue evaluar la posibilidad de crear articulaciones entre topologías vinculares y territorializaciones, que pueden ser también expresadas en términos de topologías geográficas, siendo las topografías geográficas sistemas integrados de áreas.
Nos propusimos determinar los centroides de cada ciudad y sus dispersiones de acuerdo a los check-ins de los usuarios, basadas en los nodos claves, antes que en la totalidad de los usuarios. Así nos preguntamos: ¿Cuáles serían las ventajas de este procedimiento? Evidentemente la economía de procesamiento de información es un argumento significativo, pero insuficiente. Lo que debería caracterizar a un área de la ciudad con un centroide es que dentro de la superficie delimitada por su perímetro se encuentran las mismas características. Entonces: ¿Qué sucedería si esas propiedades requeridas son aportadas por alguna propiedad de grafo, por ejemplo los individuos integrantes de un clúster delimitado por un nodo con una centralidad de grado predefinida y significativa? Este argumento nos permitiría establecer un punto en la ciudad alrededor del cual se encuentren los principales usuarios, topológicamente hablando, que realicen un determinado consumo cultural, por ejemplo ser aficionados a visitar museos.
El cálculo de distancia al punto arbitrario del kilómetro cero no es suficiente para determinar la densidad de check-ins en ciertas áreas de casa ciudad. Este método tenía un problema, y era que no existe un modo fehaciente de determinar cuál es el centroide real de cada ciudad, porque nunca se podía determinar solo con distancias, una función matemática o un coeficiente. Tampoco permitía comparar entre ciudades los presumibles puntos centroide reales.
De modo que tenía que existir un punto centroide, que atraiga, por así decirlo, los check-ins de cada ciudad, y este punto debía tener características especiales. Como por ejemplo, imagínese un punto cercano a museos, o vecindarios, o universidades o comercios.
El centroide debe tener una explicación viable desde el punto de vista social, económico, filosófico más allá de lo geográfico únicamente.
En el cálculo de distancias, no se podía determinar cuál era el centroide real. Por esta razón, y por la dificultad para graficar de modo correcto las aglomeraciones de check-ins, se descartó este método y comenzó la búsqueda de uno nuevo.
De este modo, con las matrices ya existentes de latitud y longitud, se generó un nuevo procesamiento de datos. Tenía que existir un modo de determinar un centroide real, y lo que es más importante aún, tiene que existir un modo de comparar matemáticamente los centroides de diferentes ciudades. Para poder descubrir qué situaciones o circunstancias generan un centroide, o lo que subyace detrás de cada centroide.
El nuevo método utilizado, consiste en determinar, mediante un coeficiente y una fórmula, la función correspondiente a la tendencia. La tendencia es la función que parece representar mejor hacia qué lugar del eje cartesiano se aglomeran los puntos de latitud y longitud de cada check in.
De esta forma, se puede determinar qué función y coeficiente corresponde a cada ciudad, y compararlos con otros coeficientes y funciones de otras ciudades. Y lo más importante, la hipótesis de que el centroide real observado en el mapa quizá sea un punto en la recta de la función de tendencia.
La fórmula de tendencia es una ecuación de regresión lineal y se define como la ecuación y=m*x+b, donde m = PENDIENTE(Dato_Y;Dato_X) y b = INTERSECCIÓN.EJE(Datos_Y ;Datos_X).
Calcula el coeficiente de una determinación por r2 = RSQ(Data_Y;Data_X).
Este cálculo es automático en Libreoffice y Excel. Se determina el coeficiente r² y luego la función y=m*x+b, y se representa gráficamente en los diagramas de la herramienta.
Los valores obtenidos se visualizan en las ilustraciones de abajo, en las que se presentan los gráficos por ciudad, que se deben interpretar así: cada punto azul representa una latitud y longitud en ejes cartesianos, y la línea es la función de tendencia, junto con el coeficiente que se determina al calcularla. Se trata de un trabajo en proceso aún. A continuación se pueden visualizar los avances en el cálculo:
Ilustración 50
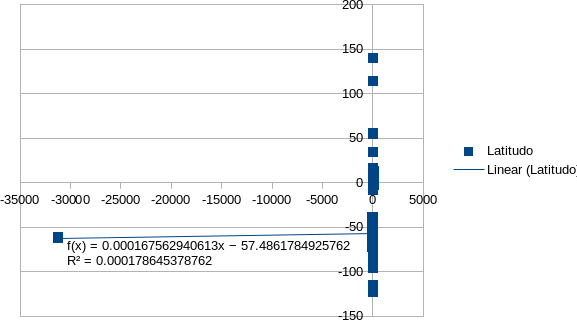
Cálculo del centroide para Buenos Aires, 1 % con mayor centralidad de grado.
Ilustración 51
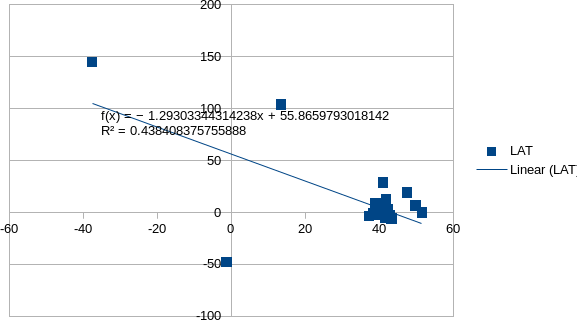
Cálculo del centroide para Barcelona, 1 % con mayor centralidad de grado.
Ilustración 52
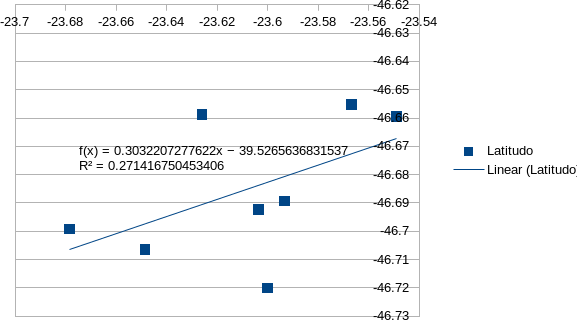
Cálculo del centroide para San Pablo, 1 % con mayor centralidad de grado.
Ilustración 53
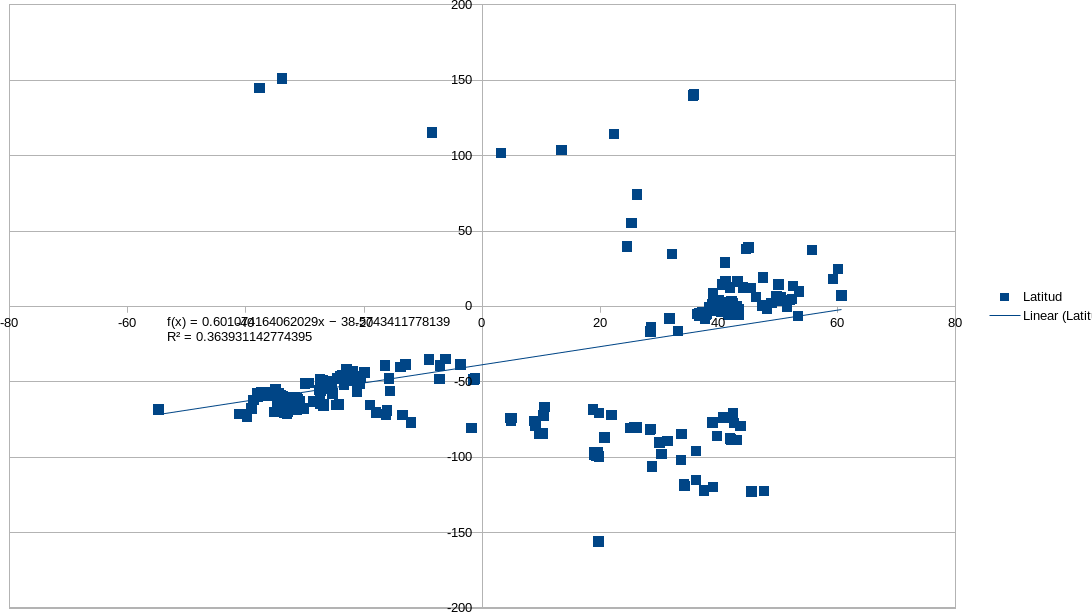
Cálculo del centroide para Rosario, todos los usuarios.
Encuesta contextualizadora
A continuación se expresan los valores obtenidos a cada pregunta del cuestionario web y la interpretación correspondiente que, reiteramos, se expresan en términos de aporte al contexto interpretativo y sobre las cuales no se pueden establecer fielmente una probabilidad, sino simplemente elementos factoriales generales. Vamos a expresar los resultados en el orden tal como fueron obtenidos no obstante los podemos agrupar en tres grupos temáticos de preguntas.
Debemos hacer mención a un problema que no se logró resolver a tiempo y que influye en la calidad que expondremos, y que se refiere al tópico “no sabe no contesta” que figuraba en las opciones para responder. Lamentablemente el sistema agrupó por error de codificación todos los “no sabe no contesta” en un único archivo de texto, imposible de desagregar, lo que agrega un sesgo significativo.
No obstante ponemos los resultados a disposición para que sirvan de material de contextualización.
La primera parte de la encuesta apuntó a explorar los modos de usos propuestos y de apropiación de Foursquare por los entrevistados, luego se abordó la relación con otras plataformas y otros medios, para terminar con la construcción de los perfiles de los respondentes.
En la primera pregunta solicitamos que se puntuara de 1 a 5 el uso que el usuario le daba a Foursquare®, siendo 1 lo mínimo y 5 lo máximo, tal como se puede ver en la ilustración de abajo. De acuerdo a lo que observamos en los resultados referidos a la tabla que se muestra abajo pudimos encontrar que los usuarios prefieren, puestos a evaluar alternativas de uso, la dimensión de espectador antes que la de actuante en la plataforma. Es probable que esta disposición cognitiva tenga alguna relación con los procesos de comprensión de 4SQ®. Es decir: ¿Cómo se juega este juego? Es posible que los individuos se vean impulsados a poner en paralelo sus comportamientos con los de los usuarios más activos, con más contactos y con más tiempo en la plataforma. Si bien no es un único elemento, nos ayuda a comprender los motivos del enlace preferencial que hemos mencionado en los antecedentes y estado del arte. Esto nos lleva a una segunda hipótesis interpretativa del contexto de la investigación referida, al modo de apropiación lúdico, expectante, al predominio de la función agonística y de simulacro de acuerdo a las tipologías de juegos descriptas arriba. Los usuarios eligen ver antes que mostrarse y explorar las condiciones de participación, mediante búsquedas, consultas de otros usuarios y lugares.
Ilustración 54
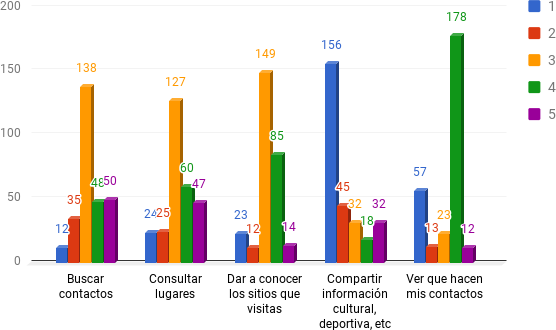
Se representa las respuestas a la pregunta “Puntúa de 1 a 5 el uso que le das a Foursquare” siendo 1 el uso mínimo y 5 el máximo. Se expresan los valores absolutos obtenidos.
En la pregunta siguiente se apuntó a tener más pistas sobre la faceta actual, entendida como la agencia del usuario, con la intención de comprender las motivaciones de actuación del usuario. Paradójicamente, cuando se excluían las motivaciones referidas a la observación de los otros y el relevamiento de recursos de participación que habíamos escaneado en la pregunta precedente, se obtuvo que el interés del usuario por compartir la propia localización era predominante por encima de los otros intereses, como dar a conocer con quién se estaba compartiendo la geolocalización del check-in.
Ilustración 55
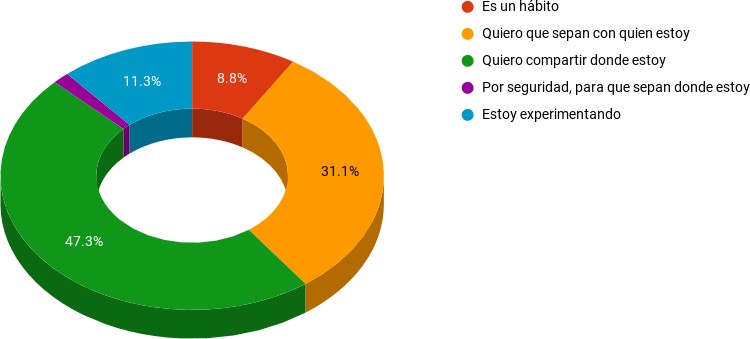
Se representan en porcentajes las respuestas a la pregunta ¿Cuál es la razón principal por la que decides hacer check-in?
Como en la pregunta anterior, las respuestas refuerzan la primera noción de uso de la plataforma para establecer lugares donde compartir experiencias. Respecto a la dimensión lúdica, reconocemos las preocupaciones predominantes del ver y ser visto, del competir y del simular, del expresarse y compartir, es decir, por medio del juego, en su “elevación” lashiana, los jugadores encuentran un objeto transicional de auto y heteroconocimiento.
Cuando seguimos avanzando en este primer paquete de preguntas exploramos el tipo de comportamientos preferidos por los usuarios, que podrían llegar a decidir gracias a la plataforma.
Ilustración 56
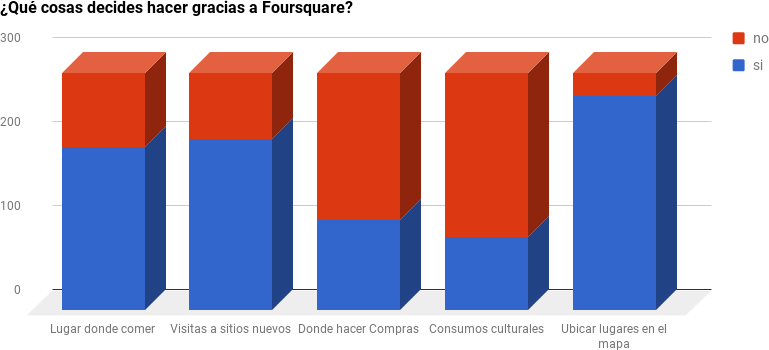
Decisiones tomadas a partir de Foursquare.
Si bien el espectro de opciones seleccionadas como actividad personal gracias a Foursquare® es amplio, se podría proponer que los comportamientos que estarían siendo más decididos son los relacionados a ubicar lugares para conocer. Las respuestas a estas preguntas merecen una descripción más detallada. En primer lugar observemos las dos primeras columnas. En esos casos las respuestas afirmativas superan la media de 180 respuestas, por lo tanto podemos conjeturar la presencia de un conjunto de amenazas en términos de cierta saturación respecto al uso de la plataforma como fuente de novedades respecto a nuevos lugares para actividades culinarias.
Consecuentemente, si observamos con detalle las siguientes dos columnas, viéndolas desde izquierda a derecha, podemos ver que las elecciones de los respondentes se encuentran por debajo de la media, lo que podría constituir una oportunidad: hacer compras y consultar acerca de consumos culturales eran, al momento de la encuestas, tópicos sobre los que la plataforma podía tomar decisiones de comunicación dirigidas a promover el interés de los usuarios y fidelizar otras opciones. Por último es llamativa la quinta columna que responde posiblemente al hecho de que al momento de realizar la entrevista otras plataformas como GoogleMap® o Waze® no se encontraban tan desarrolladas: sabemos ya que la aplicación de Google® fue convirtiéndose en el estándar de ubicación de lugares y determinación de recorridos, así como del estado del tráfico.
En la consulta siguiente se exploró cuánto influía Foursquare® en los comportamientos sondeados arriba. La primera percepción es que la plataforma no era de las primeras fuentes de información, ni la privilegiada, al momento de tomar decisiones con el celular en la mano, al menos en términos generales.
Concretamente a la pregunta sobre cuán influente podía resultar Foursquare®, resultó evidente que se formaron 3 grupos de formas de interés por la plataforma. Las primeras tres columnas representan a una gran mayoría de usuarios que evidentemente no tenían a 4SQ® como una fuente principal, un segundo grupo en formado por las 4 columnas siguientes en las que los usuarios mostraron un tenue interés por las informaciones que podían buscar en Foursquare® y por último un pequeño grupo de usuarios reconocibles en las tres últimas columnas en las que la plataforma resultó atractiva para decidir comportamientos individuales.
Ilustración 57
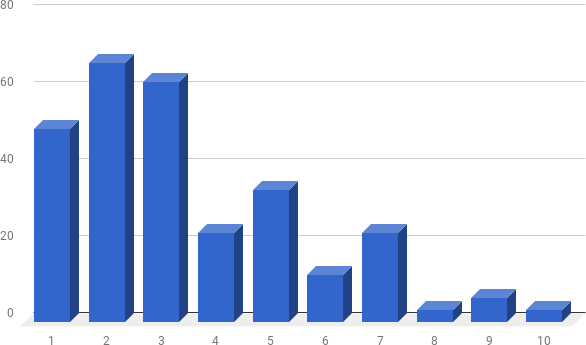
Esquema donde se representa la cantidad de veces entre 10 en las que el usuario tomaba en cuenta información provista por otros usuarios de 4SQ®.
Es probable además que al momento de la toma del cuestionario la plataforma ya no tuviera un impacto significativo en la elección de los sitios a buscar, conocer y con los que compartir experiencias con amigos, algo que se puede relacionar con la consulta siguiente, relacionada con la desinstalación de la aplicación en los celulares de los usuarios.
Cuando le preguntamos si habían desinstalado Foursquare® de su smarthphone encontramos algo que la compañía indudablemente no deseaba: la mayoría de los usuarios habían dejado de usarla. No obstante se puede conjeturar que, por la complejidad de las respuestas que pudieron responder, no era esperable que esta desinstalación fuera muy lejana temporalmente.
Realizamos una búsqueda en el servidor específico Google Trends® para corroborar el desinterés que encontramos hacia la aplicación respecto a las searchs del buscador, y encontramos un desinterés acorde, que se correlaciona con el momento de decisiones de la compañía de desdoblarse en dos servicios diferentes, tal como comentamos arriba. Esta determinación se realizó contabilizando las búsquedas en Google® entre el período que va de enero de 2005 a noviembre de 2016, abarcando todas las regiones del mundo, siendo los países que mostraron mayor interés Turquía, Malasia e Indonesia. Debe tenerse en cuanta que aproximadamente el 25% de las naciones realizan algún tipo de filtrado de las opciones que ofrece Google®, y en especial debe considerarse que en algunas naciones como China, Etiopía, Irán, Turkmenistán, Irak y Vietnam el bloqueo es prácticamente total.
Ilustración 58
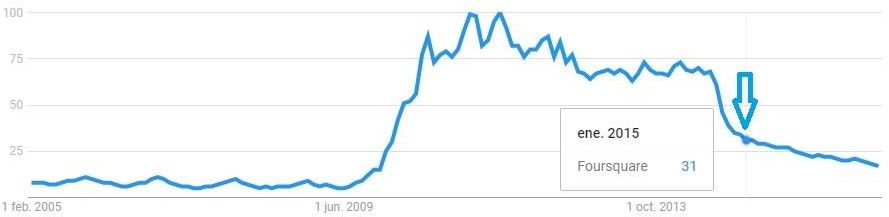
Tendencias de búsqueda de la palabra Foursquare® en el buscador Google. Fuente: Google Trends®.
De acuerdo a esta figura indiciaria, la plataforma no ha registrado recuperación de usuarios desde que tuvo una pérdida logarítmica de usuarios, sin embargo la pérdida se redujo progresivamente hacia fines de 2016.
Cuando preguntamos a nuestros consultados acerca de las motivaciones de la desinstalación de Foursquare de sus celulares la mayoría no realizó comentarios negativos o aversivos sino que se refirió neutralmente al comportamiento declarado. Esto se puede vincular con en el marco de la ecología de aplicaciones de celulares, en la que en la dinámica de interacciones entre plataformas existió un predominio de unas sobre otras, desplazamientos que resultaron en un sistema de ganadores, perdedores y readaptados a nuevos nichos. Es posible que el consumo de recursos de memoria de los celulares y la duplicidad de funciones respecto a un recurso limitado también fuera una motivación, tal como se ha conjeturado para otras aplicaciones desestimadas progresivamente por los usuarios como Tuenti®, Goolge+® o Swype®.
Las opciones de respuesta fueron creadas a partir de las entrevistas exploratorias con usuarios de la plataforma.
Ilustración 59
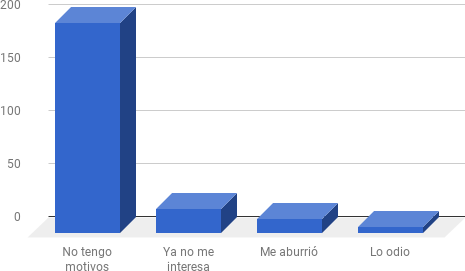
Motivaciones para desintalar la aplicación de los smartphones.
Hacia el año 2015, según informaba la aplicación Yahoo Aviate Launcher®, el usuario promedio de su servicio de optimización de aplicaciones contaba con 95 de éstas instaladas en su celular, de las cuales se utilizaban el 30% en aproximadamente 100 operaciones diarias con el celular.
En nuestras entrevistas exploratorias encontramos que una de las preocupaciones mayores de los usuarios de celulares era la duración de la batería, y algunos expresaron que reduciendo la cantidad de aplicaciones instaladas podrían aumentar la duración de la carga de la misma.
Si bien habíamos sido sorprendidos cuando empezamos a detectar la proliferación de geolocalizaciones en lugares inexistentes nos propusimos dimensionar esta alternativa. Nótese que de acuerdo a la pregunta no se especifica si el usuario se encuentra o no dentro de los parámetros de latitud o longitud que exige la plataforma para ponderar el checkins en término de puntajes dentro del juego.
Detectamos que un porcentaje significativo para nuestras expectativas efectivamente llevaba la curatela de su perfil hacia el punto de simular estar donde no estaba o decir que estaba en un lugar que en realidad era otro. Sin embargo la respuesta es concordante con datos encontrados para otras aplicaciones, como Twitter®, donde aproximadamente el 20-30 % de los usuarios activos son bots o programas de publicación controlados por algoritmos inteligentes o en los foros de chats, donde el mismo porcentaje de cambio de género suele detectarse.
Ilustración 60
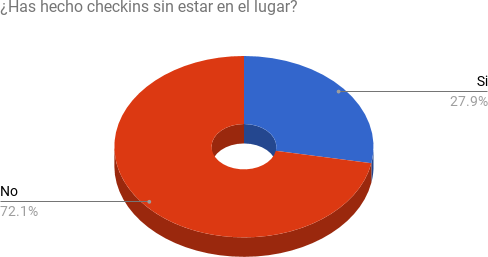
Probabilidad de que el usuario haya realizado una geolocalización falsa.
Conjeturamos que este tipo de actividades, hoy reducidas por la plataforma, tienen su motivación en los aspectos lúdicos de simulacro expresados arriba. Otro aspecto que relevamos fue el relacionado con los aspectos contenidistas y textuales propiamente dichos de Foursquare®, que como dijimos al momento de realizar la encuesta contaba con una página de inicio en la que resaltaba el mapa y la opción de realizar el check-in. Paralelamente el usuario tiende a priorizar los lugares señalados por sus amigos en la plataforma más que lo que comentan, información que contextualmente guarda lógica con lo que hemos señalado respecto a la navegación por imágenes antes que por textos, en superficies de sentido por sobre contenidos más complejos.
Este tópico revela la intensidad del juego más allá de las reglas estipuladas por la plataforma para entregar insignias. Foursquare® no entrega puntos por falsos check-ins. Se puede ver que existe un otro juego, un juego del reconocerse y ser reconocido que emerge en respuestas de este tipo, independientemente que la posibilidad de un error era extremadamente limitada y posible solo en localizaciones contiguas o en dispositivos alejados de las celdas de control establecidas por las empresas de telefonía.
Ilustración 61
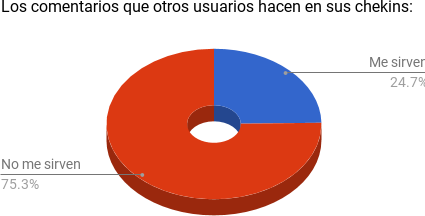
Esquematización de la utilidad percibida de los comentarios de los propios check-ins.
Dado que en la consulta previa habíamos explorado la probabilidad de que un usuario modificara su lugar de geolocalización, en la pregunta siguiente invertimos nuestro interés, buscando sondear cuanto podían interesarle las opiniones que sus acciones provocaran en otros usuarios. Por último hicimos un relevamiento de los perfiles obtenidos en la encuesta, a fin de vincularlos con los obtenidos en la lectura de la API. Resultó evidente que dados los problemas no muestrales obtuvimos perfiles no generalizables, sin embargo resultaron relativamente asimilables a los que recabamos mediante el método bola de nieve desde nuestra semilla en Buenos Aires.
Las figuras de abajo presentan los resultados obtenidos:
Ilustración 62
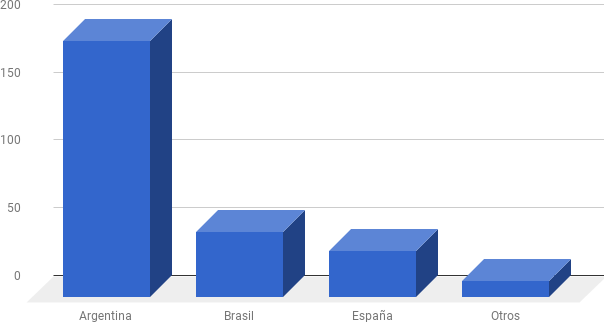
Respuestas por país.
Ilustración 63
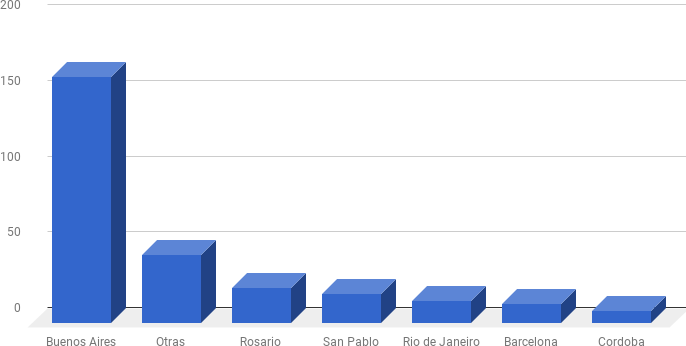
Respuestas por ciudad.
Ilustración 64
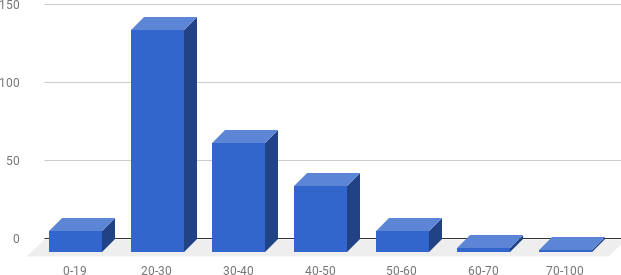
Respuestas por grupo etario.
Ilustración 65
Respuestas por género.
Como conclusión respecto a los perfiles podemos decir que encontramos que existía un predominio leve del género masculino, y el grupo etario entre 20 y 30 años se corresponde con lo hallado en las investigaciones citadas en el estado del arte. Los hallazgos de países y ciudades pueden vincularse aproximadamente con los hallados en la lectura de la API, tal como describiremos en el próximo apartado.
Pruebas de Control
Dijimos arriba que sobre el total de la muestra se seleccionaron 500 usuarios, sin el sesgo por urbe, que habían completado más fielmente su perfil de usuario. Es decir, se seleccionaron del total de la muestra solo los usuarios que de los que se habían obtenido al menos 15 atributos completos, ya sea desde 4SQ® como desde Facebook®. Los resultados luego se anonimizaron y estructuraron. El objetivo fue comparar las muestras para detectar anomalías que pudieran depender de estas localizaciones. Se encontró un núcleo de usuarios alojados en Buenos Aires, determinado porque la probabilidad de que los círculos de amistad alrededor de Mariano Amartino (nuestro usuario semilla) estaba incrementada gracias a que la mayoría de sus amigos en Foursquare compartían su ciudad de perfil, y la mayoría de sus check-ins eran de la ciudad.
Ilustración 66

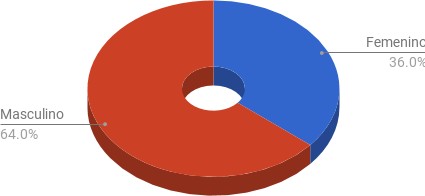
Prueba control. Género de usuarios con mayor cantidad de atributos.
Cuando se relevaron los sexos de la muestra se volvió a encontrar una leve predominancia masculina. El cruce del resto de los atributos sostiene aproximadamente la misma tendencia de correlación entre los usuarios con perfil promedio (la muestra general) y los perfiles más exhaustivamente rellenados por los individuos.
Ilustración 67
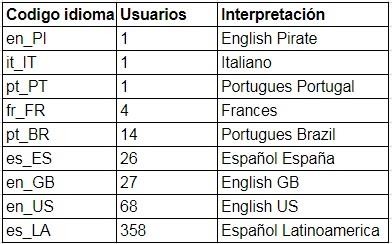
Prueba control: idioma de los usuarios con mayor cantidad de atributos.
Se realizó la detección de idiomas, y en la tabla de la ilustración de arriba se puede ver el predominio de las diferentes variantes del español, además de otros idiomas. Puede notarse rápidamente que la frecuencia de aparición de idiomas de esta muestra de usuario se correlaciona con las muestras sobre las que se trabajó para determinar las propiedades topológicas de las ciudades estudiadas.
Cuando se repitió el procedimiento en las ciudades se obtuvo una desviación no significativa hacia usuarios de la ciudad de Buenos Aires. Los motivos de la aparición de estos datos no son claros, más allá del azar puede deberse al punto donde el programa inició la lectura de usuarios, que al ser el semilla puede haber recolectado más usuarios de su ciudad.
Ilustración 68
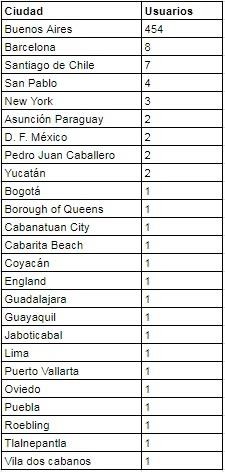
Prueba control: ciudades de los usuarios con mayor cantidad de atributos.
- Consideramos que el Estado Nacional y las Universidades deberían realizar gestiones para que las empresas de redes sociales pongan sus bases de datos, con los recaudos que consideren, a disposición de los investigadores.↵

