





Abordar Foursquare®
En realidad, el primer paso de esta Tesis comenzó antes de diseñar su plan definitivo. Como dijimos, comenzamos a participar como usuarios casi desde el momento inicial en Foursquare® en Argentina, haciendo check-ins, reclutando amigos y viendo sus localizaciones en Facebook®, y aún incluso obteniendo nosotros medallas en el juego, lo que nos permitió conocer ciertos funcionamientos básicos de interacción.
Visualmente el check-in era un elemento significativo al visualizar un usuario amigo, figurando en el mapa resaltado en colores distinguibles sobre el resto de la información provista. Así vimos que los check-ins podrían ser clasificados en su ciudad de origen o fuera de ella. Por ejemplo supimos que los usuarios pueden establecer centenares de relaciones de amistad, pero la API de Foursquare® habilita la lectura de las últimas diez. Establecimos que existían categorías principales para realizar un check-in como sitios para comer o ver espectáculos, y una enorme cantidad de subcategorías tales como Venues, Argentinian Restaurant, Café, Pizza Place, Train Station, Coffee Shop, University, Government Building, Burger Joint, Office, Mall, No category, States & Municipalities, Medical Center, Restaurant, Movie Theater, Plaza, Neighborhood, Ice Cream Shop, Subway, BBQ y otros. Era evidente que los usuarios se limitaban la mayoría de las veces a hacer sólo el check-in. Inclusive, mediante la observación participante, encontramos que lugares a los que accedíamos en la vida cotidiana estaban establecidos por otros usuarios en ubicaciones incorrectas. Algunos por error, otros indudablemente para realizar bromas, como cuando un club figuraba en el sitio de su rival habitual. Descubrimos lugares que no conocíamos y hasta fuimos a visitar otros que figuraban en la plataforma, pero que al llegar ahí no existían en el mundo real. Eso nos llevó a crear la categoría de neolugar, para definir a las ubicaciones en la plataforma, independientemente de la existencia o no en la realidad como se esquematiza en la figura que sigue.
Ilustración 4
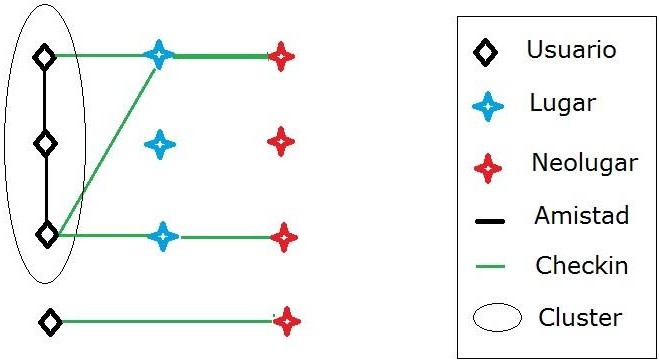
Una de los primeros esquemas con los que abordamos etnográficamente Foursquare®, en los que se relaciona usuarios con sus lugares, neolugares, relaciones de amistad y de geolocalización.
Ya hemos mencionado nuestro acercamiento a los usuarios mediante entrevistas, que fueron repetidas periódicamente y cambiando las preguntas, adaptándolas a la situación evolutiva de la plataforma.
Luego nos propusimos abordar el análisis de redes sociales aplicado a plataformas de redes sociales telemáticas conectables específicamente a Foursquare® y Facebook® y Twitter®, con el objeto de relacionar comportamientos del usuario de acuerdo a la posición topológica en la red. Esto nos obligó a participar observando activamente de ambas redes sociales, describiendo los modos de uso y reapropiación. Las conductas recolectadas fueron tanto las posiciones definidas por los usuarios (espaciales y relacionales) como los atributos que ellos mismos habían dejado registrado en ambas plataformas de redes sociales. Luego hicimos una revisión bibliográfica de esta perspectiva, encontrando numerosos estudios específicos como los dedicados a detectar patrones alimenticios (Colombo, Chorley, Williams, Allen y Whitaker, 2012) o de recomendación (Sklar, Shaw y Hogue, 2012), entre otros. La observación participante nos obligó a conceptualizar dos aspectos claves: Foursquare® como un espacio de juegos y como un mercado de capital social, aspectos que se desarrollan en los antecedentes, pero que nos sirvieron para entender que el concepto de capital social agrupaba muchas de las cuestiones que motivaron la participación en las redes sociales.
Nuestro objetivo fue caracterizar los capitales sociales en Foursquare®, en tanto atributos, insignias, medallas y diferentes formas de reconocimiento provistas por la plataforma. Encontramos que los usuarios que contaban con menos participación, tanto en amistades como en check-ins estaban menos comprometidos, y los de alto grado, que se clasifican como kinless o conectores hubs, optan por diferentes estrategias que conducen a aumentar su visibilidad tanto para sus contactos como para el resto de la red con capacidades de visualizar sus actividades y perfil. La persistencia de algunas características nos llevó a considerar la posibilidad de trabajar con conjuntos de datos pequeños, lo que resultaría una opción muy útil (Arora, Ge, Sachdeva y Schoenebeck, 2012).
Ya en el procedimiento de trabajo previsto en el cronograma propuesto, se comenzó por la selección de un grupo de usuarios caracterizados por su intensa actividad de check-ins y reclutamiento de amistades. De la observación de esta práctica descubrimos que los lugares en los que el usuario testimoniaba su localización no correspondían algunas veces a su ubicación real. Por ejemplo, un usuario podía definir su hogar con el nombre de su club del que es simpatizante O también, a modo de broma, podía definir la ubicación de un club con el nombre de su club rival.
Seleccionamos 5 usuarios con los que nos entrevistamos tanto personalmente como por escrito, y así conocimos más a fondo el funcionamiento de Foursquare®.
Transcribimos acá parte de uno de los intercambios con el usuario Mariano Amartino, quien sería nuestro Usuario Semilla:
¿Por qué empezaste y por qué dejaste de usar 4SQ®?:
Empecé porque el servicio de geolocalización en su momento era interesante como experimento y ver hasta donde agregar una capa de espacio podía darle sentido a la presencia online. Dejé de usarlo cuando cambiaron el modelo de negocio y se convirtió en una API y no mucho más.
Acerca de la geolocalización y los móviles. ¿Hacia dónde crees que van?
La capa de geolocalización va a ser invisible, pocas veces veo algo específico de geoposicionamiento, sino que lo veo como algo más que se suma a otras opciones (por ejemplo: subir fotos y ubicarlas, aunque ahora ni siquiera podés buscar por ubicación en tu historial de Instagram®). Solo en el caso de Snapchat® que se ve como algo interesante buscar “sociabilización” y aumentar la unión entre online y offline.
¿Los usuarios tienden a hacer check-in donde los hacen sus usuarios amigos?
En general sí, eso se ve en los clusters de Facebook®.
¿Alguna idea de Foursquare® que te parezca importante?
Creo que hicieron una buena plataforma y ahora la están monetizando inteligentemente, pero no veo cómo pueden crecer en data para explotar más su modelo de predicción.
Transcripción de parte de la entrevista con Hernán Nadal, otro usuario calificado:
¿Usás Foursquare®? ¿Si es así: por qué lo usas?
En realidad lo tengo instalado en mi celular, muchas veces hago un check-in y espero que suceda algo, que alguien diga algo. Pero no suele suceder. Quisiera poder organizar alguna movida con esta herramienta, pero no la entiendo aún. Es como que me da pena sacarla de mi celular.
¿Si la desinstalaras la podrías volver a instalar fácilmente, no?
Sí, es verdad, pero no es algo que haga habitualmente. En general uso mi memoria como un indicador de que algo no anduvo bien. Sí me preocupa que no tenga buena integración con Instagram®.
Para realizar investigaciones en plataformas de redes sociales es fundamental el acceso las APIs de las mismas. Una API es un conjunto de instrucciones digitales que tienen como finalidad ser utilizadas por otro software. Las siglas API vienen del inglés Application Programming Interface, que en español sería Interfaz de Programación de Aplicaciones. Es decir, una API permite establecer puentes entre distintos programas de modo que se logre cierta abstracción estructural, independientemente de los datos procesados.
La interacción entre las plataformas de redes sociales y la API es realizada mediante peticiones (pueden usarse peticiones generales tales como de tipo GET, POST, PUT o DELETE). Todas las peticiones, independientemente si son para leer, escribir, editar o eliminar información, deben de incluir el símbolo de acceso por medio del cual se valida la petición y se acepta o se rechaza de acuerdo a los permisos otorgados por el usuario.
Estas características generales se aplican a APIs de Twitter®, Facebook®, YouTube®, Foursquare®, Instagram® o Uber®, pero con diferencias particulares.
Por ejemplo, Uber Movement® se trata de una página web en la que usuarios registrados pueden acceder a los datos que la aplicación ha ido generando en los últimos años. Ofrece los datos anonimizados para no comprometer la privacidad de sus usuarios y uno de sus objetivos es que se conozcan en qué zonas deberían mejorarse factores como el transporte público.
Facebook® protege la información del usuario: no es posible acceder en la red social a datos a menos que tenga una relación de amistad con la persona sobre la cual quiero obtener los datos. Sólo puede obtenerse acceso sin restricción al nombre y al género de los usuarios, pero si un usuario da consentimiento explícito a que terceros accedan a su información de perfil, correo electrónico, gustos, intereses, amigos, eventos, datos de amigos, entre otros más, entonces la API tendrá pocas restricciones para recabar los datos de ese usuario en particular.
Construcción de vínculos y dispositivos de lectura
La población a estudiar surgió del método de muestreo de bola de nieve, del tipo discriminatorio y exponencial. La toma de la muestra se iniciaría un en tiempo t0 y finalizaría en un t1. El período dependería de la velocidad de procesamiento, ya que Foursquare® delimitaba el número de usuarios a recolectar a 10 amigos por cada usuario relevado, así como la cantidad de usuarios por unidad de tiempo.
Nos propusimos avanzar en 6 anillos de recolección desde el usuario semilla, es decir recolectaríamos los 10 amigos del usuario semilla y luego a cada uno de ellos lo consideraríamos un nuevo usuario semilla, del que obtendríamos eventualmente hasta 10 nuevos amigos con los que repetiríamos el procedimiento.
La API permitía hasta 500 usuarios por hora, lo que nos significó casi dos años de recolección, de los mínimos 141 días que hubiera demandado si se hubieran realizado de continuo, sin interrupciones ni dificultades de conectividad.
Si bien existía la posibilidad de que la plataforma cambiara a lo largo de la investigación, el volumen de usuarios al comenzar la investigación era de aproximadamente 30 millones según lo que informaba la aplicación, lo que daba un horizonte de predictibilidad fáctica a la realización de nuestro trabajo.
Ilustración 5
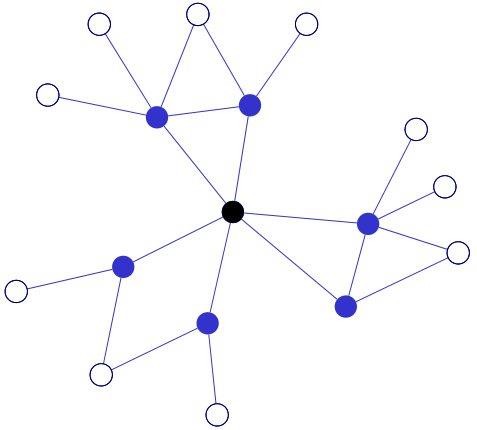
Esquema en el que círculo negro representa el usuario “semilla”, los círculos azules los amigos recolectados formando el primer anillo, los círculos blancos el tercer anillo. Las líneas representan relaciones de amistad en 4SQ®.
Aunque con nuestra metodología podíamos incluir en nuestra base de datos hasta el 30% aproximado de Foursquare®, eso evidentemente se vería limitado por dos variables, a saber: no todos los usuarios contarían con 10 amigos (sabíamos que un tercio de los usuario eran inactivos) y por otro lado la configuración de la plataforma produciría solapamientos de usuarios ya que los nuevos usuarios recolectados podrían ya existir en nuestra base.
Luego se aislaron los usuarios por ciudades. Inicialmente habíamos percibido que la bola de nieve iba proveyendo en su recolección automatizada usuarios sobre todo de Argentina, España y Brasil, posiblemente como dijimos porque esta era una propiedad derivada del primer círculo de amistades del usuario semilla. Nos decidimos entonces por discriminar a los usuarios de Buenos Aires, Córdoba y Rosario en Argentina, San Pablo y Rio de Janeiro en Brasil y Barcelona, Madrid y Sevilla en España. Luego, como se verá en el análisis de resultados, algunas ciudades debieron ser descartadas por la escasez de datos recolectados, quedándonos con las matrices de las tres ciudades argentinas mencionadas, San Pablo (Brasil) y Barcelona (España).
Los pasos concretos efectuados en la investigación, para la lectura de la API de 4SQ®, representan el segundo trabajo de campo realizado en la tesis, además del cuestionario-web.
Procesos del Análisis de Redes
A continuación, se desarrollan de manera ordenada las herramientas informáticas y los procedimientos realizados con los cuales llegamos a los resultados presentados. El método de obtención y procesamiento de datos de entrada consta de las siguientes cuatro etapas:
- Recolección.
- Procesamiento – Recolección del siguiente grado.
- Adaptación a Formatos de salida.
- Procesamiento de Salida:
- Procesamiento de mapas
- Procesamiento de archivos Gephi
- Procesamiento de archivos CSV como tablas dinámicas
Recolección
Ilustración 6
Mariano Amartino en Foursqaure®. 11/10/2015 visto desde el perfil del autor.
Se recolectaron, desde el nodo semilla (Mariano Amartino), 7 grados de nodos y 10 links de amistad de cada uno de los nodos, links que no son discriminados por geolocalización, todo tal como lo permite la API de la plataforma Foursquare®.
Ilustración 7
Amartino en Twitter® 11/10/2015. Podemos observar que es un usuario altamente activo (con más de 123 mil tweets) y con un gran potencial de difusión gracias a sus casi 25 mil seguidores y su pertenencia a 7 listas (grupos de tuiteros con intereses similares).
Lectura de la API de 4SQ®:
- Fecha de inicio de la recolección: 20 julio 2013
- Fecha de cierre captura de nodos: 4 diciembre 2013
- Fecha de cierre captura de enlaces: 1 de marzo 2015
Procesamiento y Recolección del grado siguiente
Se necesitaron 6 meses de procesado informático para la cantidad de usuarios, por la limitación de cantidad de consultas por hora que permite la plataforma.
La obtención de los datos de entrada se realizó mediante queries (consultas a la API) automatizadas, archivándose los datos obtenidos en formato JSON. Este formato permite trabajar de manera eficiente y relativamente sencilla con altos volúmenes de datos. Se archivaron luego los ID y los atributos por usuario en un archivo de texto plano (es decir, un archivo que contiene sólo caracteres, sin ninguna forma ni estilo, ni referencia a la fuente o tamaño de la letra usada, etc. Esta clase de archivos, si bien no necesitan interpretarse para leerse, en general pueden ser procesados por otros programas. Por ejemplo, un archivo de texto en formato HTML, al ser ejecutado mostraría una página web, más rudimentaria o más elegante dependiendo la complejidad del texto), y, en otro archivo, el conjunto de relaciones. Tales archivos en conjunto pueden convertirse en distintos formatos: VNA, DLL o NEO4J. Esto permite visualizar y procesar los datos para detectar la información relevante.
La fase de recolección de datos se realizó con un script llamado semilla.ksh. Un script es un programa simple y pequeño (generalmente) que lleva dentro suyo instrucciones muy específicas para ser leídas y ejecutadas por otro programa más grande. Por ejemplo, los botones interactivos que podemos encontrar en muchísimas páginas de internet son funcionales gracias a scripts que así lo permiten.
El siguiente script muestra un paso de recolección donde se ejecuta, con parámetro de entrada, el nombre del archivo de entrada, y lo que debe procesarse, que en este caso es el 1er grado de conexión con el usuario semilla.
Ilustración 8
![]()
Script semilla.ksh.
Luego se recolectaron las relaciones de amistad de cada nodo obtenido, creando un anillo de amistad alrededor de cada uno (primero del nodo semilla y luego del resto). En los sucesivos anillos de relaciones que ahora se mostrarán, se utilizaron los scripts todo?g.ksh, donde “?” denotaba el número de link respecto del contacto original o semilla.
Aclararemos, antes de seguir explicando el procedimiento, que el nombre del programa denota un tipo especial de lenguaje de programación o intérprete de órdenes, el cual puede comprenderse mirando la extensión del archivo (es decir, el conjunto de letras que aparecen luego del nombre del archivo, separados por un punto). Por ejemplo, .ksh denota que el programa se trata de uno interpretado por Korn Shell. Aun así, en la mayoría de los scripts KSH, sino en todos, se utiliza el programa Bash como shell. El Shell es el intérprete de órdenes estándar del sistema operativo Linux que tiene la característica de poseer su código fuente libre, lo cual permite que cualquier usuario pueda editarlo para añadir características o mejorar su eficiencia. Bash (acrónimo de Bourne again shell) es un programa informático cuya función consiste en interpretar órdenes, y un lenguaje de programación de consola. Consola es la denominación que recibe una interfaz por la cual manipulamos un programa o sistema operativo mediante funciones escritas.
También mencionaremos que en los archivos PL la extensión denota que se utilizará el lenguaje e intérprete PERL. Perl es un lenguaje libre, multiplataforma y que dispone de muchas bibliotecas para el desarrollo de diferentes aplicaciones.
Ilustración 9

Script todo1g.ksh.
El script todo?.ksg llama a su vez a varios scripts relacionados. El primero, reacondiciona.pl, es un script PERL que formatea el código JSON, resultado de bajar los datos del primer contacto o semilla. El código JSON es muy sencillo de leer por cualquier lenguaje de programación, por lo que se lo suele usar de intermediario cuando se utilizan varios lenguajes.
Como resultado del comando se almacena el archivo 1 (en formato JSON).
Archivo 10

Archivo 1.
Para no repetir el uso en los nombres de archivos por cuestiones obvias, y no pisar el contenido, desde el script todo2g.ksh se genera un nuevo esquema de nombres, que consta en principio de la adopción de un directorio data?/ para cada grupo de ejecuciones. Dentro de este grupo, más adelante se usa el número de ID de Foursquare® como nombre de archivo y, posteriormente, se agregan sufijos para reemplazar los nombres de los archivos 2 y 3, que desarrollaremos en los próximos párrafos.
Luego, el resultado del script recondiciona.pl es enviado a una segunda instancia, donde se ejecuta el script leer_contactos.pl. Este script, también en formato PERL, saca la lista de número de identificación en Foursquare® de los contactos relacionados con el usuario del archivo 1. Es la primera instancia en sí de procesamiento de datos.
Se obtiene entonces una lista de relaciones (archivo 2), que será posteriormente la entrada de datos utilizada para generar, nuevamente y mediante el mismo procedimiento, los archivos 1, 2 y 3 para cada nueva relación.
Ilustración 11

Lista de relaciones.
Luego aparece el script leer_ids.pl (o leer_ids_completo.pl, según la etapa del proceso), otro archivo en formato PERL, encargado de leer todos los datos de los usuarios de Foursquare® (número identificador de Foursquare®, nombre y apellido anonimizado, etc.) y los inserta en otro archivo (3), que tiene la particularidad de ser temporal, y se llama ids.txt).
Ilustración 12

Archivo ids.txt.
Dicho archivo se guarda en cada directorio data?/. Este archivo es procesado posteriormente con otro script para eliminar registros duplicados y completar datos importantes (21 datos en particular) de cada usuario en otra red social (consolidar_ids.pl).
Ilustración 13

Archivo ids.txt.
Este proceso completo de leer un ID (el número 1 en este caso), procesar el formato JSON (archivo 2) y procesar el texto, se repite en todos los grados del proceso hasta llegar a completar los 6 links a conseguir partiendo del nodo semilla. Como resultado de este proceso también se genera un archivo con el número de ID de Foursquare® en un directorio de datos ($PWD/data?) donde ? es el número de link respecto del nodo semilla o ronda de recolección de datos.
Ilustración 14
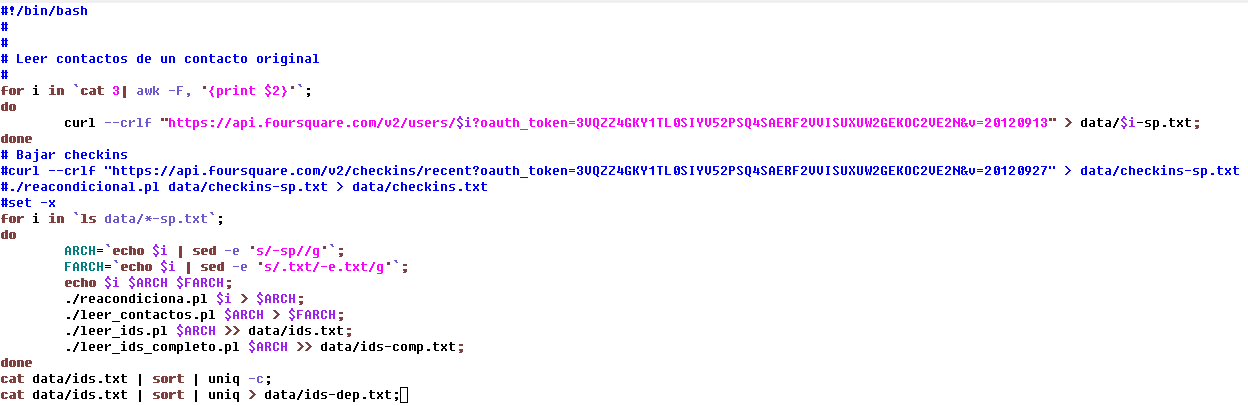
Script bajar_1g.ksh
Recursividad
Como dijimos antes, las etapas de recolección y procesamiento primario se repiten hasta conseguir los n links de contactos esperados respecto del nodo semilla.
Por ejemplo, para conseguir tres grados desde el nodo semilla se debe proceder de la siguiente manera:
- Recolección del nodo semilla (archivo 1).
- Procesado de nodo semilla (archivo 2 que contiene IDs y 3 relaciones). 3.- Recolección de grado +1 con input en archivo 3.
- Procesado de todos los archivos recolectados en paso 1 (nuevos archivos 2 y 3 para cada relación de semilla).
- Recolección de grado +2 con input en los archivos 3 del paso anterior.
El siguiente esquema muestra la composición y orden para correr los scripts. Esto asegura que las tareas se corren sin terminal asignada, por lo que son menos proclives a fallas humanas y cancelaciones. También hacen más fácil retomar el trabajo desde una falla catastrófica.
Ilustración 15
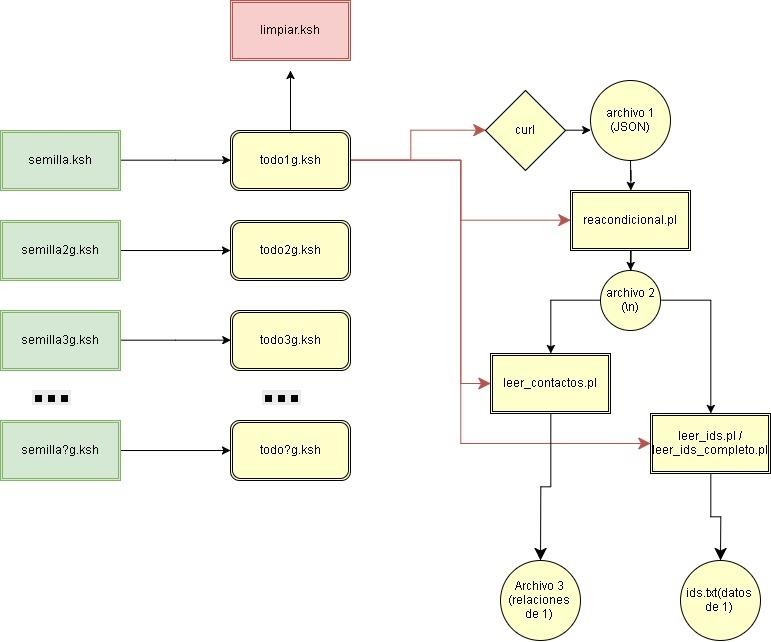
Ejecución de procesos.
El script limpiar.sh debe correrse solo si está inicializando el ambiente de ejecución, o limpiando todos los datos para correr nuevamente todo el proceso completo.
En el Esquema 1 vemos los iniciadores de procesos, que son los scripts de color verde en este caso. Estos ejecutan, mediante el comando nohup de Unix/Linux, el inicio de los scripts que hacen las tareas realmente (los scripts del formato todo?g.ksh).
Este proceso se repite por cada grupo de links que queramos bajar de Foursquare®. Es decir, el archivo 3, que contiene relaciones, tiene una lista 1 a 1del nodo semilla (ID de Foursquare) y del ID de cada amigo/amistad/conexión en la plataforma.
Posteriormente, se utiliza cada ID de amigo (el segundo campo luego de la coma) como entrada de una nueva ronda de procesamiento. Con los mismos scripts, se generan los archivos 1, 2 y 3 por cada ID nuevo.
Ilustración 16
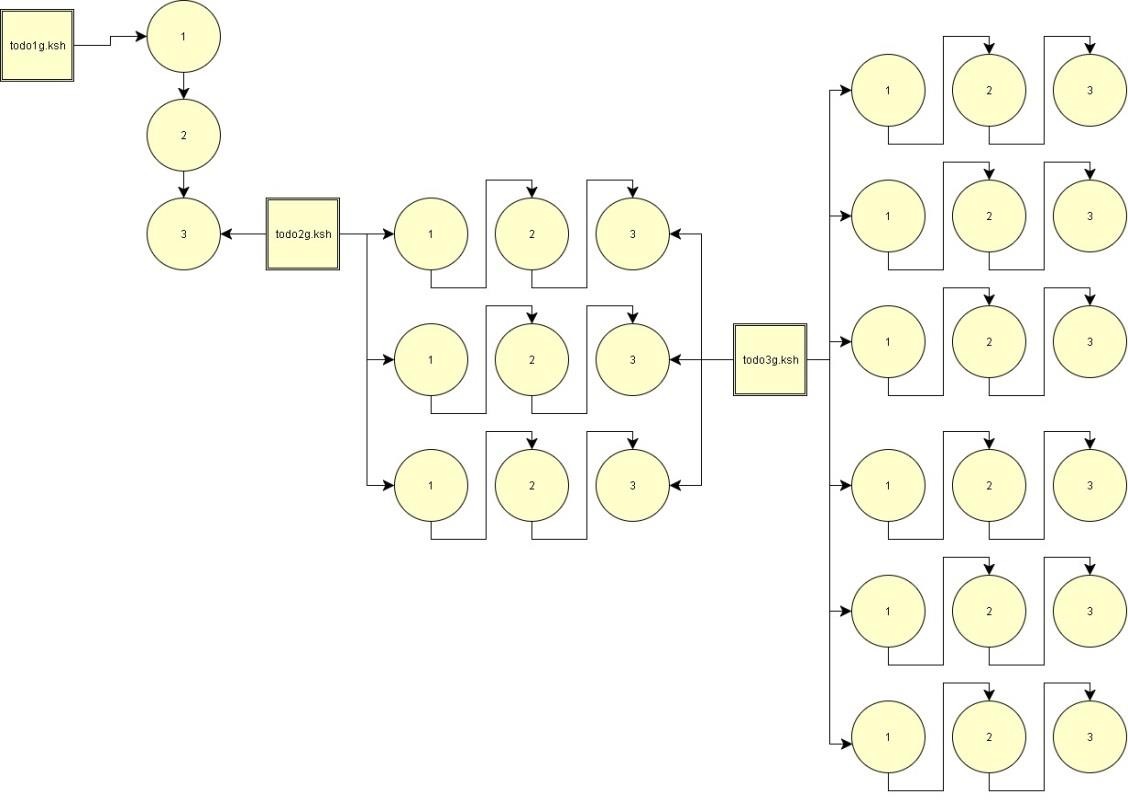
Programas y archivos 1, 2 y 3. Etapas recursivas.
Dado que el proceso no podía ser interactivo por la cantidad de tiempo necesaria en la ejecución y por la posible pérdida de la terminal (la cara visible del shell, con la cual interactuamos) conectada durante el proceso, se utilizaron scripts en segundo plano para ejecutar todas las tareas. Este tipo de script tiene otra utilidad muy importante, y es que permite retomar el trabajo desde donde se haya terminado, por ejemplo debido a problemas de hardware o a pérdidas de conectividad con Internet. Debido a esto, recomendamos su utilización (y del comando nohup, el encargado de mantener los procesos activos) para futuros trabajos.
Adaptación de formato de salida
Ilustración 17
Ejemplo de conversión a formato UCINET.
Para las actividades de procesado final de datos y conversión en la información buscada, se requiere transformar la salida de texto plano en los diferentes formatos de entrada de otras herramientas. Fundamentalmente, se convirtió al archivo de IDs (ids.txt) y al archivo de relaciones (3) en diferentes variantes de CSV (comma separated values), VNA y UCINET.
También se realizaron pruebas con NEO4J, un software también libre para Base de Datos que se orienta a grafos. Para utilizar esta herramienta se tuvieron que normalizar los datos de relaciones, de manera que se pudieran cargar y procesar masivamente en este motor de base de datos.
Los datos son utilizables de este modo como datos de entrada, para procesarlos en diferentes herramientas como Gephi, Pajek, Excel, LibreOffice, etc.
Los scripts de conversión de formato utilizados son los siguientes:
Ilustración 18
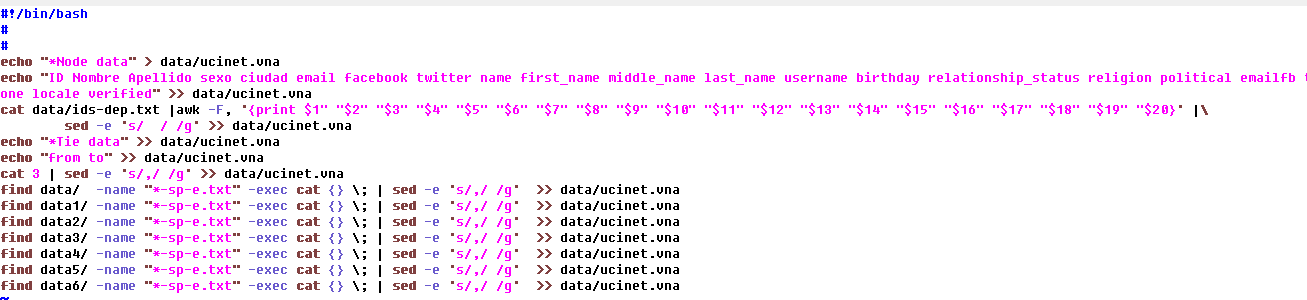
Ejemplo de conversión a formato VNA.
Sobre todo el material recolectado, a nivel mundial, se realizaron dos descremados:
- Primero se aislaron los usuarios autodefinidos y de cada nodo se incluyó en la base de datos su conjunto de atributos declarados y la totalidad de lazos con otros usuarios de la red. Obtenidos estos nodos, se realizó una segunda búsqueda, seleccionando a los usuarios con ID de Facebook® para luego recolectar los atributos de cada usuario en esa red social. De este modo se obtuvieron perfiles de hasta unos 20 atributos por nodo.
- Terminado este proceso se evaluó a los usuarios exploratoriamente con distintos atributos de red, seleccionándose la centralidad de grado y la centralidad e intermediación.
En este caso concreto pudimos automatizar la toma de atributos de usuarios de 4SQ® de Facebook® y avanzamos en la metodología con Twitter®.
Con la información obtenida, es decir, usuarios con atributos individuales y enlaces entre ellos, que significaba una porción minúscula del total de datos recopilados (alrededor del 3 % de todos los usuarios recolectados y menos del 1 % del total de datos totales) construimos la base de datos sobre la que exploramos las hipótesis de la tesis.
Debemos aclarar que la falta de trabajo con datos generales (más del 1,3 millones de usuarios con las características aludidas) si bien respondió a un criterio de objetivos de trabajo también se vio forzada por los recursos técnicos (capacidad de hardware, especialmente la memoria RAM) con los que contábamos para procesar la cantidad de nodos, links y atributos durante las distintas fases temporales, así como de la velocidad de conectividad y acceso a programas adecuados. Se intentó con procesado en paralelo y contratando capacidad de memoria extra en servidores adecuados, pero nos encontramos con que el volumen de datos hacía colapsar los programas, aún el Pajek xxl, que era una herramienta open source hecha en Eslovenia, de monitorización y análisis de redes sociales, que simula interacciones molecularmente. Dado que el estándar de trabajo era con ficheros ASCII (ficheros de texto sin formato enriquecido), que carece de módulos para realizar evaluaciones complejas como las derivadas de conectarse a Facebook® o Twitter®, el trabajo con redes extensas no podía analizarse al momento de escribir la tesis.
Como se expresó arriba, la cantidad de relaciones en redes sociales crece con tendencia exponencial a medida que la cantidad de nodos lo hace linealmente, por lo tanto al incrementar la cantidad de nodos sube notablemente los recursos informáticos consumidos. El programa utilizado para análisis de redes sociales fue Gephi, un software open source de análisis y visualización de redes escrito en Java en la plataforma NetBeans. NetBeans es un entorno de desarrollo libre para el lenguaje de programación Java. Java es, además de lo expresado, una plataforma informática general, orientado a objetos y que tiene la intención de facilitar que los desarrolladores de aplicaciones escriban un programa para que sea ejecutable en cualquier dispositivo.
Inicialmente utilizamos la versión 0.8.2 de Gephi y luego terminamos la tesis con la versión 0.9.1. No pocas son las dificultades para mantener en funcionamiento de programas basados en Java cuando la mayor parte de las veces necesitan la reprogramación de códigos de articulaciones entre las diferentes actualizaciones de los programas utilizados junto a los sistemas operativas.
Es importante mencionar que Gephi es un programa muy utilizado, lo que permite el intercambio de archivos entre colegas; es sumamente intuitivo, de rápida curva de aprendizaje y es respaldado por una comunidad voluminosa de usuarios, integrados en grupos de discusión y foros donde obtuvimos rápida ayuda ante los problemas que se iban sucediendo. Además existe una densa red de blogs, artículos y tutoriales donde evacuar dudas o proponer soluciones. Además Gephi puede también importar datos de otros formatos de redes sociales, así como conectarse a plataformas de redes como Facebook® o Twitter® y generar grafos, visualizaciones y cálculos matemáticos.
Se realizaron entonces los mapas utilizando herramientas disponibles open source y recursos de planimetría ofrecidos por Google®.
Concretamente cada mapa consta de una lista de identificadores de Foursquare® y coordenadas (latitud y longitud) del último check-in. Con esta información se pueden cargar valores en formato CSV (comma sepparated values) en Google Maps®, que se exportaron a archivos KMZ que pueden ser trabajados en Google Earth®. Los mapas se realizaron con los usuarios globales de cada ciudad y el 1% de los usuarios con mayor grado de centralidad que se habían obtenido en las fases anteriores del procesamiento y que se describieron detalladamente arriba.
Vamos a trabajar ahora sobre el algoritmo Chinese Whispers. Este algoritmo es relacionable con el juego del teléfono descompuesto, que dio la metáfora a partir de la cual se programó este algoritmo de clusterización, que tiene por objeto la búsqueda de grupos de nodos que transmiten el mismo mensaje a sus vecinos.
Los niños de varios países son aficionados a este juego de mesa, al que también llaman el Teléfono Árabe en Francia, y que consiste en que un grupo de niños se alinean uno detrás del otro. El primer niño piensa una frase divertida, que es el mensaje transmitido a la línea de chicos. Se lo susurra en el oído de su sucesor, haciendo lo mismo éste, y susurrando la frase al siguiente, de modo que pueda ser escuchado por éste, pero no por el resto.
El juego termina cuando el último niño dice en voz alta lo que ha percibido y lo divertido es comparar la primera y la última frase. Por lo general la distorsión es importante, aunque la regla del juego dice que todos los niños deben pasar el mensaje a la siguiente estación de relevo lo más fielmente posible. Sin embargo, salvo excepciones, generación tras generación de niños se obtiene al final una frase más corta y más simple que la original.
El Centro para la Evolución del Lenguaje, de la Universidad de Edimburgo, (Kirby, 2016) viene estudiando la evolución de replicadores lingüísticos o memes, mediante el “Juego del teléfono descompuesto”. Su hipótesis es que la mutación de sentido de los memes cada vez que pasa por un replicador es lo que permite la evolución del lenguaje. La metáfora sirve para la programación mediante la organización de un flujo de datos: se configuran agrupamientos de nodos que por sucesivas iteraciones se destilan, hasta plasmar los lo que luego vemos en las visualizaciones como los que trasmiten el mismo mensaje sin alteraciones.
Chinese Whispers es un algoritmo básico pero bastante eficaz para particionar nodos de grafos no dirigidos. El algoritmo origina conexiones al azar y recolecta cómo responden los nodos. Tiene por objeto la búsqueda de grupos de nodos que transmiten un mismo mensaje a sus vecinos. El objetivo de este enfoque de agrupamiento es dividir la red en clústeres individuales que coloreamos, creando una visualización más intuitiva y fácil de interpretar. El significado de un número importante de comunidades es que los mensajes tendrán mayor tendencia a distorsionarse a lo largo de la red. El algoritmo es capaz de identificar cosas poco esperables, como por ejemplo cuando se buscó con el algoritmo agrupamientos por tamaño de viviendas y se encontró (en USA) que los republicanos tienden a vivir en casas grandes preferentemente hacia las afueras de las ciudades, en tanto los demócratas preferían departamentos en las zonas más urbanizadas con mayor acceso a medios de transporte.
La encuesta cuantitativa como control
Como expresamos arriba, para complementar los datos que obtendríamos en crudo directamente de la API de 4SQ®, decidimos realizar un cuestionario vía Web. Sabíamos que experiencias anteriores habían tenido serias dificultades para conseguir que usuarios comunes completaran un formulario de este tipo, además de las dificultades fácticas del relevamiento en sí.
Una primera dificultad fue llegar con el mensaje a los posibles respondentes. Se utilizaron varias estrategias que se superpusieron una a otra ante las dificultades en obtener respuestas. Una de las primeras ideas fue solicitarle a nuestros amigos en la plataforma que completaran la encuestas, y así se lograron algunas escasas respuestas. Luego difundimos la encuesta entre nuestras amistades en otras redes sociales como Facebook® y Twitter®. Era evidente que los usuarios que tuvieran mayor impacto serían los mejores candidatos, pero al mismo tiempo podrían ser los más renuentes a divulgar la propuesta.
Luego de insistir con algunos conseguimos un aceptable número de posteos en muros de Facebook®, y de retweets. Un retweet es cuando un usuario de Twitter® repite un tweet escrito por otro usuario para que llegue a sus seguidores. Como la cantidad de respuestas aún era escasa recurrimos a enviar pedidos de respuesta vía email a nuestros contactos a los que les solicitamos que reenviaran el mensaje a otras personas que creyeran podrían estar interesadas en participar de la encuesta. Así incrementamos algo la cantidad de respuestas, pero seguía siendo insuficiente: a esa altura teníamos unas pocas decenas de formularios completos.
Decidimos ampliar el rango de opciones de visibilización: utilizamos nuestro blog para difundir el cuestionario y pedimos que lo postearan en sus muros. Ahí se explicaba con más detalle el pedido y volvimos a repetirlo en contactos de nuestra lista de emails, eso incluía a nuestros colegas en la universidad y a muchos de nuestros alumnos, muchos de ellos adoptadores tempranos de estas tecnologías. Se le pidió a los alumnos de los diversos talleres y charlas ofrecidas en ámbitos académicos que completaran la encuesta y que de ser posible la redistribuyeran a sus conocidos.
Dado que de este modo aún no se llegaba a un umbral de respuestas suficientes, contratamos un servidor de emails ofrecido en la página web situada en la url envialosimple.com, creada por una empresa dedicada al marketing digital, que ofrecía servicios útiles para nuestro interés, además de la masividad del envío: edición compleja, personalización de los mensajes, posibilidad de adjuntar archivos, incluir logos explicativos y plantillas para ajustar el mensaje a nuestros requerimientos. Por este medio se enviaron un total de 132320 correos electrónicos en varias etapas a usuarios obtenidos de diversas bases de datos estructuradas y no estructuradas, a las que se tuvimos acceso de distintas fuentes, propias y compartidas. Buscábamos usuarios de redes sociales tales como, preferentemente, estudiantes universitarios, jóvenes profesionales y personas activas socialmente en diferentes ámbitos del diseño gráfico, de la industria, del comercio, de servicios relacionados con tecnologías digitales y de la docencia universitaria.
Las restricciones del servidor de envío de emails, respecto a evitar emails masivos no solicitados (que molestarían a eventuales receptores y que serían además enviados a las carpetas de correo basura, o spam) nos obligó a seleccionar preferiblemente aquellas que habían sido creadas por suscripción de usuarios a servicios de información tecnológica. Sin embargo debimos utilizar un criterio amplio que establecimos en las entrevistas exploratorias, buscando no molestar a los consultados pero al mismo tiempo recolectar las muestras requeridas.
Todos los pedidos de respuesta derivaban a una única dirección URL (https://bit.ly/337KPzx), donde se alojaba la encuesta, que se adjunta en el apéndice. A los usuarios de las bases de datos portuguesas se le facilitó la misma encuesta online en su idioma. Por las características del software de captura de los datos, las respuestas no fueron desmezcladas según su origen.
Con esta metodología se obtuvieron 843 cuestionarios respondidos, de los cuales se seleccionaron solamente 283 encuestas completas que fueron realizadas por los convocados a hacerlo, entre el 3 de mayo de 2014 y el 20 de noviembre de 2016. Si bien la unidad de análisis original de la investigación la establecimos en usuarios de 4SQ®, las dificultades descriptas arriba impidieron que las poblaciones pudieran situarse claramente en torno a sus características de contenido, lugar y en el tiempo. Queremos explicitar que la metodología no permite establecer probabilidades iguales, y por lo tanto constituyen un sesgo que podría evitarse en nuevas consultas. Creemos que una vía para explorar es la articulación de la búsqueda en la API automatizada con el envío de la encuesta a los usuario recolectados, algo que encontramos como reproducible al final de nuestro trabajo.
Las dificultades no muestrales de establecer un procedimiento adecuado para alcanzar el tamaño que necesitábamos para representar la heterogeneidad de la población, y un intervalo de confianza y de error de estimación nos impiden establecer un nivel de significación estadística del cuestionario, sin embargo podremos utilizarlo como sonda contextual por otros motivos. El primero es el perfil demográfico de los datos obtenidos, posiblemente porque el sistema de búsqueda de respondentes de alguna manera remeda al de bola de nieve, aunque en este caso simplemente sea por la fuerza mayor, es decir por la falta de alternativas. Esto, como se podrá ver, se aplica a los perfiles de edad, género y lenguaje elegido por los usuarios. El segundo es que la extensión del tiempo de toma de las encuestas es concordante, excepto en algunos meses, con el de la lectura de la API automáticamente. Por último la cantidad de respuestas del cuestionario que se obtuvieron alcanzó un tamaño equivalente a investigaciones realizadas en Foursquare® en dicho período.
Control por atributos
A los efectos de reforzar los controles sobre el material y eventualmente detectar desviaciones, se seleccionaron 500 usuarios al azar, dentro del grupo de individuos que habían completado al menos 15 atributos en su perfil.
La visualización de los resultados permitió detectar un nodo que por cuestiones azarosas (el usuario tenía un nombre que el protocolo interpretó como un enlace) había sido incluido inadecuadamente en la matriz, generando luego distorsiones en el resto de la estructuración.
Salvado el error se continuó con el resto de las actividades propuestas, los resultados y análisis se expresan en el apartado correspondiente.

