





“Aquí no estaré yo, que seré parte del olvido, que es la tenue sustancia de que está hecho el universo”. Jorge Luis Borges.
Los desafíos expuestos serían poco relevantes, si no tuvieran aplicación alguna al mundo de la investigación social empírica. En el siguiente capítulo se intentara mostrar casos de investigación real en lo que este tipo de conceptos puede resultar de utilidad.
Los conceptos teóricos y los desafíos expuestos se aplican a un estudio de caso en el partido de Tres de Febrero, a partir del seguimiento longitudinal de la evolución de la pobreza y la estratificación social en los hogares de este partido del Gran Buenos Aires entre los años 2000 y 2005. La investigación se orienta a comprender las condiciones que hacen más probable determinadas trayectorias de vida, y dimensionar la potencial aplicación de este tipo de estudio al diseño de políticas públicas e intervención social. Se utilizan técnicas de análisis del cambio para variables categóricas, y modelos multinivel para analizar la evolución de los ingresos individuales deflacionados.
Al analizar la variable categórica pobreza, se analiza el tipo de transiciones y su probabilidad, la estabilidad agregada e individual, y otros problemas[1].
Cuando analicemos el ingreso deflacionado en el período discutiremos la aplicación de modelos lineales multinivel de cambio (Singer & Willet, 2003), la interpretación de algunos de los coeficientes habituales, los efectos fijos y aleatorios (Hsiao, 1986), la correlación intraclase para distinguir la varianza del ingreso explicada por factores intraindividuales y por factores interindividuales, y otros problemas.
Características de los modelos de cambio longitudinales
Podríamos diferenciar los estudios sincrónicos (que estudian un fenómeno en el momento en que se produce sin considerar su historia o su evolución) de los diacrónicos (enfoque de estudio a través del tiempo). Esta distinción está tomada de la lingüística, en particular de los estudios de Sausurre[2] (Saussure, 1979; Saussure, Bally, Sechehaye, & Riedlinger, 1974; Saussure, Komatsu, & Saussure, 1993). La importancia de los conceptos de lengua y habla, de diacronía y sincronía, pueden aplicarse análogamente en el estudio de cualquier sistema social dinámico.
Una investigación longitudinal es aquella en la que se realizan varias mediciones en el tiempo de un fenómeno. También es investigación longitudinal la que se realiza del presente al futuro, donde se realizan varias mediciones en relación al tiempo (prospectiva). En contraposición, la investigación transversal se realiza en el presente, y en ella se realiza una sola medición en relación al tiempo (Marradi, 2010; Sampieri, 2006).
En las ciencias sociales los estudios longitudinales permiten distinguir fenómenos de corto, medio y largo plazo, su distribución y su continuidad específica. Así, por ejemplo permite saber cómo afecta a una sociedad la pobreza. La investigación longitudinal aporta cierto tipo de información que no es posible establecer en el formato de los estudios transversales. Por ejemplo, si la tasa de pobreza es del 10 % en un punto en el tiempo, esto puede significar que el 10 % de la población son siempre pobres – siempre los mismos individuos, sin movilidad social -, o que en ese 10 % se alternan diversos individuos – es decir que hay movilidad social en un contexto en el cual sigue existiendo el fenómeno de la pobreza –. Los estudios longitudinales nos permiten diferenciar esas situaciones y determinar cuál es la descripción adecuada de la movilidad social.
Se suele considerar a los estudios longitudinales como diseños no experimentales, dado que no se manipulan variables de forma intencional; es decir se trata de estudios de observación y registro de los cambios que se presentan en un fenómeno, sin realizar en él intervención o estímulo alguno, para después realizar un análisis de interrelación de los elementos (Sampieri, 2006). Los diseños no experimentales pueden subdividirse en diseños transeccionales y longitudinales, obedeciendo al criterio de cuándo se recolectan los datos. En los diseños transeccionales (o transversales, cross sectional), en los cuales se recopilan datos en un solo momento, el análisis de sus resultados está orientado a determinar la interrelación de las variables en un momento o instante determinado. Este tipo de diseño puede ser exploratorio, descriptivo o de correlación según el análisis final que desee hacerse.
En el análisis longitudinal surgen problemas específicos[3], algunos de índole teórica, como la relación temporal de las causas con los efectos, la tipología de procesos que podremos encontrar, o la interpretación de la evolución de ciertas variables a lo largo de la vida; otros son más bien prácticos, como la atrición del panel y los costos operativos de este tipo de estudio.
Los diseños longitudinales, también denominados evolutivos o de tendencia, se caracterizan porque la recolección de datos se realiza en una secuencia de puntos o períodos en el tiempo, con el fin de analizar los cambios que se presentan e inferir sus causas (Sampieri, 2006). La determinación de tales puntos o periodos en el tiempo se deben definir bajo un criterio objetivo que obedezca al tipo de estudio que quiera realizarse: de tendencia, de evolución de grupo o panel. En los diseños panel (como el que analizaremos en el caso del estudio longitudinal de Tres de Febrero) el mismo grupo específico de sujetos es medido en todos los tiempos o momentos.
¿Cuándo podríamos estudiar el cambio? Muchos estudios se prestan a la medición del cambio. El diseño de la investigación puede ser experimental o de observación. Los datos pueden ser recogidos de forma prospectiva (se van registrando los hechos a medida que ocurren) o retrospectiva (de modo que los investigadores indagan sobre hechos ocurridos en el pasado). El tiempo puede ser medido en una variedad de unidades (meses, años, semestres, por ejemplo). El programa de recopilación de datos puede ser fijo (todos los individuos o casos se registran con la misma periodicidad) o flexible (la periodicidad de cada individuo o caso varía).
En los modelos de cambio, se necesitan datos longitudinales que describan cómo cada persona varía a través del tiempo. En los estudios transversales este análisis no se puede realizar. Los estudios que colectan dos ondas de datos mejoran comparado con los transversales. Durante un tiempo se creía que estos estudios eran suficientes para estudiar el cambio, porque el mismo estaba conceptualizado como un incremento (Singer & Willet, 2003). Luego se vio que esto era erróneo, y que el incremento no podía describirse como un proceso de cambio debido a dos razones: no nos puede decir la forma de la trayectoria de crecimiento de cada persona y no puede distinguir el verdadero cambio, de los errores de medición. Si el error de medición hace que las primeras puntuaciones sean demasiado bajas y las segundas demasiado altas, se podría concluir erróneamente que las puntuaciones aumentan con el tiempo; cuando con una perspectiva temporal más amplia podría reflejar lo contrario (Singer & Willet, 2003).
Los metodólogos indican que es necesario tener al menos tres puntos de medición longitudinal, de modo de poder diferenciar el cambio del error de medición (Rogosa et al., 1982). Al mismo tiempo, no existe en este estudio información suficientemente extendida en el tiempo para analizar otro tipo de modelos no lineales.
No todos los estudios longitudinales son susceptibles al análisis de cambio. Deben tener tres características: a) tres o más ondas de datos; b) un indicador objetivo de los efectos del paso del tiempo; y c) resultados cuyo valor cambie de forma sistemática a través del tiempo. Una vez que reconocemos que se necesitan múltiples ondas de datos, la pregunta crucial es ¿cuántas son necesarias? Varios autores consideran que a partir de tres ondas ya puede trabajarse el cambio (Singer & Willet, 2003). En general, cuantas más ondas es mejor, siempre que se consideren los costos y las limitaciones logísticas de obtenerlas. Si se tienen solo tres se deben ajustar modelos más simples, con supuestos más estrictos (en general, asumiendo que el crecimiento individual es lineal a través del tiempo). Si hay más mediciones, se pueden realizar modelos estadísticos más elaborados (Singer & Willet, 2003).
Habiendo elegido una métrica de tiempo, se tiene gran flexibilidad en relación con la separación de las series de recolección de datos. El espaciamiento de la recolección de datos por supuesto implica consideraciones de costos, beneficios estadísticos, y necesidades sustantivas. El objetivo es recolectar suficientes datos para proporcionar una visión razonable de la trayectoria de crecimiento de cada individuo. Ondas igualmente espaciadas tienen cierto atractivo, ya que ofrecen equilibrio y simetría en el estudio, pero no aportan nada más (Singer & Willet, 2003). Solo hay que tener en cuenta que si se esperan cambios no lineales rápidos durante ciertos periodos, se deben recolectar más datos en esos momentos, y si se esperan pocos cambios en otros periodos, debe espaciarse más la recolección en esos casos.
Debe elegirse al mismo tiempo una métrica plausible, y una medida del tiempo que refleje adecuadamente la cadencia que puede ser más útil en el resultado de la investigación (Singer & Willet, 2003, 11). Por ejemplo, en psicoterapia los estudios pueden cronometrar el tiempo en semanas, o en número de sesiones. Los estudios en aulas pueden medir el tiempo en grados escolares, o edades. Los estudios de conducta de los padres pueden cronometrar la edad de los padres, o la de los niños[4]. En todos los casos, la variable temporal puede cambiar solo de forma monótona, es decir, no puede cambiar la dirección.
Descripción del estudio longitudinal y del partido de Tres de Febrero
El estudio del cual obtendremos datos para el desarrollo de aspectos empíricos de los desafíos del análisis del tiempo, es un relevamiento longitudinal en el Partido de Tres de Febrero, en la provincia de Buenos Aires, realizado entre los años 2000 y 2005 en el marco de la programación científica UNTREF[5]. La investigación se orientó a comprender las condiciones que hacen más probable determinadas trayectorias de vida, y dimensionar la utilidad de la aplicación de este tipo de estudio al análisis y diseño de políticas públicas e intervención social. En el estudio se realizaron encuestas a hogares donde se captó información de todos los individuos del hogar referidos a distintos aspectos de su situación socioeconómica (ingresos, nivel educativo, inserción en el mercado de trabajo). Las categorías y operacionalizaciones de los conceptos de desocupación, actividad económica, ingresos, y otros fueron similares a los que se realizan en la encuesta permanente de hogares EPH (INDEC). Además del cuestionario individual, en cada una de las ondas del estudio se aplicó un cuestionario para los hogares. Así, varias de las elaboraciones conceptuales y conclusiones fueron presentadas en jornadas académicas[6], encuentros y publicaciones de distinto tipo[7].
La información fue captada en un período de crisis en Argentina, cuyas consecuencias impactaron sobre el mercado de trabajo, la pobreza, y distintos aspectos políticos e institucionales en el país. En 2001 una crisis financiera y política que fue la eclosión de distintas políticas económicas de la década de los `90, derivó en una restricción a la extracción de dinero en efectivo de plazos fijos, cuentas corrientes y cajas de ahorro. La crisis social impactó en el mercado de trabajo y los ingresos de los hogares (Salvia & Vera, 2011). Estos factores derivaron en una crisis política, a partir de la cual el 20 de Diciembre de 2001 se produce la renuncia a la presidencia de Fernando de la Rúa, a la que sigue un período de inestabilidad y acefalía presidencial[8]. Este contexto de crisis política y social implicó cambios relevantes en la historia y la organización política del país, y es por ello que los datos captados durante este período revisten un particular interés. Por otro lado, no se podría comprender la evolución de los datos, la alta probabilidad de transición entre pobres y no pobres, o la alta variabilidad de las trayectorias y de los ingresos, sin la referencia a este contexto de crisis.
Los datos del estudio longitudinal mencionado captan un periodo de fuerte conflictividad y caída de proporciones importantes de la población en la pobreza (2000 – 2002), evidencia empírica coherente con los estudios sobre las consecuencias del derrumbe de un régimen de convertibilidad, y del fuerte deterioro en el mercado de trabajo formal que se registró en ese período (Salvia & Vera, 2011). También, los datos marcan un proceso de recuperación entre el 2002 y 2005, pero que retrotraen en las variables estudiadas la situación al tiempo inicial, el año 2000, sin mejorar significativamente la situación respecto de este año inicial.
Partido de Tres de Febrero
Este partido es uno de los 135 partidos de la provincia argentina de Buenos Aires, en el oeste del aglomerado urbano conocido como Gran Buenos Aires. Está situado al noroeste de la Ciudad Autónoma de Buenos Aires, y fue creado en 1960 al separarse del municipio de General San Martín. Tiene una superficie aproximada de 46 km² y una población de 343.774 habitantes (la densidad poblacional es de 7.473 hab/km²) según el Censo 2010. Tres de Febrero cuenta con el 2,4 % del total de la población provincial y con el 3,9 % del total de la del Conurbano Bonaerense. En general, luego de las tasas de crecimiento elevadas entre 1970 y 1980, se observa un crecimiento demográfico bajo en el período 2001 – 2010 (2,2 %)[9]. Entre 1991 y 2001, se registró una caída poblacional de 3,69 % (aunque este dato debe relativizarse por las falencias en el operativo censal 2001). En el Cuadro 1 se muestran las estimaciones de población para el período 2001 y 2010, de acuerdo a la Dirección Provincial de Estadísticas de Buenos Aires y el INDEC.
Cuadro 1: Población total estimada al 30 de junio de cada año calendario, Tres de Febrero, Período 2001-2010.

Fuente: INDEC- DPE de la Provincia de Buenos Aires, elaborado en base a los resultados del Censo Nacional de Población, Hogares y Viviendas 2001.
Ilustración 1: Mapa del Partido de Tres de Febrero
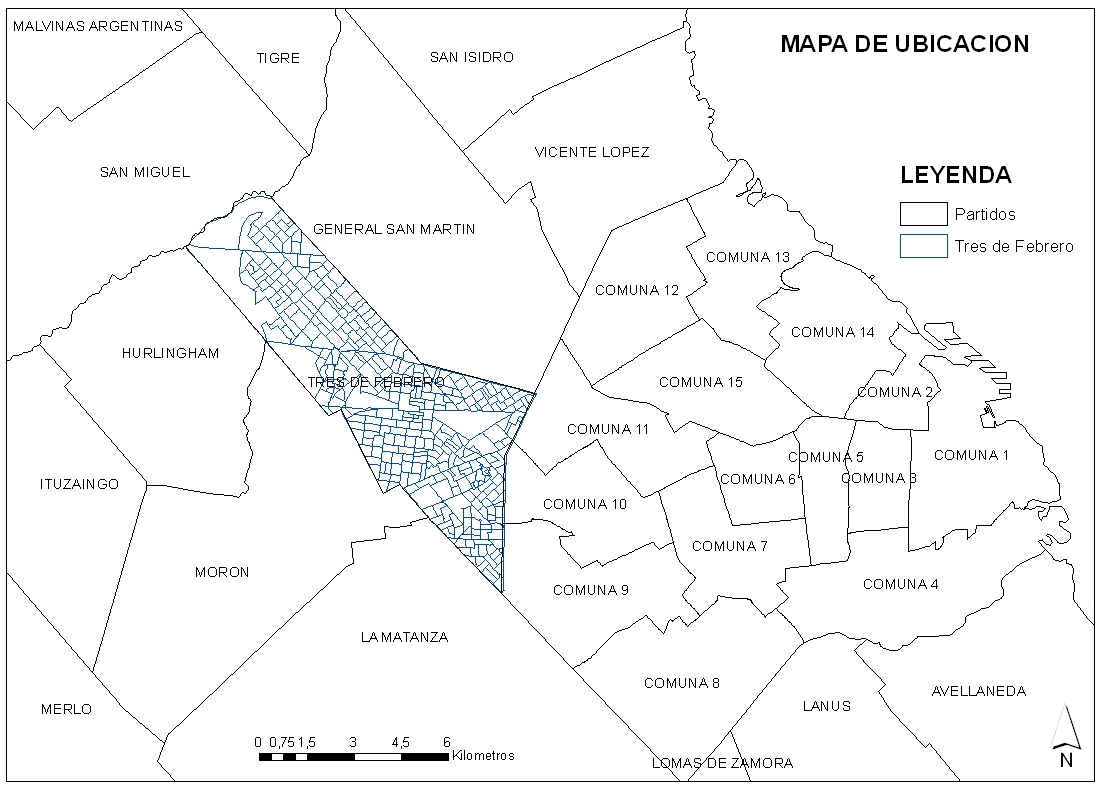
Fuente: Licenciatura en GIS. UNTREF.
Tres de Febrero consta de 15 localidades (Caseros, Churruca, Ciudad Jardín Lomas del Palomar, Ciudadela[10], El Libertador, Jasé Ingenieros, Loma Hermosa, Martín Coronado, 11 de Septiembre, Pablo Podestá, Remedios de Escalada, Sáenz Peña, Santos Lugares, Villa Bosch y Villa Raffo). Caseros es la cabecera del partido. Al oeste limita con la Capital Federal, al noroeste con el partido de San Miguel, al norte con el partido de General San Martín y al sur con la Matanza, Morón y Hurlingham. En la Ilustración 2 se puede observar la distribución de las localidades.
Ilustración 2: Localidades del Partido de Tres de Febrero
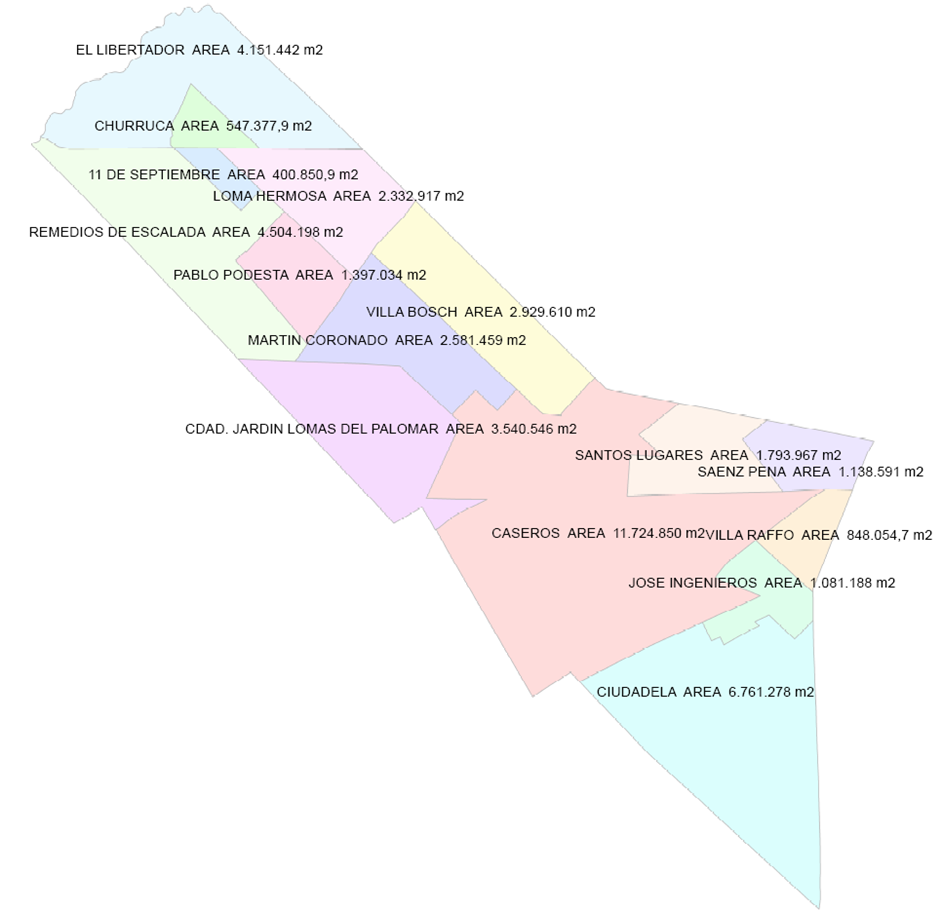
Fuente: Municipio de Tres de Febrero
La tasa de masculinidad alcanza al 90,8, algo menor al total del país (94,8). En el Censo 2010 se registraron 161.806 varones (47,6 %) y 178.265 mujeres en Tres de Febrero.
Cuadro 2: Población total por sexo y grupo de edad, Partido de Tres de Febrero. Año 2010.
Varones |
Mujeres |
|
0-4 |
11.553 |
11.320 |
5-9 |
11.825 |
11.524 |
10-14 |
11.804 |
11.398 |
15-19 |
12.441 |
12.086 |
20-24 |
12.982 |
12.995 |
25-29 |
12.917 |
13.013 |
30-34 |
12.988 |
13.367 |
35-39 |
11.657 |
11.994 |
40-44 |
9.934 |
10.514 |
45-49 |
9.553 |
10.569 |
50-54 |
9.327 |
10.610 |
55-59 |
8.637 |
10.056 |
60-64 |
7.543 |
9.318 |
65-69 |
6.075 |
7.716 |
70-74 |
4.618 |
6.850 |
75-79 |
3.862 |
6.311 |
80 y más |
4.090 |
8.624 |
Total |
161.806 |
178.265 |
% |
47,6 % |
52,4 % |
Fuente: INDEC. Censo Nacional de Población, Hogares y Viviendas, 2010.
En la pirámide poblacional se reflejan las bajas tasas de masculinidad, y una concentración de edades en los grupos etarios de 20 a 24 años. En las edades mayores aumentan las proporciones de mujeres.
Gráfico 1: Pirámide poblacional, 2010, Partido de Tres de Febrero
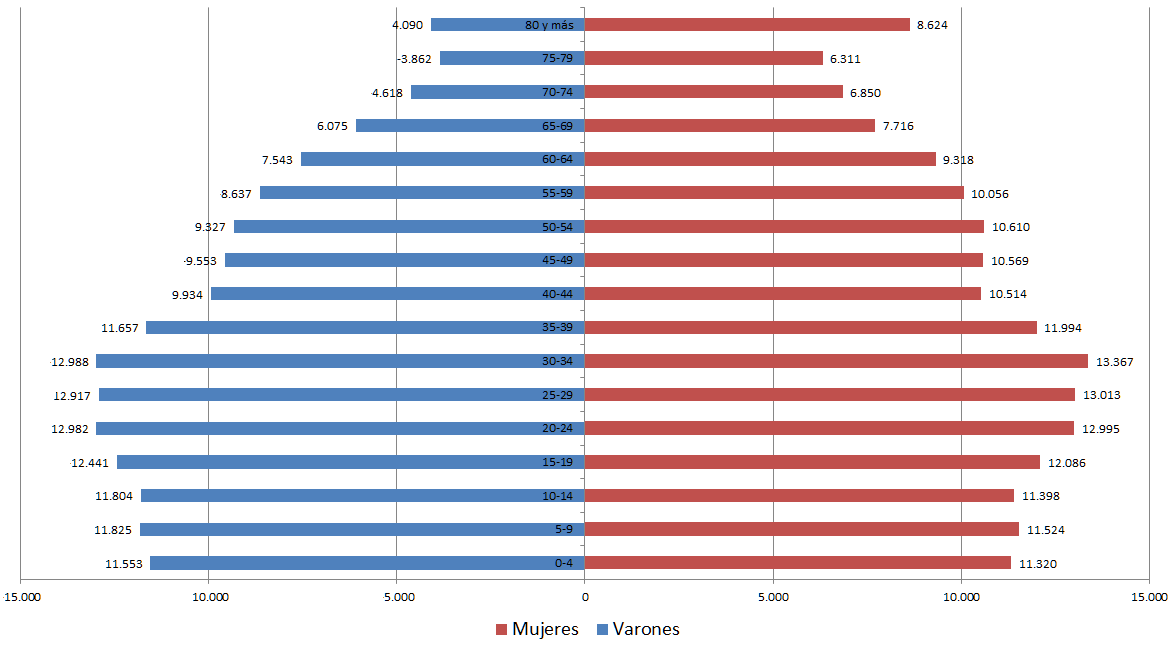
Fuente: Elaboración propia a partir de INDEC. Censo Nacional de Población, Hogares y Viviendas, 2010.
En el Censo de 2010 se registró un 92 % de individuos nacidos en Argentina, y un 8 % de residentes nacidos en otros países.
Cuadro 3: Población total por país de nacimiento, Partido de Tres de Febrero. Año 2010.
Población total |
País de nacimiento |
||
Argentina |
Otros |
||
Total |
340.071 |
312.947 |
27.124 |
100 % |
92,0 % |
8,0 % |
|
Fuente: INDEC. Censo Nacional de Población, Hogares y Viviendas, 2010.
Entre los nacidos en el extranjero en países limítrofes, predominan los paraguayos (8.441) y bolivianos (2.915). Se registraron sólo 296 residentes de nacionalidad brasileña. De los nacidos en países no limítrofes, se destaca en 2010 un volumen relativamente importante de italianos (6.498).
Cuadro 4. Provincia de Buenos Aires, partido Tres de Febrero. Población total nacida en el extranjero por lugar de nacimiento, según sexo y grupo de edad. Año 2010
Lugar |
Población |
Sexo y grupo de edad |
|||||||
Varones |
Mujeres |
||||||||
Total |
0 – 14 |
15 – 64 |
65 y más |
Total |
0 – 14 |
15 – 64 |
65 y más |
||
|
|
|
|
|
|
|
|
|
|
Total |
27.124 |
11.786 |
716 |
7.575 |
3.495 |
15.338 |
720 |
9.466 |
5.152 |
|
|
|
|
|
|
|
|
|
|
AMÉRICA |
17.622 |
7.710 |
661 |
6.291 |
758 |
9.912 |
676 |
8.001 |
1.235 |
Países |
14.794 |
6.474 |
505 |
5.241 |
728 |
8.320 |
516 |
6.607 |
1.197 |
Bolivia |
2.915 |
1.393 |
161 |
1.152 |
80 |
1.522 |
158 |
1.267 |
97 |
Brasil |
296 |
87 |
19 |
60 |
8 |
209 |
12 |
174 |
23 |
Chile |
998 |
441 |
2 |
340 |
99 |
557 |
9 |
378 |
170 |
Paraguay |
8.441 |
3.546 |
292 |
2.865 |
389 |
4.895 |
315 |
3.918 |
662 |
Uruguay |
2.144 |
1.007 |
31 |
824 |
152 |
1.137 |
22 |
870 |
245 |
Países |
2.828 |
1.236 |
156 |
1.050 |
30 |
1.592 |
160 |
1.394 |
38 |
Perú |
2.287 |
1.014 |
99 |
890 |
25 |
1.273 |
113 |
1.135 |
25 |
Resto |
541 |
222 |
57 |
160 |
5 |
319 |
47 |
259 |
13 |
EUROPA |
9.105 |
3.871 |
49 |
1.111 |
2.711 |
5.234 |
39 |
1.316 |
3.879 |
Alemania |
72 |
27 |
3 |
10 |
14 |
45 |
3 |
18 |
24 |
España |
1.781 |
734 |
22 |
184 |
528 |
1.047 |
15 |
226 |
806 |
Francia |
40 |
22 |
1 |
8 |
13 |
18 |
2 |
7 |
9 |
Italia |
6.498 |
2.792 |
18 |
797 |
1.977 |
3.706 |
13 |
947 |
2.746 |
Resto de |
714 |
296 |
5 |
112 |
179 |
418 |
6 |
118 |
294 |
ASIA |
344 |
169 |
6 |
142 |
21 |
175 |
5 |
140 |
30 |
China |
158 |
79 |
2 |
77 |
– |
79 |
– |
77 |
2 |
Corea |
23 |
13 |
– |
10 |
3 |
10 |
– |
8 |
2 |
Japón |
53 |
22 |
– |
8 |
14 |
31 |
3 |
17 |
11 |
Líbano |
9 |
5 |
– |
3 |
2 |
4 |
– |
1 |
3 |
Siria |
13 |
4 |
– |
3 |
1 |
9 |
– |
5 |
4 |
Taiwán |
45 |
25 |
– |
24 |
1 |
20 |
– |
17 |
3 |
Resto de Asia |
43 |
21 |
4 |
17 |
– |
22 |
2 |
15 |
5 |
ÁFRICA |
38 |
31 |
– |
27 |
4 |
7 |
– |
3 |
4 |
OCEANÍA |
15 |
5 |
– |
4 |
1 |
10 |
– |
6 |
4 |
Nota: se incluye a las personas viviendo en situación de calle. | |||||||||
Fuente: INDEC. Censo Nacional de Población, Hogares y Viviendas 2010.
Del total de los 112 mil hogares de Tres de Febrero, se observa que una mayoría (91,7 %) vive en viviendas con un material predominante de cerámica, baldosa, mosaico, mármol o alfombrado[11]. En general, estos indicadores se utilizan para analizar la calidad de las viviendas con indicadores estandarizados (ver Cuadro 48 en el Anexo).
Tres de Febrero contaba en 2012 con alrededor de 19 mil empresas en actividad, esto es, 5,5 empresas cada 100 habitantes, lo cual implica una densidad empresarial mayor al total provincial (3,4 cada 100 habitantes), de acuerdo a estimaciones sobre la base de datos del Ministerio de Trabajo, Empleo y Seguridad Social de la Nación, las Direcciones de Estadísticas Provinciales y el Directorio Unificado de Empresas de Tres de Febrero (Bruera, Oliva, 2012).
Metodología
En el estudio se sigue a una muestra probabilística de hogares realizado en tres ondas – en los años 2000, 2002 y 2005[12]. Las encuestas fueron aplicadas a una cohorte representativa de hogares. El universo de estudio son los hogares residentes durante el período en el área. La unidad de análisis longitudinal son los hogares con residencia habitual en el partido de Tres de Febrero en el periodo, y la unidad de observación son los individuos que viven en ellos. La muestra de viviendas particulares (unidad de muestreo) se realizó en forma probabilística, estratificada, en dos etapas. En la primera etapa se seleccionó una muestra aleatoria estratificada de 60 radios censales, con probabilidad de selección proporcional a la cantidad de viviendas.En la segunda etapa, dentro de cada radio censal elegido previamente, se subseleccionó una muestra aleatoria de 8 viviendas particulares.
En la primera onda se encuestaron a 411 hogares, en Octubre 2000. En la segunda (Octubre de 2002) se entrevistaron 243 hogares. En la tercera (Noviembre 2005 hasta Enero 2006) se reentrevistaron a los 411 hogares captados en el 2000 (dado el objetivo de construir un panel de hogares). De estos 411, fueron efectivamente encuestados 307, obteniéndose información de 953 personas; se corrigió la no respuesta al nivel de hogar (reponderando los hogares con respuesta, utilizando la información del Censo de Población 2001).La cantidad de casos efectiva para cada onda se consignan en el Cuadro 5.
Cuadro 5: Número de hogares efectivamente encuestados en las tres ondas del relevamiento 2000 – 2002 – 2005
PRIMERA ONDA – OCTUBRE 2000 |
SEGUNDA ONDA – OCTUBRE 2002 |
TERCERA ONDA – NOVIEMBRE 2005 – ENERO 2006 |
|
Hogares efectivos encuestados |
411 |
243 |
307 |
Fuente: Estudio longitudinal (UNTREF).
Dada la naturaleza de la información y el tipo de estudio que se requiere, en algunos casos se examina la información completa de cada onda. En este caso, el foco central es el análisis de los datos panel (donde sólo se incluyen aquellos individuos que pudieron ser emparejados e identificados en las tres ondas, y en general que tenían información para las variables que se siguen; es decir que esas bases de datos tienen menos casos que las encuestas completas originales). En este tipo de estudios siempre se observa disminución y atrición del panel, que en general es un proceso que no puede planificarse específicamente en el diseño inicial de la muestra[13]. Al ser un estudio de hogares, se capta información para todos los integrantes, y eso puede producir atrición; por ejemplo, si se capta información sobre un niño de 1 año en 2005 no habría información sobre el mismo en las ondas anteriores, porque no había nacido. Este factor, se suma a los otros factores de atrición que no permiten, en algunos casos, analizar la trayectoria completa[14].
A partir de la información muestral obtenida en los tres años, para lograr un seguimiento longitudinal se emparejan (o matchean) los individuos en los que fue posible captar información en los distintos momentos. Para el matcheo de los datos de 2000 a 2005 se usó el número de cuestionario y el nombre de la persona[15].
En algunos casos, los datos no pueden matchearse. Las causas más habituales para no sea posible el emparejamiento son:a) no respuesta a nivel de hogar en alguna de las ondas; b) no respuesta individual en alguna de las ondas; c) persona salida, que no está en el hogar por fallecimiento, mudanza, u otras causas; d) persona entrada, un nuevo integrante del hogar; e) hogar salido o entrado, que son nuevos hogares en la vivienda; f) error en la codificación o en la respuesta de alguna de las variables de matcheo. El punto c) es propio de una encuesta de panel y es quizás el más delicado. El reducir esta fuente de no apareamientos implica un seguimiento de las personas que abandonaron el hogar, o de los hogares que abandonaron la vivienda (Oliva & Hoszowski, 2002). Para llegar a esto se debe realizar un contacto continuo con los hogares encuestados en el período inter-ronda, que permita no solo la disminución de la reducción del panel sino también no perder de la muestra hogares o personas con un comportamiento particular: aquellos que abandonaron el hogar o los hogares que abandonaron la vivienda (Oliva, 2008).
Es necesario señalar algunas limitaciones de los datos captados en esta investigación: en principio se trata de un estudio longitudinal de pocas mediciones, realizadas sólo en tres oportunidades. El seguimiento de los individuos no se expande a un periodo largo, y sólo abarca desde los años 2000 al 2005. Esto hace difícil identificar efectos a largo plazo, y también desagregaciones muy precisas de trayectorias (por ejemplo) según variables independientes o explicativas. En el caso de los estudios aplicando modelos lineales mixtos, solo pueden ajustarse modelos lineales, siguiendo un criterio de parsimonia (Singer & Willet, 2003), y no otros posibles modelos de trayectorias más complejas (es decir que para el caso que estamos analizando, los supuestos de la evolución de los ingresos deflacionados, como se verá en siguientes apartados, deben hacerse considerando trayectorias lineales de ingresos, y se ajustarán regresiones lineales para cada individuo en el estudio de su ingreso).También, el hecho de que sea un período corto, hace dificultoso la comparación de períodos, de modo tal de identificar y diferenciar los años de crisis, los de recuperación, los períodos no críticos, y en términos más generales, los efectos a largo plazo.
Habitualmente el seguimiento de los casos en el tiempo requiere una estructura de campo que pueda realizar rastreo, revisitas a hogares, y seguimiento de individuos, que es costosa y consume tiempo. En este caso la medición del estudio longitudinal la atrición de panel y la falta de información matcheable para algunas variables, es elevada. Por ejemplo, para la variable línea de pobreza, solo tenemos un 24,8% de los datos matcheados para las tres ondas. A pesar de las distintas limitaciones los datos permiten seguir trayectorias, y ejemplificar los problemas y desafíos metodológicos.
Análisis de los datos
A partir de estos datos se realizaron comparaciones de la situación de pobreza en los tres relevamientos y un análisis de flujo, donde se describe como los mismos individuos u hogares se modifican en el tiempo (Oliva & Hoszowski, 2002). Si bien se presentarán datos de referencia del total de datos en los tres relevamientos, en particular interesa el análisis de flujo de los ingresos individuales y de la pobreza por ingresos. Mucha de esa información descriptiva y análisis de datos fue expuesta en distintas ponencias y publicaciones (Oliva, 2006, 2008; Oliva, 2010a; Oliva & Hoszowski, 2002; Oliva & Phelan, 2014).
En principio se establecerá una evolución de variables categóricas, en particular de una variable (dummy) de pobreza (pobre / no pobre) por ingreso[16]. Siguiendo las metodologías propuestas por Maletta (2002) para análisis longitudinal de datos categóricos, analizaremos las transiciones, y su asociación estadística con distintas variables. A partir de la identificación de tipologías de trayectorias, identificaremos a individuos siempre pobres, a los vulnerables (que cayeron en situaciones de pobreza en alguna de las mediciones), y a los no pobres en las tres mediciones.
En otros apartados, se analiza el ingreso de los individuos, observando su evolución y características mediante modelos lineales mixtos multinivel. Para el ajuste de estos modelos se realizan distintas imputaciones de ingreso individual, y se deflacionan los valores. En este punto nos guiaremos por distintos autores (Hsiao, 1986; Singer & Willet, 2003) que analizan los modelos lineales mixtos y multinivel; para las estimaciones de estos modelos utilizaremos el software STATA, apropiado para este tipo de análisis (Fitzmaurice et al., 2004; Kohler & Kreuter, 2012).
El análisis de flujos de pobreza y la evolución del ingreso, son de interés para analizar los cambios y transiciones en la estratificación social, y para ilustrar la aplicación de los cuatro desafíos sobre el análisis del tiempo que se esbozaron.Veremos algunas de las dificultades y problemas prácticos del análisis de este tipo de información, de modo que la reflexión pueda ser de utilidad para otros investigadores que afronten problemas similares.
Estratificación social y pobreza por ingresos
La pobreza es un fenómeno multidimensional (Salvia & Tami, 2005) y existen una variedad de abordajes conceptuales, y métodos para su medición[17]. Los más utilizados son el del NBI (necesidades básicas insatisfechas) y el de la línea de pobreza (LP, que capta las situaciones de pobreza por ingresos, más coyunturales). El método basado en la línea de pobreza (Minujin, 1997) presupone la determinación de una canasta básica de bienes y servicios (Murmis & Feldman, 1992)[18].
Una línea de pobreza absoluta corresponde a un monto de ingreso que se mantiene constante, actualizando sus montos por valores inflacionarios por ejemplo. En cambio, en la medición de pobreza relativa se compara elingreso de las familias no contra un umbral de ingresos fijo, sino contra algún punto de la distribución de ingresos del país, por ejemplo, fijando la línea en el equivalente al 50 % de la mediana de los ingresos de la población[19].
Dentro de las medidas utilizadas por los organismos internacionales, cuyo foco es principalmente la comparabilidad entre países, existen diversas metodologías. Una de ellas corresponde a la utilizada por el Banco Mundial, que se destaca por su simpleza al definir una línea de pobreza fija y constante entre países que representaría un mínimo para vivir, típicamente de US$ 1,25 al día por persona para identificar la pobreza extrema y US$ 2 para la pobreza (Grosh, Bussolo, Freije, & World Bank) — valores estimado en PPA)[20] –. En el caso de los Estados Unidos se utilizan medidas de pobreza absoluta: la línea de pobreza de EEUU (creada en 1963-1964) se basa en el costo en dólares del plan de alimentos del Departamento de Agricultura, multiplicado por un factor de 3. El multiplicador se basa en estudios que muestran que los costos de la comida representaban la tercera parte del ingreso total. Este cálculo es ajustado cada año por la inflación.
Estudios de pobreza en Argentina
El problema de la pobreza en este período ha sido estudiado por diversos autores (Garganta & Gasparini, 2012; Gasparini, Cicowiez, & Sosa Escudero, 2013), tanto en el Gran Buenos Aires como en Argentina (Camou, Tortti, & Viguera, 2007)[21]. Estos estudios sobre la evolución del fenómeno, los determinantes y las formas de medirlo fueron realizados a partir de diversos enfoques y metodologías (Garganta & Gasparini, 2012; Paz J., 2002; Salvia & Tami, 2005; Salvia, 2011a; Féliz, Deledicque, Sergio, & Storti, 2001). También se han realizado investigaciones sobre la pobreza post – crisis 2001 (Garganta & Gasparini, 2012), por ejemplo respecto del impacto de la Asignación Universal por Hijo (Garganta & Gasparini, 2012; L. Gasparini & Cruces, 2010). En el Centro de Estudios Distributivos Laborales y Sociales (CEDLAS[22]) se han realizado estudios relevantes sobre la pobreza en Argentina.
Alejo y Garganta[23] (2014) analizan mediante datos de la EPH — aprovechando el esquema de rotación muestral de este operativo — paneles sucesivos durante el período 1997-2012 para la pobreza y su evolución temporal, y la diferenciación de sus componentes transitorios y crónicos. Este estudio es de particular interés en el contexto del análisis de los estudios longitudinales que estamos abordando, porque adopta un enfoque dinámico del estudio de la pobreza.
Estos estudios sobre la pobreza ya habían sido iniciados como una corriente de investigación empírica relevante en la década de los setenta (Vallejos & Leotta, 2013). Las indagaciones teóricas y empíricas sugieren que si bien existieron factores significativos de agravamiento de la situación social y la pobreza a principios de la década del 2000, la comprensión de los fenómenos que se observan forman parte de una crisis más amplia, y de las mismas contradicciones y fluctuaciones en el desarrollo capitalista periférico (Salvia, 2001). En las décadas de los setenta y los ochenta la pobreza se extiende en la estructura social (Eguía & Piovani, 2007), suscitando entonces el interés por su estudio y reproducción (Eguía & Ortale, 2004). En este contexto surge el interrogante acerca de los modos y estrategias de los hogares más pobres para lograr reproducirse en un contexto capitalista.
“Ante este fenómeno social de pobreza urbana el análisis gira en torno a los mecanismos de reproducción de unidades familiares. Cobra relevancia el concepto de estrategias y la unidad de análisis será la unidad doméstica (Gutiérrez, 2007). Los primeros en conceptualizarla fueron Duque y Pastrana (1973) para el estudio de la clase obrera chilena denominando su objeto de análisis como estrategias de supervivencia. Sáenz y Di Paula (1981) lo nombran estrategias de existencia. Argüello (1981) utiliza estrategia de sobrevivencia. Bartolomé (1984) como herramienta conceptual utiliza la noción de estrategia adaptativa. Lomnitz (1978) por su parte, estudia las redes de intercambio recíprocos que existen en las estrategias de supervivencia (Gutiérrez, 2007). A pesar de sus diferencias y matices, estos autores comparten el foco de análisis puesto en el entrelazamiento de los factores de tipo macro-estructural y factores microestructurales, y presentan la noción de unidad doméstica como unidad de análisis nodal” (Vallejos & Leotta, 2013, 3).
Más allá del interés en la indagación de la pobreza y el énfasis en el análisis de las estrategias familiares de vida durante los 70 – 80, a principios de la década del 2000 se multiplicaron este tipo de investigaciones, dado el importante aumento de la pobreza en estos años. La pobreza que se observa a principios de los 2000 ha sido analizada en función del impacto en las estructuras sociales de la dinámica concentrada y abierta al mercado mundial del período de la convertibilidad y las reformas neoliberales de los años ´90 (Salvia, 2011). Algunos autores (Salvia & Vera, 2011) analizan en qué medida las reformas heterodoxas de la política económica post crisis y devaluación del 2001, influyeron en una reconfiguración de la estructura de empleo, en términos de diferenciales productivos y calidad de empleo. En un contexto de crisis como se registra en el período es importante señalar la vinculación de la inserción en el mercado laboral de hogares y personas con su inserción social.
“La inserción de los hogares y las personas en el medio social se realiza (en la economía capitalista) fundamentalmente a través del mercado de trabajo. Los cambios en este último condicionarán decisivamente las estrategias que los hogares puedan adoptar, ya sea con miras a su ascenso en la escala social o a la reducción de su situación de pobreza o vulnerabilidad” (Féliz, Deledicque, Sergio, et al., 2001, 5).
En estos estudios se analizan también los impactos de la pobreza a partir de un enfoque más dinámico, que pone de relieve la importancia del análisis de la vulnerabilidad frente a la pobreza, su relación con la exclusión social, y los serios trastornos que genera en la organización y estructura de los hogares y familias (Féliz, Deledicque, Sergio, et al., 2001).
Trayectorias de pobreza por ingresos
A nivel de políticas, para comprender y actuar adecuadamente sobre la pobreza se requiere una concepción dinámica del fenómeno (Féliz, Deledicque, Sergio, et al., 2001): quien hoy es pobre, mañana puede ser no pobre, e inversamente. El análisis de la estratificación social se enriquece desde una perspectiva de cambio. Por lo tanto es útil que se capte como en un determinado período de tiempo se incorporan nuevos hogares a la pobreza, y otros dejan de ser pobres. Potencialmente también podría estudiarse la transmisión intergeneracional del patrimonio (económico, cultural y simbólico); con los datos del estudio que estamos analizando esto no podría realizarse, dado que no constituyen una serie suficientemente larga para un análisis transgeneracional, y sus peculiaridades en una estructura social capitalista[24].
Enfoque dinámico de la pobreza
En las investigaciones tradicionales de pobreza es común encontrar información de determinados “stocks” o proporciones de pobreza a lo largo del tiempo. Con esta información no se pueden detectar los cambios o la historia de las personas en su vinculación con la pobreza. Con la metodología de tipo panel es posible registrar estas modificaciones. El diseño de políticas antipobreza debe contemplar que desde un punto de vista dinámico, existen dos tipos de escenarios de pobreza: una transitoria, que se asocia a una condición más bien pasajera y tal vez asociadas a ciertos shocks (pérdida de empleo), y una crónica, que se refiere a un estado permanente de pobreza relacionado con déficit estructurales (v.g. falta de educación, capacitación, enfermedad crónica o catastrófica, etc.). Lara y Beltrán Bonilla (s/d) llaman la atención, en un estudio sobre la pobreza en México, sobre la importancia de este tipo de visión dinámica de estos fenómenos:
“Este trabajo tiene como propósito analizar los nuevos enfoques en el estudio de la dinámica de la pobreza y sus posibles aplicaciones al caso mexicano. A partir de una revisión crítica de las contribuciones más recientes buscamos identificar los factores determinantes de los flujos de entrada y salida de la pobreza, así como los eventos que explican la incidencia de la pobreza crónica y la pobreza transitoria. Hasta ahora el campo de los estudios sobre pobreza ha estado dominado por la aplicación de enfoques estáticos que se han especializado en la medición del fenómeno y en la clasificación de los tipos de pobreza. Si bien se ha alcanzado un nivel de refinamiento en los métodos de medición y en la integración de una perspectiva multidimensional, los enfoques estáticos analizan la evolución de la pobreza como una sucesión de cortes transversales que da cuenta de la situación de los hogares y regiones ubicadas por debajo de las líneas de pobreza. De ahí que sea necesario complementar esta perspectiva insertando la dimensión temporal en el análisis de la pobreza mediante la utilización de datos longitudinales que expliquen sus variaciones a través del tiempo” (López & Beltrán Bonilla,2015].
Estos autores indican que desde la perspectiva de un modelo de flujos de la pobreza (basado en datos longitudinales) se parte del supuesto de que hay distintas formas de caer en la pobreza y que los hogares e individuos que experimentan la caída, son muy diferentes como también pueden serlo las vías de escape de la pobreza. En la literatura sobre el tema existe consenso en que hay una causalidad compleja que es resultado de la combinación de factores macroeconómicos, microeconómicos y de factores contingentes (shocks) los cuales inciden en los cambios de la pobreza a través del tiempo. Los factores macroeconómicos se refieren a variables como el crecimiento económico, su orientación redistributiva/concentradora, el funcionamiento del mercado laboral y la inflación, pues todos ellos afectan de manera determinante el ingreso de los hogares. En cuanto a los factores microeconómicos se consideran los procesos a nivel de hogares y su disposición de activos que afectan a los ingresos personales dentro de un determinado entorno macroeconómico. Los factores contingentes se relacionan con eventos o shocks que impactan a los hogares y aumentan su vulnerabilidad: como las enfermedades, la pérdida del jefe/jefa del hogar, la disolución de uniones y los desastres naturales. Por lo tanto, el reconocimiento de que la pobreza es un fenómeno dinámico plantea una serie de cuestiones que van más allá de la identificación de los conglomerados y regiones que se hallan por debajo de la línea de pobreza. De acuerdo con Gambetta (2007)
“para diseñar políticas de reducción de la pobreza no basta con un análisis estático, sino que es necesario entender que la pobreza es dinámica, es decir, existen hogares que son pobres en t y dejan de serlo o lo siguen siendo en t+1. Esta transición difícilmente se capta en un análisis estático que solo recoge datos para estimar indicadores de manera agregada presentando cortes transversales sobre la evolución de la pobreza, pero no aporta evidencia sobre las razones por las cuales un hogar es pobre en un período y supera esa condición en otro momento (Gambetta, 2007, 16)”[25].
También, en un estudio de la pobreza crónica y transitoria en Argentina entre 1997 y 2012 (Alejo & Garganta, 2014), se diferencian los componentes transitorios y crónicos de la pobreza, argumentando que los componentes estructurales y demográficos de los hogares, como la educación del cónyuge del jefe del hogar, son factores relevantes en la explicación del componente crónico de la pobreza.
“Aprovechando el esquema de rotación de la EPH, se construyen paneles sucesivos durante el período 1997-2012 que permiten descomponer la pobreza en sus componentes crónico y transitorio. Los resultados muestran que el factor transitorio está asociado principalmente con las características laborales, mientras que las cualidades estructurales y demográficas del hogar, y la educación del jefe y cónyuge del mismo, poseen incidencia fundamentalmente sobre el componente crónico. Sin embargo, en periodos con trayectorias divergentes de pobreza surgen diferencias considerables en los determinantes principales de cada uno de los componentes. Durante la última década, se evidencia, en particular, una caída generalizada en la incidencia relativa de las características de los hogares sobre la pobreza crónica, aun de aquellas cualidades tradicionalmente vinculadas con dicho componente” (Alejo & Garganta, 2014, 2).
El ingreso suele ser una variable incluida en la construcción de la dimensión más general de la pobreza.
Definición y abordaje del fenómeno de la pobreza
En este estudio nos enfocamos en la evolución de la pobreza por ingresos[26], y en la estimación de hogares e individuos bajo la línea de pobreza. Para ello se imputaron los ingresos faltantes, y se estipuló el monto necesario para adquirir los alimentos indispensables para satisfacer las necesidades nutricionales de un individuo estándar (definido como un hombre de 30 a 59 años de actividad moderada). Esta cifra se denomina canasta básica de alimentos (CBA) y se utilizan los datos que brindaba el organismo oficial de estadística (INDEC) sobre canastas de ingresos[27] (estas series fueron discontinuadas en 2013 – 2014). Para obtener la LP se multiplica esa CBA por el coeficiente de Engel, que indica la relación entre el valor total del consumo básico de los hogares y su consumo de alimentos. Este coeficiente se multiplica por la suma del Coeficiente de Equivalente Adulto para cada hogar. Los hogares cuyo ingreso total familiar se encuentre por debajo de su LP serán considerados pobres, al igual que todos sus miembros (es decir, no puede haber un individuo no pobre en un hogar pobre).
Las características de los hogares, al mismo tiempo, suelen ser un contexto relevante de caracterización del individuo; éstas se le adosan al individuo, y nos dicen algo relevante sobre él. La pobreza y las necesidades básicas insatisfechas son definidas empíricamente a partir de las características del hogar (Oliva, 2010a), y en ese sentido, es una característica del hogar que predica en forma significativa sobre el individuo. Para los cálculos se utilizó como valor de la Serie Canasta Básica Alimentaria del adulto equivalente el utilizado entonces por el INDEC para el Gran Buenos Aires. Para el año 2005, se utilizó como valor 124,59 $ (INDEC, 2005), y la inversa del coeficiente de Engel 2,16 — correspondientes a Diciembre 2005 –. Para los cálculos de población bajo línea de pobreza se utilizó en el año 2000 el valor de la canasta familiar de 65,89 $ por equivalente adulto, con un coeficiente de Engel de 2,35 (línea de pobreza para un adulto equivalente a 154,84 $). En 2002, la cifra de la CBA era de 231,77 $. A partir de los valores de estas canastas, los hogares cuyo ingreso total familiar se encuentre por debajo de su LP serán considerados hogares pobres y también lo serán todos sus miembros.
En el Cuadro 6 se observa la evolución de la pobreza por ingresos para las bases completas, es decir incluyendo todos los casos y no solo los casos matcheados (o emparejados).
Cuadro 6: Individuos en hogares bajo la línea de pobreza, partido de Tres de Febrero, período 2000 – 2005
Año |
|||
Individuos en hogares bajo la línea de pobreza (%) |
2000 |
2002 |
2005 |
% col. |
% col. |
% col. |
|
No pobres |
79,5 |
52,7 |
79,0 |
Pobres |
20,5 |
47,3 |
21,0 |
Total |
100,0 |
100,0 |
100,0 |
Fuente: Encuesta Longitudinal UNTREF, 2005- 2000. Bases completas.
Para estas estimaciones, se calcularon ponderadores que permiten expandir estas estimaciones muestrales al total de la población. Luego se calibró la muestra para ajustar la estimación a los datos de la población, según los resultados de las proyecciones de INDEC – DPE provincia de Buenos Aires, para el Partido de Tres de Febrero para los años 2002 y 2005.
Cuadro 7: Individuos en hogares bajo la línea de pobreza, partido de Tres de Febrero, período 2000 – 2005
2000 |
2002 |
2005 |
||||
Frecuencia |
% |
Frecuencia |
% |
Frecuencia |
% |
|
No pobres |
277.724 |
79,5 |
182.691 |
52,7 |
273.408 |
79,0 |
Pobres |
71.714 |
20,5 |
163.972 |
47,3 |
72.678 |
21,0 |
Total |
349.438 |
100,0 |
346.663 |
100 |
346.086 |
100 |
Fuente: Estudio longitudinal (UNTREF). Bases completas. Calibración por datos INDEC – DPE Provincia de Buenos Aires.
Así, para el año 2000 tendríamos 71.714 individuos que viven en hogares bajo la línea de pobreza (considerando este porcentaje para una población total de 349.438 en ese año, dato de proyección muestral obtenido por el INDEC a partir de los Censos nacionales de Población y Vivienda). Para el año 2002, el número de individuos bajo la línea de pobreza (proyectado con los mismos criterios de proyección demográfica censal) aumentó a 163.972, y para el 2005, 72.678.
En estos resultados de las bases completas de la Encuesta Longitudinal se observa en el período 2000 – 2002 un incremento de la pobreza, de + 26,8 puntos porcentuales (similar a la variación captada por la EPH entre Mayo 2000 y Octubre de 2002 para el GBA 1, que da como resultado una variación positiva de + 25,5 puntos porcentuales; esto indica una coherencia general en la descripción de la evolución y magnitud de la crisis en este período en el GBA). De acuerdo a los datos para Tres de Febrero, un 47,3 % de individuos viven en hogares pobres en el año 2002 (el INDEC midió 51,7 % del mismo indicador en Octubre de 2002). El resultado de la estimación en 2005 fue de un 21 %, un decrecimiento de 26,3 puntos porcentuales de la pobreza en Tres de Febrero respecto del año 2002. Esto fue una recuperación frente al agravamiento notable de las condiciones de pobreza que se observaron entre el 2000 y el 2002. En el período 2002 – 2005, se detecta una fuerte disminución de la pobreza, aunque se vuelve a valores similares del año 2000, registrándose un 21 % de individuos que viven por debajo de la línea de pobreza en el 2005, y un 20,2 % en el 2000. Los valores de 2005 en cuanto a porcentaje de individuos que viven bajo la línea de pobreza son similares a los del año 2000. Por lo que puede indicarse que la situación se retrotrajo a aquel año 2000, en el cual ya existían importantes volúmenes de individuos que vivían en hogares pobres.
Comparación con los datos oficiales de pobreza
No existen datos oficiales para pobreza e indigencia desagregadas para el partido de Tres de Febrero. Sin embargo, es posible analizar la información para el Aglomerado Gran Buenos Aires y los Partidos del Conurbano Bonaerense; al mismo tiempo, es posible desagregar para este último grupo al Primer y Segundo Cordón del GBA, denominados GBA1 y GBA2 respectivamente.
La Encuesta Permanente de Hogares (EPH) en el aglomerado Gran Buenos Aires (que incluye la Ciudad de Buenos Aires y los Partidos del Conurbano[28]) estimó para Mayo de 2000 un 21,1 % hogares bajo la línea de pobreza, y un 20,8 % de éstos en Octubre del mismo año. Considerando un total de 3.554.289 hogares y 11.980.667 personas en el GBA (INDEC, 2001[29]), estos porcentajes significan que para Octubre de 2000 se encontraban alrededor 740.000 hogares por debajo de la línea de pobreza, en los cuales habitaban alrededor de 3.470.000 personas. A su vez en el área había alrededor de 198.000 hogares bajo la línea de indigencia[30] (921.000 personas).
Cuadro 8: Incidencia de la pobreza y de la indigencia en el Aglomerado urbano Gran Buenos Aires (CABA y Partidos del Conurbano Bonaerense)
% |
% |
% |
% |
|
Mayo 2000 |
Octubre 2000 |
Mayo 2002 |
Octubre 2002 |
|
Línea de pobreza |
. |
. |
||
Hogares |
21.1 |
20.8 |
37.7 |
42.3 |
Personas |
29.7 |
28.9 |
49.7 |
54.3 |
Línea de Indigencia |
||||
Hogares |
5.3 |
5.6 |
16.0 |
16.9 |
Personas |
7.5 |
7.7 |
22.7 |
24.7 |
Fuente: EPH – INDEC.
Cuadro 9: Incidencia de la pobreza y de la indigencia en los Partidos del Conurbano Bonaerense
Mayo 2000 |
Octubre 2000 |
Mayo 2002 |
Octubre 2002 |
|
Línea de pobreza |
% col. |
% col. |
% col. |
% col. |
Hogares |
26,8 |
26,9 |
48,1 |
53,5 |
Personas |
35,7 |
35,0 |
59,2 |
64,4 |
Línea de Indigencia |
||||
Hogares |
6,6 |
7,3 |
21,2 |
22,3 |
Personas |
9,0 |
9,5 |
27,9 |
30,5 |
Fuente: EPH – INDEC.
Las estimaciones de la Encuesta Longitudinal de la población bajo la línea de pobreza (20,5 %) para Tres de Febrero era algo más baja en Mayo de 2000 que la del conjunto del GBA (partidos del Conurbano y Capital Federal) para la EPH, donde se observa un porcentaje de individuos que viven bajo la línea de pobreza del 29,7 %. Los datos de la Encuesta Longitudinal de la onda 2002 deberían compararse con los de la EPH en Octubre de 2002, que es aproximadamente el mes en el que se hizo la segunda onda longitudinal. En la EPH de ese mes se registraron 54,3 % de individuos bajo la línea pobreza para el total GBA, y en la Encuesta Longitudinal, 52,7 %. En general, se registran en el período valores y variaciones entre ambas fuentes que guardan cierta consistencia.
Los datos del INDEC también se tabulan desagregando los Partidos del Conurbano en GBA1 y GBA2. Se considera Primer Cordón a los partidos que tienen límites administrativos con la Ciudad Autónoma de Buenos Aires, y Segundo Cordón a los partidos del conurbano más alejados de la CABA. En el Cuadro 10 se presenta la discriminación entre el primer y el segundo cordón de los Partidos del Conurbano, integrados por los siguientes partidos:
- Primer cordón de los Partidos del Conurbano, denominado GBA1: partidos de Avellaneda, General, San Martín, Lanús, Lomas de Zamora, Morón (dividido en Morón, Hurlingham e Ituzaingó), Quilmes, San Isidro, Tres de Febrero y Vicente López.
- Segundo cordón de los Partidos del Conurbano, denominado GBA2: partidos de Almirante Brown, Berazategui, Esteban Echeverría (dividido en Esteban Echeverría y Ezeiza), General Sarmiento (dividido en José C. Paz, Malvinas Argentinas y San Miguel), Florencio Varela, La Matanza, Merlo, Moreno, San Fernando y Tigre.
Se observa que la situación social es más comprometida en el Segundo Cordón, alcanzando en Octubre de 2000 un total de 43,2 % de individuos que viven en hogares bajo la línea de pobreza.
Cuadro 10: Incidencia de la pobreza y de la indigencia desagregados para GBA 1 y GBA 2 (Primer y segundo cordón de los Partidos del Conurbano Bonaerense)
GBA 1 |
GBA 2 |
|||
Mayo 2000 |
Octubre 2000 |
Mayo 2000 |
Octubre 2000 |
|
Línea de pobreza |
% col. |
% col. |
% col. |
% col. |
Hogares |
19,3 |
19,0 |
34,4 |
34,7 |
Individuos |
26,2 |
25,1 |
44,0 |
43,2 |
línea de Indigencia |
||||
Hogares |
4,8 |
5,2 |
8,4 |
9,4 |
Individuos |
6,2 |
6,9 |
11,5 |
11,7 |
Mayo 2002 |
Octubre 2002 |
Mayo 2002 |
Octubre 2002 |
|
Línea de pobreza |
||||
Hogares |
36,8 |
41,2 |
58,6 |
64,7 |
Individuos |
47,8 |
51,7 |
68,4 |
74,4 |
Fuente: EPH – INDEC.
En el Cuadro anterior consta la desagregación de la pobreza para GBA 1 y GBA 2 de acuerdo a los datos oficiales del INDEC. En Mayo 2002 en GBA 2, el 47,8 % de las personas vivían en hogares bajo la línea de pobreza, de acuerdo a datos del INDEC[31] (Cuadro 10). En Octubre de 2002, para el GBA 2, había un total de 64,7 % de Hogares pobres, y 74,4 % de personas viviendo en hogares bajo la línea de pobreza.
La situación captada para Tres de Febrero en la Encuesta Longitudinal UNTREF tiene mayor similitud (considerando que son distintos desagregados territoriales) a la situación del conjunto del GBA 1 captado por la EPH: como se había indicado, para Tres de Febrero se calculó un 20,5% individuos bajo la línea de pobreza en 2000, mientras que para GBA 1 en Mayo de 2000, ese dato fue de 26,2 %.
Parece prudente aclarar las diferencias que se observan entre los datos para los individuos, respecto de los porcentajes de hogares. Por lo general hay más individuos que viven en hogares pobres, que hogares pobres. Por ejemplo, en Mayo 2000 para el total de los partidos del Conurbano hay 26,8 % hogares bajo la línea de pobreza y 35,7 % individuos que viven en hogares bajo la línea de pobreza (Cuadro 9). Para el GBA 2, se observa 34,4 % y 44 % respectivamente en Octubre 2000. Este fenómeno se da porque por lo general en los hogares de menor ingreso, se observa una mayor cantidad de integrantes. Para ilustrar este fenómeno a partir de evidencia empírica se muestran los datos de la EPH para el año 2006 (Oliva, 2010a).
Cuadro 11: Decil de ingreso per cápita familiar, y promedio de individuos en el hogar
Grupo decílico de ingreso |
Promedio de individuos en el hogar |
N |
Desv. típ. |
1 |
4,76 |
249 |
2,273 |
2 |
4,33 |
249 |
2,019 |
3 |
3,65 |
250 |
1,587 |
4 |
3,51 |
249 |
1,484 |
5 |
2,80 |
249 |
1,590 |
6 |
2,92 |
250 |
1,419 |
7 |
2,84 |
249 |
1,348 |
8 |
2,26 |
250 |
1,233 |
9 |
2,41 |
249 |
1,356 |
10 |
2,01 |
249 |
1,157 |
Total |
3,15 |
2493 |
1,794 |
Fuente: Elaboración propia, en base a información de la EPH – INDEC. Gran Buenos Aires, IV trimestre de 2006.
Para el 2006 en GBA los deciles con mayores ingresos por hogar per cápita (en el Cuadro 11 el código 10 corresponde al decil de mayor ingreso) poseen un promedio de integrantes por hogar menor que los deciles de ingresos bajos. En el decil 10 había en el IV Trimestre de 2006, un promedio de 2.01 individuos por hogar, mientras que los hogares pobres tienen una media de 4.76 individuos por hogar.
Ingreso necesario familiar
Como un análisis contextual, se incluyeron en las indagaciones de este estudio longitudinal preguntas sobre las expectativas de ingreso. Estas son una expresión cultural relativa a las necesidades subjetivas de recursos y servicios, que pueden tener consecuencias relevantes. De hecho, si los individuos por debajo la línea de pobreza estuviesen conformes con el ingreso que obtienen, las expectativas de que ese hogar supere el episodio de pobreza deberían ser bajas.
En esta línea de análisis se preguntó “¿cuál considera Ud. que es el ingreso necesario para su hogar?”, a todos los mayores presentes en el hogar al momento de la encuesta. Esta pregunta del ingreso necesario familiar puede considerarse un indicador de expectativas de ingreso, e indirectamente de una expresión cultural de la inserción social. El individuo evaluaría el ingreso que necesita a partir de parámetros objetivos, como los gastos habituales de manutención; pero también a partir de apreciaciones subjetivas, como sus expectativas de bienestar económico. Este indicador de ingreso subjetivo también puede tener consecuencias sobre el mercado de trabajo, ya que un individuo puede no aceptar cierto trabajo porque el monto de la remuneración no satisface su expectativa de ingreso. Del mismo modo, es posible que se capte un ingreso deseado bajo, por la consideración del encuestado de que es imposible aumentarlo (del mismo modo que los desocupados desalentados no buscan trabajo porque no creen que lo puedan conseguir).
Cuadro 12: Promedios de las variables de ingreso necesario en las tres ondas
Bases completas |
2000 |
2002 |
2005 |
Ingreso necesario familiar (en $) |
1452$ |
1366$ |
2149$ |
Fuente: Estudio longitudinal (UNTREF). No respuestas eliminadas del promedio. Valores sin deflacionar
Para estos datos, se calculó la evolución del indicador del 2000 al 2005[32]. Para el año 2005, se observa un aumento del ingreso necesario familiar, que alcanza un valor de 2149 $ (Cuadro 12). Los datos no fueron deflacionados, porque se presume que el ingreso deseado se deflaciona por la misma percepción subjetiva del individuo de la situación económica. Se observa que en el 2000, hubo en particular una caída de las expectativas subjetivas de ingreso, quizás como un efecto de la crisis del período.
El análisis del indicador sugiere nuevas preguntas, relacionadas con el impacto que tiene este registro sobre la posibilidad de movilidad social. ¿Todos los pobres quieren superar los episodios de pobreza? Si un individuo no aspira a mayores ingresos, ¿puede aumentarlos?, o ¿es posible salir de episodios de pobreza sin que el individuo lo estime necesario? Si el individuo no aspira a mayores ingresos reales que los que tiene, esto puede resultar en un problema para la dinámica capitalista[33]. Estos datos del ingreso necesario son difíciles de estudiar en forma longitudinal, puesto que refieren a un hogar que va cambiando de composición y cantidad de integrantes, y posiblemente tenga distintas interpretaciones de acuerdo a la cantidad de individuos que viven en el hogar. De todos modos, es un indicador de interés porque incorpora visiones del futuro, y expectativas (que refieren a la problemática del tiempo).
Trayectorias, eventos, estados
Como se había analizado, las tasas generales de pobreza no captan la movilidad social. Por tanto los estudios longitudinales posibilitarán obtener mejores conclusiones para las políticas, o eventualmente la toma de decisiones en materia de intervenciones para solucionar estas problemáticas sociales (Alejo & Garganta, 2014). Para esto es útil analizar las trayectorias de un grupo de individuos matcheados, o emparejados, distinguiendo trayectorias, eventos y estados en el tiempo. Es útil definir tres conceptos desde la perspectiva del análisis longitudinal de variables categóricas (Maletta, 2002, 2012):
a) el estado de una variable (categoría de una variable en la que es clasificado un sujeto en determinada ocasión),
b) el evento (un cambio de estado), y
c) la trayectoria o proceso (una serie de cambios de estado de una variable, o una serie de eventos o sucesos).
Los estados son categorías de una variable cualitativa (o valores de una variable continua) en que puede resultar clasificada cada unidad de análisis o de observación en un momento determinado. Ese estado puede ser observable o inobservable. Los eventos son los cambios de estado (manifiestos o latentes) de los sujetos[34]. Por ejemplo, si los estados son “ocupado” y “desocupado”, un evento sería el paso de una situación a otra; por ejemplo, encontrar empleo, o quedarse sin trabajo[35]. Las trayectorias no se suelen medir en forma completa (si medimos la desocupación de un individuo, es probable que no lo midamos todos los días, si no en determinadas ocasiones).
Cuando se registra el estado del sujeto en dos rondas del panel, la secuencia manifiesta o aparente (o cambio neto) es el registro de un pasaje desde su estado en la primera ronda a su estado en la segunda. Pero si el proceso subyacente opera en plazos más breves, o es un proceso continuo, podría haber una secuencia no registrada de eventos intermedios. Por ejemplo, si el sujeto estaba ocupado en ambas rondas, podría haber tenido de todas maneras algún período no registrado de desocupación en el lapso intermedio.En el Gráfico 2 ejemplificamos la situación. Suponemos que 0 es un estado de una variable (por ejemplo, ser inactivo económicamente), y 1 es otro estado (ser activo económicamente) de una variable dummy.
Gráfico 2: Representación de trayectorias reales y observadas

Fuente: elaboración propia. Datos ficticios.
En el Gráfico 2 se representan los puntos donde se han realizado mediciones y las trayectorias reales. Con los símbolos cuadrados se representan las mediciones, mientras que la línea completa representa la trayectoria real. La situación que se simboliza es que una parte de las trayectorias queda fuera de la captación empírica, y algunos de los eventos que pudiesen haber ocurrido en las trayectorias podrían no haberse registrado.
Trayectorias de pobreza
Para lograr un seguimiento longitudinal de los estados, eventos, y procesos, se emparejaron (o matchearon) los individuos en los que fue posible captar información en los distintos momentos, para identificarlos a lo largo de las distintas ondas. En este tipo de procedimientos se suele observar una disminución[36] y atrición del panel. Es posible relacionar las variaciones de las trayectorias con ciertas condiciones finales o iniciales de inserción en el mercado de trabajo, o el nivel educativo. A partir de la base de datos con los casos matcheados – en la cual se registraron 3.044 estados en relación a la línea de pobreza[37] – se construyó la evolución de la incidencia de la pobreza para las tres ondas.
Cuadro 13: Individuos en hogares bajo la línea de pobreza en el partido de Tres de Febrero según años
AÑO |
TOTAL |
|||||
2000 |
2002 |
2005 |
||||
Individuos en hogares bajo la línea de pobreza |
NO POBRES |
CASOS |
1013 |
396 |
753 |
2162 |
% |
78,2% |
49,8% |
79,0% |
71,0% |
||
POBRES |
CASOS |
283 |
399 |
200 |
882 |
|
% |
21,8% |
50,2% |
21,0% |
29,0% |
||
TOTAL |
CASOS |
1296 |
795 |
953 |
3044 |
|
% |
100,0% |
100,0% |
100,0% |
100,0% |
||
Fuente: Estudio longitudinal UNTREF. Base matcheada.
Se observa en el Cuadro 13 que entre 2000 – 2002 hubo un incremento de la pobreza (considerando las bases con casos matcheados, los resultados obtenidos son relativamente coincidentes con los del Cuadro 6, donde se consignaba la evolución de la pobreza a partir de las bases completas). Se observa que en el año 2000 había un 21,8 % de individuos en situación de pobreza (Cuadro 13), y que este valor se incrementa a 50,2 % en el año 2002.
Gráfico 3: Individuos en hogares bajos la línea de pobreza en el partido de Tres de Febrero según años

Fuente: Estudio longitudinal UNTREF. Base matcheada.
En el año 2002 se registraron más individuos pobres por ingresos (50,2 %) que no pobres (49,8 %), lo que da cuenta de la dimensión de la crisis social de este periodo. En el período 2002 – 2005, se detecta una fuerte disminución de la pobreza, aunque se vuelve a valores similares del año 2000, registrándose un 21% de individuos que viven por debajo de la línea de pobreza en el 2005, y un 21,8 % en el 2000. Esta información revela un fuerte deterioro en las condiciones de vida de buena parte de la población, que se suma a los hogares que ya tenían carencias de tipo alimentaria y de acceso a bienes y servicios en el año 2000. Esta información es consistente con lo señalado por autores como Dedlique, Féliz y Sergio (2001):
“Hacia fines del año 2000, cerca de dos tercios de los hogares argentinos eran pobres o vulnerables a la pobreza en el corto plazo debido a la insuficiencia de ingresos y a la gran volatilidad de los mismos. Esto es consecuencia de las profundas transformaciones económicas de la década de los ’90, donde las fluctuaciones macroeconómicas se transmiten ya no vía cambios en los precios sino fundamentalmente a través del mercado laboral” (Deledicque, Féliz y Sergio, 2001, 5)”.
Este detrimento de la situación social puede explicarse por las modificaciones ocurridas dentro del mercado de trabajo, como así también por la caída de los ingresos que tuvieron las personas que mantuvieron sus trabajos –incluso en los puestos de trabajo más formales (Salvia & Vera, 2011) — , en una época de crisis social y política en Argentina[38].
Identificando las trayectorias 2000, 2002 y 2005, se pueden aplicar análisis estadísticos para describir trayectorias de pobreza. Estas trayectorias pueden ser agrupadas en tipologías de acuerdo a distintos intereses analíticos (por ejemplo, “trayectorias donde mejora la calidad de vida”, “trayectorias de empeoramiento de la calidad de vida”). Para este estudio clasificaremos a los trayectos en tres categorías: a) no pobres (siempre fueron no pobres), b) vulnerables (cayeron en algún momento en situaciones de pobreza), y c) pobres crónicos (pobres en las tres ondas).
Número de trayectorias posibles
Un aspecto relevante de este análisis es identificar el número de posibles trayectorias, que depende de la cantidad de estados y de mediciones que se hayan realizado. Si hay dos estados (A y B) para dos ocasiones las trayectorias posibles son: A→A, A→B, B→A y B→B[39]. En general, cuando hay k estados el número de las trayectorias posibles entre dos períodos es k². Por eso para dos estados (k=2) hay 2²=4 trayectorias, para tres estados hay 3²=9 trayectorias, y así sucesivamente[40].
En el caso del estudio longitudinal que estamos analizando hay dos estados medidos (pobre / no pobre) para tres mediciones (2000, 2002 y 2005), y por lo tanto tenemos k³, es decir 2³=8 trayectorias posibles. Si además de haber más rondas hay también más estados posibles, el número de trayectorias rápidamente se eleva[41].
Existen también lo que se llaman trayectorias imposibles, por ejemplo en el caso de los estados civiles; ningún soltero puede pasar a ser viudo directamente, sin pasar por el estado casado[42]. En este caso de estudio, no encontramos trayectorias imposibles, porque todos los individuos podrían pasar de ser pobres a no pobres, y viceversa. Desde el punto de vista del problema A mencionado en los apartados anteriores entre los desafíos del análisis del tiempo, la existencia de un proceso irreversible implicaría en principio que algunas trayectorias de todas las posibles no se verificarían (por ejemplo, un individuo que pase de un nivel educativo secundario completo a uno primario incompleto), o serían altamente improbables (por ejemplo, que un hogar pase de utilizar un televisor color a uno blanco y negro no es imposible, pero es poco probable).
Bases de datos de nivel personas, y persona período
Luego de matchear en una sola base de datos los individuos con sus mediciones de pobreza para los tres años, es necesario organizar los datos longitudinales. En un análisis transversal todo lo que se necesita es una base de datos estándar en la cual cada individuo tenga su registro (Singer & Willet, 2003). En los análisis longitudinales la organización de la base de datos es menos sencilla, porque se pueden utilizar dos modalidades diferentes:
- Un conjunto de datos a nivel personas (person level), en la cual cada persona tiene un registro y múltiples variables contienen los datos de cada medición. Este tipo de formato tiene tantos registros como personas hay en la muestra; cada individuo tiene un solo registro (una sola fila) para todas las ocasiones, y los distintos valores de las variables seguidas se observan en distintas columnas de las bases de datos[43].
- Un conjunto de datos con formato persona – periodo (person period), en cual cada persona tiene múltiples registros, uno para cada medición (a veces se denomina este formato como persona-tiempo). Este tipo de formato tiene muchos más registros; uno para cada combinación de persona con un determinado periodo. Y a medida que se recogen las ondas adicionales de datos, el archivo gana nuevos registros, pero no nuevas variables. Una base de datos en este formato tiene una estructura donde cada individuo tiene un registro por cada ocasión en la que se midió información panel (en este caso, tres años)[44].
Por ejemplo, si los datos de ingreso están en el formato que se observa en el Esquema 1 (nivel personas), luego pueden transformarse a formato persona – periodo (Esquema 2).
Cuadro 14: Esquema 1, bases de datos para datos longitudinales en el formato nivel personas
Individuo |
Condición actividad 2000 |
Condición actividad 2002 |
Condición actividad 2005 |
Ingresos familiares 2000 |
Ingresos familiares 2002 |
Ingresos familiares 2005 |
1 |
1 |
2 |
1 |
2000 |
1500 |
2500 |
2 |
1 |
3 |
2 |
1520 |
1000 |
2800 |
Fuente: elaboración propia, datos ficticios
Este formato persona – período en general es más útil para analizar las relaciones entre las variaciones de las variables (Singer & Willet, 2003). Habitualmente los distintos paquetes de software estadístico pueden convertir fácilmente una base de datos de un formato a otro[45].
Cuadro 15: Esquema 2, bases de datos para datos longitudinales en el formato persona – período
Individuo |
Condición de actividad |
Ingresos familiares |
1 |
1 |
2000 |
1 |
2 |
1500 |
1 |
1 |
2500 |
2 |
1 |
1520 |
2 |
3 |
1000 |
2 |
2 |
2800 |
Fuente: elaboración propia, datos ficticios
El segundo formato (persona – periodo) permite analizar la covariación de los predictores con las variables dependientes, y lo utilizaremos en el ajuste de modelos lineales mixtos. Toda base de datos persona-periodo suele tener cuatro tipos de variables:
1) Identificadora del sujeto: el número de identificación (ID), el cual identifica al sujeto que cada registro describe, aparece generalmente en la primera columna. Este número es una parte integral de este análisis ya que, además de identificar al sujeto, es idéntico a través de los múltiplos registros de cada persona. Sin esta identificación no se puede clasificar el conjunto de datos en subconjuntos específicos de personas.
2) Indicadora del tiempo: en este tipo de base de datos hay un indicador del tiempo que identifica la ocasión específica de medida que el registro describe. Este tipo de variable también permite acomodar diseños de investigación en los cuales el número de ocasiones de medición difiere entre las personas. Cada persona cuenta con tantos registros como ondas haya registrado.
3) Variables de resultados: cada resultado en un conjunto de datos persona-período está representado por una sola variable. Los valores representan la puntuación de esa persona en cada ocasión.
4) Variables predictoras: un conjunto de datos persona-período puede incluir tantos factores predictivos como se desee. Cada predictor también está representado por una sola variable y pueden ser variables o invariables en el tiempo. Los predictores invariantes en el tiempo tienen valores idénticos en los múltiples registros de cada persona, mientras que los predictores que varían en el tiempo registran valores potencialmente diferentes.
En principio, al agregar los datos en una sola base, encontramos que hay individuos con información sobre la situación de pobreza para uno, dos, o tres años. Esto se detalla en el Cuadro 45 del anexo donde consta cómo se ha distribuido la cantidad de casos en las distintas ondas. Esta base de datos está en formato de nivel – persona, es decir que habrá un solo registro para el individuo en la base de datos, y en la cual variable pobreza para cada año será registrada en tres columnas distintas.
Cuadro 16: Atrición del panel en la variable individuos bajo la línea de pobreza 2000, 2002 y 2005.
Casos |
% |
|
Datos en los 3 años |
428 |
24,8 |
En 2 años |
464 |
26,9 |
En 1 año |
832 |
48,3 |
Total |
1724 |
100,0 |
Fuente: Estudio longitudinal UNTREF. Base matcheada
En el formato nivel persona hay 1.724 individuos con registros de situación respecto de la pobreza en alguna de las tres mediciones. En estos casos matcheados puede haber registros de pobreza para un año (n = 832), dos (n= 464), o para tres (n = 428) años. Existen varios factores por los cuales no sea posible registrar información en alguna de las tres mediciones. Entre otros, la edad; si se capta información sobre un niño de 1 año de edad en 2005, éste no había nacido en 2000 o 2002 y no habría información en las ondas anteriores.
El problema se suma a los otros factores mencionados anteriormente de atrición del panel[46], generando nuevas problemáticas a solucionar en los análisis o en las indagaciones empíricas.
Descripción de las trayectorias
No siempre es necesario analizar todas las trayectorias posibles; podemos simplificar o agruparlas, sobre todo en el caso de que las muestras no sean lo suficientemente importantes para desagregaciones muy específicas, o exista una alta atrición del panel. Una posible periodización de trayectorias la podríamos obtener por ejemplo, si no utilizamos el tiempo intermedio (el año 2002), y solo utilizamos el punto inicial (2000) y el final (2005). En este caso tendremos cuatro categorías de trayectorias (Oliva, 2010a; Oliva & De Angelis, 2014)[47].
En este caso, se utilizó otro agrupamiento de las tipologías que incluyen el punto intermedio 2002 (siempre considerando las necesidades analíticas, la alta atrición del panel, y los casos que finalmente se obtienen de trayectorias completas). Si simbolizamos P como pobre, y NP como no pobres, estas trayectorias se representan en el Cuadro 17.
Cuadro 17: Resumen de las posibles trayectorias de la pobreza 2000, 2002 y 2005
NP2000 – NP 2002 – NP2005 |
NP 2000 – NP 2002 – P 2005 |
P2000 – NP 2002 – NP2005 |
P 2000 – P 2002- NP2005 |
NP2000 – NP 2002 – P2005 |
NP2000 – P 2002- P2005 |
P 2000 – NP 2002 – P2005 |
P2000 – P2002 – P 2005 |
Fuente: elaboración propia
El Cuadro 18 refleja los resultados de la tabulación del estado de los individuos desagregados en los tres años de acuerdo a las variables de pobreza.En este cuadro se calculan los porcentajes sobre el total de los casos emparejados en los que obtuvo información para las tres ondas (n= 428).
Cuadro 18: Incidencia de la pobreza 2000, 2002 y 2005
Incidencia de la Pobreza 2005 |
Incidencia de la Pobreza 2002 |
Total |
||||
No pobres |
Pobres |
|||||
No pobres |
Incidencia de la Pobreza 2000 |
No pobres |
Casos |
195 |
94 |
289 |
% Total |
45,6% |
22,0% |
67,5% |
|||
Pobres |
Casos |
13 |
39 |
52 |
||
% |
3,0% |
9,1% |
12,1% |
|||
Total |
Casos |
208 |
208 |
133 |
||
% del Total |
61,0% |
48,6% |
31,1% |
|||
Pobres |
Incidencia de la Pobreza 2000 |
No pobres |
Casos |
11 |
38 |
49 |
% |
2,6% |
8,9% |
11,4% |
|||
Pobres |
Casos |
4 |
34 |
38 |
||
% |
0,9% |
7,9% |
8,9% |
|||
Total |
Casos |
15 |
15 |
72 |
||
% |
17,2% |
3,5% |
16,8% |
|||
Total |
428 |
|||||
Fuente: Estudio longitudinal UNTREF. Base matcheada, 428 casos donde se obtuvo información matcheada para las tres ondas.
Considerando las tres ondas, un 7,9 % del total de individuos fueron pobres en las tres (aquí los llamaremos pobres crónicos). Este grupo posiblemente es el que requiere una mayor atención desde el punto de vista de las políticas públicas, o las iniciativas sociales para el mejoramiento de su situación social. Del total de los individuos, hubo un 45,6 % que fueron no pobres en todas las mediciones.
A partir de esta información, podemos reagrupar las trayectorias para simplificar el análisis. Una opción sería clasificar a estas trayectorias según una apreciación cualitativa de positivas y negativas. Por ejemplo P2000 – NP 2002 – NP2005 sería positiva en el sentido de que el individuo salió del episodio de pobreza entre el 2002 y 2005; mientras que NP2000 – NP 2002 – P2005 seria negativa porque el individuo terminó siendo pobre al final del período después de dos años en los que no era pobre. Esto sin embargo podría traer problemas de interpretación en contextos como el de este periodo estudiado, en donde existió una crisis social y alta fluctuabilidad en los ingresos. En lugar de clasificarlas como positiva o negativa, parece más útil considerar a quienes sufrieron algún episodio de pobreza en los tres años como individuos vulnerables, es decir que potencialmente pueden caer en la pobreza (si bien existen distintos enfoques sobre el término vulnerabilidad, y no hay una formulación de indicadores estandarizados sobre este término). Aunque hayan salido del episodio de pobreza, es posible que estén en peligro de caer otra vez en esta situación – para una discusión interesante sobre vulnerabilidad y exclusión social, y si la vulnerabilidad es una antesala a la pobreza, ver Féliz (2001) –.
Los individuos que siempre estuvieron en la pobreza, podrían considerarse algo similar a pobres crónicos — no utilizaremos aquí para éstos el término pobres estructurales, un concepto que si bien ha sido operacionalizado de distintos modos, habitualmente identifica a los individuos que viven en hogares con necesidades básicas insatisfechas (Minujin, 1997) [48], y es una categoría utilizada en estadísticas oficiales –. Los que han transicionado en alguno de los puntos de pobres a no pobres o viceversa, se podrían catalogar como individuos vulnerables (en el sentido de que, si ya estuvieron en ese estado en alguno de los puntos medidos, pueden caer nuevamente en episodios de pobreza). Los no pobres en los tres períodos, puede conceptualizarse como población no vulnerable.
Hay que precisar que el indicador de pobreza también puede tener una alta fluctuabilidad debido al hecho de que se puede superar el valor de la línea de pobreza familiar por un monto muy pequeño de dinero. Por ejemplo si la canasta básica para un hogar A de cuatro individuos fuese de 400 $, y el ingreso familiar total fuera 401 $, ese hogar A supera la canasta básica por 1 peso, y en la estadística se captará como un hogar no pobre. Al mismo tiempo, si un hogar B, con la misma cantidad de integrantes, obtiene un ingreso familiar de 20.000 $ — superando por 19.600 $ el monto de la canasta familiar –, también quedara clasificado como no pobre. Pero al mismo tiempo, para el hogar A es más probable que su categorización como pobre o no pobre fluctúe de una medición a otra.
Se podría optar, en vez de utilizar una variable dicotómica (0-1) de pobreza, por una variable cuantitativa de intervalo que refleje la diferencia entre el ingreso per cápita familiar y la canasta básica. Esto permitiría captar variaciones en el dinero le falta al ingreso familiar para salir del episodio de pobreza. A partir de esta variable el análisis de trayectoria se puede realizar distintos análisis como variable de tipo intervalo. Una vez organizadas las trayectorias, es posible observar su evolución de acuerdo a algunas variables que pueden resultar relevantes, y también analizar la probabilidad de transición en un período y otro. En este caso, tomaremos las referencias de las trayectorias del siguiente modo: 1) pobre en las tres mediciones P2000 – P2002 – P 2005 (pobres crónicos) , 2) en algunos de los años fue pobre, y en otros no pobre (vulnerables socialmente) y 3) no pobre en las tres mediciones — NP2000 – NP 2002 – NP2005 – (no pobres). El Cuadro 19 muestra la distribución de frecuencias para estas tres categorías.
Cuadro 19: Trayectorias resumidas de pobreza en el partido de Tres de Febrero entre 2000 y 2005
Frecuencia |
Porcentaje válido |
|
Pobre en las tres ondas (crónicos) |
34 |
7,9 |
Otras trayectorias (vulnerables) |
199 |
46,5 |
No pobre en las tres ondas |
195 |
45,6 |
Total |
428 |
100,0 |
Fuente: Estudio longitudinal UNTREF. Base matcheada, 428 casos donde se obtuvo información matcheada para las tres ondas.
La característica de los vulnerables (que representan un 46,5 % de la muestra) es que podrían caer en distintos momentos en situaciones de pobreza por ingreso.
Gráfico 4: Trayectorias resumidas de pobreza en el partido de Tres de Febrero entre el 2000 y el 2005 (%)

Fuente: Estudio longitudinal UNTREF, 428 casos donde se obtuvo información matcheada para las tres ondas.
En el Gráfico 4 se observa la distribución de estos grupos. Se puede observar que la cantidad de individuos “en riesgo de ser pobres”, es mayor que la cantidad de pobres habitualmente captado en un estudio transversal sobre pobreza. En este caso, sumando a crónicos y vulnerables, obtenemos un 54,4 % de las trayectorias observadas como individuos en situación de pobreza o que pueden caer con probabilidad alta en ella.
Autores como Feliz (2001) han señalado un cambio en la década de los 90, hacia una problemática central referida a la vulnerabilidad frente a la pobreza. La vulnerabilidad tiene efectos en las expectativas de inversión (en algunos casos en ítems relevantes como la educación), en la organización de los hogares, sus estructuras y en las expectativas a futuro.
“Si en los ochenta la principal fuente de incertidumbre fue la inflación (que dificultaba la optimización de los patrones de gasto), en los noventa la vulnerabilidad frente a la pobreza (y la pobreza misma) es uno de los problemas sociales más urgentes. La vulnerabilidad frente a la pobreza altera no sólo las decisiones de gasto e “inversión” (en particular, aquellas de largo plazo e importancia vital para el desarrollo económico, tales como las inversiones en educación) sino que provoca serios trastornos en la organización de los hogares, desestructurando las familias y aumentando la angustia y la desesperanza” (Féliz, Deledicque, 2001, 5).
La vulnerabilidad es también un problema en el sentido de que los individuos se ven compelidos a insertarse en el mercado de trabajo en condiciones desfavorables[49], como indica Feliz (2001).
Trayectorias de pobreza y nivel educativo
¿Cómo sería el ordenamiento temporal razonable de causas y efectos, o variables independientes y dependientes, dada una serie de trayectorias en un cierto tiempo con un estado inicial y otro final? El problema es establecer si el estado final de una trayectoria puede relacionarse con factores antecedentes en el tiempo, y cuánto tiempo atrás puede considerarse que un evento puede tener influencia sobre un estado actual. En otros términos, como interpretar variaciones no concomitantes.
Se supone que dada una trayectoria entre dos puntos en el tiempo en la vida de un individuo, hay distintos eventos que ocurren que podrían ser igualmente explicativos o estar asociados estadísticamente con su situación actual; en este caso a la situación de pobreza por ejemplo. Esto tiene relación con el Desafío D, referido al ordenamiento temporal de causas – efectos y variables independientes – dependientes.
Para analizar las trayectorias de acuerdo al nivel educativo, se tomará el estado final de esta variable, es decir, el del año 2005. Si se hubiera tabulado a las trayectorias por el nivel educativo del año 2000, al inicio del panel, tendríamos el problema de que no sabemos si un individuo que tiene un determinado nivel educativo en el 2000 terminó sus estudios en el 2005.
También es un problema con los datos de los niños que son típicos en las encuestas a hogares. En un período de vida que va, por ejemplo, desde los 5 hasta los 10 años, las secuencias de eventos significativos y causalidades no serían lo mismo que para ese individuo entre los 20 y 25 años, o entre los 50 y 55, y así.
Otro problema es atribuir un efecto a una causa anterior en el tiempo. Por ejemplo, imputar al estado de una variable en el año 2000 una consecuencia que ocurre en el 2005 (en este caso de estudio). Como se había referido en el Desafío D, a mayor distancia temporal entre la causa y el efecto, este problema es más significativo: atribuirle un efecto a una causa ubicada hace muchos años es más incierto que atribuir un efecto a una causa inmediatamente anterior (concomitante).
Cuadro 20: Trayectorias resumidas de pobreza según nivel educativo en 2005
Nivel educativo 2005 |
Total |
||||||
Situación |
Primario incompleto |
Primario completo – secundario incompleto |
Secundario completo – terciario universitario incompleto |
Universitario completo – posgrado |
|||
Pobre en |
Casos |
11 |
21 |
2 |
0 |
34 |
|
% según Nivel educativo 2005 |
13,9% |
11,3% |
1,4% |
,0% |
7,9% |
||
Otras |
Casos |
33 |
92 |
71 |
3 |
199 |
|
% según Nivel educativo 2005 |
41,8% |
49,5% |
48,3% |
18,8% |
46,5% |
||
No pobre |
Casos |
35 |
73 |
74 |
13 |
195 |
|
% según Nivel educativo 2005 |
44,3% |
39,2% |
50,3% |
81,3% |
45,6% |
||
Total |
Casos |
79 |
186 |
147 |
16 |
428 |
|
% según Nivel educativo 2005 |
100,0% |
100,0% |
100,0% |
100,0% |
100,0% |
||
Fuente: Estudio longitudinal UNTREF.Base matcheada, 428 casos donde se obtuvo información matcheada para las tres ondas.
Considerando estas problemáticas, podemos tabular las trayectorias de pobreza, con relación a un estado final en 2005 del nivel educativo. Esta tabulación permite establecer alguna asociación estadística entre la trayectoria observada, y el estado actual. En la clasificación de la trayectoria, de todas maneras, hemos incorporado el proceso de cambio en el tiempo (que no se hubiese captado sólo tabulando la pobreza de 2005 versus el nivel educativo en ese año).
En el Cuadro 20 se observa que entre los individuos que tenían un bajo nivel educativo en el 2005, hay una mayor probabilidad de que hayan tenido una trayectoria de pobreza en los tres años estudiados. Por ejemplo entre los individuos que tenían primario incompleto en 2005, un 13,9 % habían sido pobres en las tres ondas, mientras que solo el 1,4 % y el 0 % habían sufrido esa trayectoria entre los individuos de universitario incompleto y completo / posgrado. Estas conclusiones son del tipo de confirmación de asociación estadística. Es decir, sabemos que ambos estados están relacionados, aunque no podemos decir si se trata de una relación causal, con todas las discusiones que este término implica (Marradi, 2002) .
Tomar el dato de nivel educativo en el final de la serie (en este caso el año 2005) puede reducir la capacidad analítica que ofrecen los estudios longitudinales, si la variable que potencialmente es explicativa o independiente presenta muchas fluctuaciones en una serie de datos más larga. Pero sabemos que el cambio del nivel educativo formal resulta un proceso irreversible. En la educación formal registramos efectos irreversibles: no se vuelve a un nivel educativo formal inferior.Y por ello, las variaciones tendrán un solo sentido: hacia el aumento del nivel educativo formal. Si bien la variable no es un efecto fijo en el tiempo[50] como podría ser el sexo (que no varía con el tiempo habitualmente), la variable nivel educativo formal varía en un solo sentido, y en forma irreversible (esto era lo que habíamos planteado como Desafío A, la identificación de la presencia de procesos irreversibles). Es decir, en este caso hay trayectorias imposibles, en los términos discutidos en párrafos anteriores: por ejemplo no puede haber una transición de secundario completo, a primario incompleto. Podemos revisar esta afirmación mediante evidencia empírica, para hacer el proceso más claro o evidente. En el Gráfico 5 se consigna la evolución de los datos de nivel educativo para cada individuo, para algunos de los casos analizados en el estudio longitudinal en 2000 y 2005.
Gráfico 5: Nivel educativo por año – individuos en el panel
Fuente: Estudio longitudinal (UNTREF). Base matcheada con registros para los tres años (n=1104).
Para los individuos en un período breve de cinco años, lo más habitual es que el nivel educativo se mantenga estable; los individuos cuya trayectorias se muestran en el gráfico quedan en la misma categoría, pero nunca bajan en el nivel educativo[51]; eventualmente (en los más jóvenes, o en los niños en edad escolar) algunos pasan a un escalón superior en el sistema educativo formal, pero nunca van a descender en él. Así, como se observa en el Gráfico 5, la evolución de la educación formal resulta irreversible.
En el Cuadro 21 se consigna la distribución de los datos del nivel educativo. Como se había explicado, si registramos estados de la variable pobreza en el formato persona periodo, cada individuo aporta tres registros, por lo tanto la base tiene 5.172 registros, valor que se obtiene de multiplicar 1724 casos * 3 (años). De los 5.172 registros matcheados, se observan 1.104 con información en los tres paneles. Es decir, que sólo el 21,3 % (1.104) de los registros son utilizables para el análisis de trayectorias completas de nivel educativo. Hay muchos factores que influyen en estos temas de captación y atrición del panel, y de falta de información en algunas variables.
Cuadro 21: Número de datos matcheados en relación al nivel educativo para los tres años
Frecuencia |
Porcentaje |
|
Datos para los 3 años |
1104 |
21,3 |
2 años |
1464 |
28,3 |
1 año |
2517 |
48,7 |
Sin datos |
87 |
1,7 |
Total |
5172 |
100,0 |
Fuente: Estudio longitudinal UNTREF. Base matcheada en formato persona periodo, 5.172 registros.
De todas maneras, es importante aclarar que la imputación de los efectos del nivel educativo de los individuos sobre las transiciones de la pobreza es difícil. Esto es así porque la educación es una característica del individuo, mientras que la pobreza es una característica del hogar que predica sobre el individuo. La transición de pobreza a no pobreza puede haberse verificado por la pérdida de trabajo del jefe de hogar, o por la incorporación de integrantes del hogar inactivos al mercado de trabajo, y muchas otras situaciones que no dependen solamente del individuo en particular y su nivel de estudios; en realidad, depende en todo caso de su nivel educativo y además de las conductas, estrategias y decisiones de vida de todo el grupo familiar.La dificultad esta entonces en atribuir un cambio al nivel individual, al nivel grupal del hogar (esto se aplica a distintas variables), como discutiremos en párrafos siguientes[52].
Transiciones de pobreza y mercado de trabajo
También se analizó la relación de las trayectorias con las características de la inserción en el mercado de trabajo, considerando para ello las categorías de condición de actividad, en particular: ocupado, desocupado e inactivo (al conjunto de ocupados y desocupados se los considera población económicamente activa[53]). Para el estudio de temas relativos al mercado de trabajo, es conveniente quitar del análisis a los menores de edad, dado que ellos no suelen estar insertos en el mercado de trabajo, y por lo tanto no es útil estudiar entre ellos segmentaciones y condicionantes para esta inserción. La tabulación completa de trayectoria de pobreza respecto de la condición de actividad, con todos los casos matcheados (incluídos los menores) se consigna en el Cuadro 49 del Anexo. En el Cuadro 22 se observan los datos de las trayectorias según condición de actividad para los mayores de 14 años que pudieron ser matcheados en las tres ondas.
Cuadro 22: Trayectorias resumidas de pobreza según condición de actividad en 2005 (Mayores de 14 años).
Condición de actividad 2005 |
Total |
|||||
Ocupados |
Desocupados |
Inactivos |
||||
Situación en línea de pobreza |
Pobre en las tres mediciones (Pobres crónicos) |
Casos |
10 |
4 |
11 |
25 |
% filas |
40,0% |
16,0% |
44,0% |
100,0% |
||
% columnas |
5,1% |
21,1% |
6,2% |
6,3% |
||
Otras trayectorias (Vulnerables) |
Casos |
97 |
10 |
79 |
186 |
|
% filas |
52,2% |
5,4% |
42,5% |
100,0% |
||
% columnas |
49,0% |
52,6% |
44,4% |
47,1% |
||
No pobre en las tres mediciones (No pobres) |
Casos |
91 |
5 |
88 |
184 |
|
% filas |
49,5% |
2,7% |
47,8% |
100,0% |
||
% columnas |
46,0% |
26,3% |
49,4% |
46,6% |
||
Total |
Casos |
198 |
19 |
178 |
395 |
|
% filas |
50,1% |
4,8% |
45,1% |
100,0% |
||
% columnas |
100,0% |
100,0% |
100,0% |
100,0% |
||
Fuente: Estudio longitudinal (UNTREF). Base matcheada, 395 casos donde se obtuvo información matcheada para las tres ondas en individuos mayores a 14 años.
Estos datos muestran que el sólo el 40 % de los mayores de 14 años que han sido pobres en las tres mediciones (n=25, como se muestra en el resaltado en el Cuadro 22) estaban ocupados en el 2005. Hay un porcentaje relativamente significativo de desocupados en este grupo, que alcanza al 16 % del total[54]. Es quizás relevante aclarar que este porcentaje de desocupados corresponde a la relación de desocupados / población total, cálculo que no corresponde a la tasas de desocupación (que se calcula como la proporción entre el número de desocupados y el número de individuos económicamente activos; en este caso sería 4/14, alrededor del 28,6 %, un valor elevado para este indicador — aunque existe poca confianza estadística dado los valores bajos de la muestra –).
También se observa que entre los no pobres en las tres mediciones (n=184) el porcentaje de desocupados es de 2,7 %, un registro significativamente menor al de los que tuvieron trayectorias de pobreza en las tres mediciones.
Estas relaciones en general se tratan de asociaciones estadísticas entre trayectorias y estados finales, y no está demostrado que sean relaciones causales[55].
En general se observa que los individuos en pobreza crónica en mayor medida están excluídos del acceso al mercado de trabajo formal y estable (esta situación se vio en este período agravada por un deterioro también del mercado formal de trabajo, en el período postcrisis de la convertibilidad (A. Salvia & Vera, 2011). Si en décadas anteriores los pobres estaban incluídos en el mercado de trabajo, la situación actual de estos hogares pobres corresponde a una exclusión de él. Los desocupados no tienen trabajo porque son pobres, y son pobres porque son desocupados, en un nexo circular (Oliva, 2006; Oliva & Hoszowski, 2002).
Trayectorias y exclusión de beneficios sociales
La exclusión de los lugares tradicionales de trabajo, tales como la fábrica, deja a los hogares en Argentina sin beneficios sociales importantes, como la obra social.
Cuadro 23: Trayectorias de pobreza de acuerdo a cobertura de obra social en 2005
Condición de pobreza según posesión de Obra Social | |||||
Cobertura de Obra Social |
Total |
||||
Si |
No |
||||
Pobreza |
Pobre en las tres mediciones (Pobres crónicos) |
Casos |
6 |
28 |
34 |
% fila (Pobreza) |
17,6% |
82,4% |
100,0% |
||
% Obra Social |
2,4% |
15,8% |
7,9% |
||
Otras trayectorias (Vulnerables) |
Casos |
104 |
95 |
199 |
|
% fila (Pobreza) |
52,3% |
47,7% |
100,0% |
||
% Obra Social |
41,4% |
53,7% |
46,5% |
||
No pobre en las tres mediciones (No pobres) |
Casos |
141 |
54 |
195 |
|
% fila (Pobreza) |
72,3% |
27,7% |
100,0% |
||
% Obra Social |
56,2% |
30,5% |
45,6% |
||
Total |
Casos |
251 |
177 |
428 |
|
% fila (Pobreza) |
58,6% |
41,4% |
100,0% |
||
% Obra Social |
100,0% |
100,0% |
100,0% |
||
Fuente: Estudio longitudinal UNTREF. Base matcheada, 428 casos donde se obtuvo información matcheada para las tres ondas.
Del Cuadro 23 se infiere la situación de exclusión social de los individuos con trayectorias de pobreza en las tres mediciones (más allá de las condiciones relativas al ingreso): considerando el acceso a los servicios de salud, el 82,4 % no tiene obra social en el 2005, mientras que los no pobres en las tres mediciones tienen un porcentaje mucho menor, de 27,7 %, que no tiene obra social en el 2005.Si bien se requeriría una definición más precisa de la relación entre vulnerabilidad – exclusión (Feliz, 2001), se verifica que la pobreza por ingresos es un indicador indirecto de la menor probabilidad de acceder a toda una serie de beneficios y seguridad social. Probablemente la exclusión del mercado de trabajo, y de los beneficios sociales organizados socialmente a través de la inserción laboral formal, obliga a los actores excluidos a organizar instituciones sociales por fuera de una participación común en el mercado o la producción[56]. En conexión con esa situación (y aunque esta afirmación no es objeto de indagación empírica en esta tesis), la exclusión social de los pobres también ha tenido efectos en la protesta social, que se ha separado del mundo del trabajo y de la fábrica, derivándose a los cortes de calles y rutas (Oliva, 2006). Los desocupados no pueden parar una producción, y entonces paran la circulación (por ejemplo, los cortes de ruta de las organizaciones territoriales)[57].
Una mirada dinámica enriquece al concepto de vulnerabilidad como una condición de vida en la cual es posible desembocar en exclusión social, si bien no la vulnerabilidad no es necesariamente equivalente a la exclusión social (Féliz, Deledicque, & Sergio, 2001)[58].
Transiciones
En el Cuadro 24 se ejemplifican transiciones entre pobres y no pobres en dos mediciones o rondas. Si los estados de los individuos no se modifican los casos se ubican en la diagonal formada por las casillas A y B. Los casos fuera de esas diagonales registran transiciones o cambios.
Cuadro 24: Ejemplo de matriz de transición
Segunda ronda |
||
Primera ronda |
X=1 (no pobre) |
X=2 (pobre) |
X=1 (no pobre) |
A |
Transición B (No Pobre – Pobre) |
X=2 (pobre) |
Transición A (Pobre – No Pobre) |
B |
Fuente: elaboración propia, datos ficticios
Puede resultar conveniente distinguir entre la estabilidad o cambio de los individuos por un lado, y la estabilidad de la población en su conjunto por el otro (Maletta, 2012). Como resultado de los flujos de transición ocurridos entre las dos observaciones, la distribución marginal final podría ser diferente a la inicial; asimismo, diversos individuos pueden acabar en un estado distinto al que ocupaban al inicio. Si ningún individuo cambia de estado, tampoco cambia la distribución agregada, como se observa en el ejemplo del Cuadro 25.
Cuadro 25: Ejemplo de estabilidad individual y agregada
Segunda ronda |
Total |
||
Primera ronda |
X=1 (no pobre) |
X=2 (pobre) |
|
X=1 (no pobre) |
100 |
100 (25%) |
|
X=2 (pobre) |
300 |
300 (75%) |
|
Total |
100 (25%) |
300 (75%) |
400 |
Fuente: elaboración propia, datos ficticios
Para aclarar estos conceptos se muestra un ejemplo a partir de datos ficticios. En el Cuadro 25 los 100 individuos que estaban en el estado X=1 (no pobres) en la primera ronda, siguieron en ese estado en la segunda ronda. Al mismo tiempo, 300 sujetos permanecieron en el estado 2 (pobres) en la primera y segunda ronda. Ninguno de estos individuos cambió de estado y por lo tanto la distribución marginal de sujetos también siguió siendo la misma en ambas rondas: 25 % en el estado X=1 (no pobres), y 75 % en el estado X= 2 (pobres). Esa situación de estabilidad individual (que implica también la estabilidad agregada) en la práctica no es muy común. Lo más factible es que algunos individuos cambien de estado entre una observación y otra. Estos movimientos podrían implicar o no un cambio en la distribución agregada de la variable: si existen cambios individuales pero ellos se compensan mutuamente, de modo que se mantiene la estabilidad agregada. En el Cuadro 26 se observa la información del cambio entre el período 2000 – 2005, es decir entre el tiempo inicial y el tiempo final del seguimiento.
Cuadro 26: Matriz de transición pobreza 2000 – 2005
Incidencia de la Pobreza – 2000 |
Total |
||||
No pobres |
Pobres |
||||
Incidencia de la |
No pobres |
Casos |
419 |
96 |
515 |
% Total |
64,4% |
14,7% |
79,1% |
||
Pobres |
Casos |
89 |
47 |
136 |
|
% Total |
13,7% |
7,2% |
20,9% |
||
Total |
Casos |
508 |
143 |
651 |
|
% Total |
78,0% |
22,0% |
100,0% |
||
Fuente: Estudio longitudinal UNTREF, 651 casos donde se obtuvo información matcheada para las ondas 2000 y 2005
En el Cuadro 26 observamos que un 7,2 % (resaltado) de los individuos fueron registrados como pobres en ambas mediciones. En general, la situación entre 2000 y 2005 puede describirse como de estabilidad agregada, dado que los valores entre el inicio y el final de período se mantienen relativamente estables — 20,9 % en 2000 de individuos pobres y 22 % en 2005 –. Pero al mismo tiempo, se observa que en este período no se verificó estabilidad individual, porque hubo muchas transiciones de pobres a no pobres, que terminaron compensándose a nivel agregado.
Para este caso, es de interés desagregar este análisis entre los dos períodos, dado que éstos fueron cualitativamente distintos en cuanto a la situación social, como podremos observar. Estos efectos pueden asociarse a los cambios de trayectorias en dos períodos disímiles, que puede ser referidos como un periodo de crisis (2000 – 2002) y otro de recuperación (2002 – 2005). Este tipo de descripciones de la evolución de indicadores sociales son consistentes con las formuladas por otros autores (Féliz, Deledicque, & Sergio, 2001; Féliz, Deledicque, Sergio, et al., 2001; Salvia & Vera, 2011; Salvia, 2011b) .
Entre los años 2000 a 2002, hubo una transición relevante desde no pobres a pobres, como se observa en el Cuadro 27. Desde un punto de vista social, estas transiciones deberían ponderarse como una evolución negativa de la calidad de vida de los hogares.
Cuadro 27: Matriz de transición pobreza 2000 – 2002
Incidencia de la Pobreza – 2000 |
Total |
||||
No pobres |
Pobres |
||||
Incidencia de la |
No pobres |
Casos |
302 |
26 |
328 |
% Total |
47,2% |
4,1% |
51,3% |
||
Pobres |
Casos |
199 |
113 |
312 |
|
% Total |
31,1% |
17,7% |
48,8% |
||
Total |
Casos |
501 |
139 |
640 |
|
% Total |
78,3% |
21,7% |
100,0% |
||
Fuente: Estudio longitudinal UNTREF, 640 casos donde se obtuvo información matcheada para las ondas 2000 y 2002.
Podemos calcular la probabilidad de transición en estos años. En el Cuadro 27 se observa que hubo 225 casos (n = 199 + 26) en transición sobre los 640 relevados, lo que implica una probabilidad de transición de 0,3515625 en el período de dos años (se calcula dividiendo 225 sobre el total de casos, 640). En este caso, la transición fue en su mayor parte de no pobres a pobres (n = 199) — la transición de pobre a no pobre solo tuvo 26 casos –. Puede observarse que entre 2000 y 2002 la estabilidad agregada fue baja. Claramente hubo transiciones a situaciones de pobreza en el 2002, año que como se había referido, ocurrió una importante crisis económica y política en Argentina. Por ello se registra una cantidad significativa de individuos que viven en hogares bajo la línea de pobreza en el año 2002. En el Cuadro 28 se observa que entre 2002 y 2005, hubo 164 transiciones (n = 149 + 15), lo que implica una relación del 0,359 respecto del total (n = 457) en un período de tres años (164/457).
Cuadro 28: Matriz de transición pobreza 2002 – 2005
Incidencia de la Pobreza 2002 |
Total |
||||
No pobres |
Pobres |
||||
Incidencia de la Pobreza 2005 |
No pobres |
Casos |
216 |
149 |
365 |
% del Total |
47,3% |
32,6% |
79,9% |
||
Pobres |
Casos |
15 |
77 |
92 |
|
% del Total |
3,3% |
16,8% |
20,1% |
||
Total |
Casos |
231 |
226 |
457 |
|
% del Total |
50,5% |
49,5% |
100,0% |
||
Fuente: Estudio longitudinal UNTREF, 457 casos donde se obtuvo información matcheada para las ondas 2002 y 2005.
En este periodo la transición fue en un sentido inverso al del periodo anterior, y los pobres pasaron en su mayor parte a ser no pobres (n = 149). La interpretación es cualitativamente distinta a la transición de caída a situaciones de pobreza. La probabilidad de transición en el período completo es solo comparable con otro período si se la normaliza de acuerdo a la cantidad de años considerados[59]. Como en un período tenemos dos años, y en el otro tres, tendremos que normalizar la probabilidad por año. Por ejemplo, una probabilidad de transición en un período de dos años de 0,5, corresponde a una probabilidad de transición de 0,25 en un año de ese período. En este caso, la probabilidad de transición de 0,35156 en dos años (2000 – 2002), puede ser estandarizada como una probabilidad de transición anual de 0,1758 al año (dividiendo 0,35156 / 2). Así, existió un 15,6% de probabilidad de cambiar de estado (pobre a no pobre o viceversa) en un año de este período. La probabilidad de transición calculada (0,3589 ) entre 2002 – 2005 (3 años) es de 0,1196 por año (0,3589 / 3). Hay una probabilidad del 11,9 % de sufrir una transición de pobreza a no pobreza, o viceversa. Estas probabilidades se resumen en el Cuadro 29.
Cuadro 29: Probabilidad anual de transiciones de pobreza
Numero de transiciones |
Probabilidad de transición |
Años |
Probabilidad por año |
|
Periodo 2000-2002 |
225 transiciones |
0,3515625 |
2 |
0,17578125 |
Periodo 2002-2005 |
164 transiciones |
0,35886214 |
3 |
0,11962071 |
Fuente: Estudio longitudinal (UNTREF).
Los datos del cuadro anterior indicarían que la probabilidad de transición (0,1757) en el período de crisis social entre 2000 y 2002 fue mayor que en el período 2002 – 2005 (0,11962071). Esto sería compatible con la descripción heurística de que en períodos de crisis, hay una mayor probabilidad de cambios de estado. Podemos integrar en estos análisis los aspectos metodológicos y los teóricos de la estratificación social, del análisis del tiempo, y de las crisis.
Variable de hogar e individuales
Dada la definición de pobreza, esta variable es una característica del grupo que predica sobre el individuo. En este caso para las trayectorias de hogares es difícil aislar los efectos de variables explicativas, si queremos hacer imputaciones de tipo variable independiente – dependiente[60]. Esto ocurre porque en el hogar existen distintos individuos, y los convivientes pueden tener mucha heterogeneidad en cuanto a las variables que los describen; al ser agregadas estas características en hogares se pierde capacidad de interpretación precisa.
La definición habitual de pobreza es una categoría que describe a un hogar, y predica sobre los individuos – se le “adosa” a los integrantes –. Esto trae problemáticas al nivel de comprensión causal, dado que las características agregadas de las variables medidas sobre los hogares diluyen la capacidad explicativa sobre su evolución de las características individuales. En otras palabras, si se busca explicar la evolución de una característica del hogar con una característica del individuo, el salto de unidades de análisis muchas veces hacen poco clara la imputación (de asociación estadística, o eventualmente de causalidad). En el mismo sentido, el ingreso per cápita familiar de un niño pequeño, o si vive en un hogar pobre o no pobre, es una característica que depende de factores que el niño no controla; es decir, no depende del trabajo o las capacidades del niño, sino de los adultos perceptores de ingresos.
Existe una cierta distribución desigual del ingreso que debe ser corregida desde un punto de vista de la equidad social. Desde ciertas perspectivas, y en un contexto de inequidad, que el recién nacido nazca en un hogar pobre o no, es aleatorio. Esto es tratado por Rawls (1972) en su teoría de la justicia, y la formulación de un velo de la ignorancia (Rawls, 1971, 1972, 2005) que no nos permite saber qué factores o características aleatorias recibidas en suerte (cuanta inteligencia, fortaleza, destreza, patrimonio familiar) nos van a afectar luego en nuestra posición en la organización social[61]. Más allá de esta situación, el ingreso per cápita familiar del niño no es un atributo sobre el cual él pueda producir modificaciones, en términos generales. Habitualmente puede analizarse una cierta relación entre características individuales (educación, capacidades, y otras) con ciertas situaciones de vida y decisiones que toma (si acepta un empleo o no, si estudia o no), a partir de cierto desarrollo de racionalidad, que es un factor correlacionado con la edad biológica. Se supone que la libertad de albedrío (y desde el punto de vista de los estudios sociales, la indeterminación y el azar en la conducta del individuo) se desarrolla en los adultos con su crecimiento biológico; a los niños se les imponen ciertas condiciones sociales (si el niño trabaja, por ejemplo, por lo general no es una decisión autónoma, sino por una imposición de su ambiente social).
Los presupuestos sobre la racionalidad y su correlación con el desarrollo biológico se transforman en codificaciones y legislaciones concretas. Por ejemplo, el supuesto de racionalidad en el voto en la democracia está previsto a partir de los 16 años, según las últimas legislaciones en Argentina. Antes de estas edades el individuo no tendría la racionalidad plenamente formada (Oliva & De Angelis, 2014) para votar (la racionalidad es un supuesto básico de la democracia, en este sentido).
Esto nos lleva a algunas reflexiones sobre la variable pobreza por ingreso, y su operacionalización habitual.
La definición de pobreza por ingreso en los términos y con las definiciones acá expresadas, a partir de características de los hogares, es una de las operacionalizaciones posibles del concepto, y desde el punto de vista teórico puede tratarse como una decisión académica que puede ser replanteada. Se han discutido diversas alternativas sobre los enfoques multidimensionales de la pobreza, por ejemplo[62].
En el mismo sentido, y replanteando la operacionalización de la pobreza como característica del hogar, sería posible encontrar otros tipo de definiciones que no sean referidas al hogar, sino al individuo; en ese sentido, se podría considerar por ejemplo que un individuo fuese pobre, en un hogar no pobre[63]. Tal posibilidad no está contemplada con las actuales definiciones de pobreza por ingresos (CEPA, 1994; Minujin, 1997; Murmis & Feldman, 1992; Oliva, 2008). La adopción de un criterio de hogar en la definición de pobreza en las metodologías de cálculo oficial del tema, seguramente tiene una relación con los estudios pioneros del fenómeno de la pobreza en Argentina de los años 70, donde se estudiaban las estrategias de supervivencia (Gutiérrez, 2007), y existía un foco compartido entre distintos autores (Torrado, 2003; Torrado & Rofman, 1988) de la unidad doméstica como elemento de análisis nodal (Vallejos & Leotta, 2013, 3).
En este sentido, y más allá de la necesidad de estudiar estrategias familiares de vida (Torrado, 1982) [64], en muchos casos es relevante también poder seguir en el tiempo a las características de los individuos[65]. Así, es de interés en este estudio analizar el ingreso individual, y su evolución en el período investigado. A esa tarea nos dedicaremos en el siguiente apartado.
Modelos multinivel aplicados al análisis de trayectorias de ingresos
Siguiendo el análisis de los cambios sufridos en la estratificación social en el período, a partir de la construcción de la información en bases de datos consolidadas, se evalúan los cambios creando variables de evolución individual de las personas. En este punto, en lugar de utilizar una variable de pobreza como en los apartados anteriores (y también tomando en consideración las dificultades metodológicas del paso de la unidad de análisis individuo a unidad de análisis hogar), se utiliza para el análisis el ingreso total del individuo.
En este estudio fueron relevados el ingreso total individual, el ingreso total familiar y el “ingreso necesario familiar” (esta pregunta se formuló a todas las personas ocupadas presentes en el hogar al momento de la encuesta). Dado que se utilizaron los ingresos para la medición de pobreza, se imputaron las no respuestas en el ingreso y se computaron (e imputaron si fuera necesario) los ingresos familiares totales. Esto fue necesario pues si para algunos componentes se carecía de información sobre su ingreso, el ITF se vería o distorsionado o habría que haber eliminado muchos hogares del análisis[66].
Evolución del ingreso
En el Cuadro 30 se observa la evolución de los ingresos per cápita familiar, corregido por equivalente adulto. Se realizó una imputación de las no respuestas en el ingreso total individual, y luego se calculó el ingreso per cápita familiar. El ingreso per cápita familiar corregido por equivalente adulto[67] bajó de 374,8$ en 2000 a 265,6$ en 2002, para aumentar sensiblemente a 469,7$ en 2005.
Cuadro 30: Ingreso promedio per cápita familiar corregido por equivalente adulto, en pesos, según año
Promedio |
2000 (corregido por EA) |
2002 |
2005 |
TOTAL |
374.8$ |
265.6$ |
469.7$ |
Fuente: Estudio longitudinal (UNTREF).
El ingreso total familiar por su parte se reduce de 1044$ en el 2000 a 904$ en el 2002, subiendo a 1374$ en 2005 (en este caso como es un ingreso total familiar no requiere corrección por equivalente adulto).
Cuadro 31: Promedios de las variables de ingreso total familiar e ingreso total individual en las tres ondas, en pesos nominales y deflacionados (base 2000=100).
Bases completas – Promedio en $ |
2000 |
2002 |
2005 |
Ingreso total familiar |
1044 |
904 |
1374 |
Deflacionados (2000 = 100) |
1044 |
624 |
792 |
Ingreso total individual |
536 |
504 |
735 |
Deflacionados (2000 = 100) |
536 |
348 |
424 |
Fuente: Estudio longitudinal UNTREF. No respuestas e ingreso 0 eliminados del promedio. Ingreso Individual: imputación por método Hot – deck.
Estos promedios nominales deben ser deflacionados, para establecer el aumento real de éstos, dada la inflación que se registra en el período de estudio. A partir del Índice de Precios al Consumidor podemos ajustar estos valores por la inflación minorista (ver Anexo, Cuadro 47). Se observó que a pesar del crecimiento nominal, los ingresos deflacionados registraron valores similares a los del año 2000 (de acuerdo al IPC – INDEC).Los valores deflacionados por el Índice de Precios al Consumidor (IPC – INDEC) muestran que a pesar del crecimiento nominal del ingreso total familiar (que va de 1044 $ a 1374 $ en el 2005)[68] en el período, el ingreso total familiar deflacionado se reduce desde 1044 $ en el 2000 a 792$ en 2005. En el Cuadro 31 y el Gráfico 6 se observan los promedios de ingresos totales familiares, e individuales, comparando su valor nominal y su valor deflacionado (con base al año 2000).
Gráfico 6: Promedios de ingreso total familiar, nominales y deflacionados
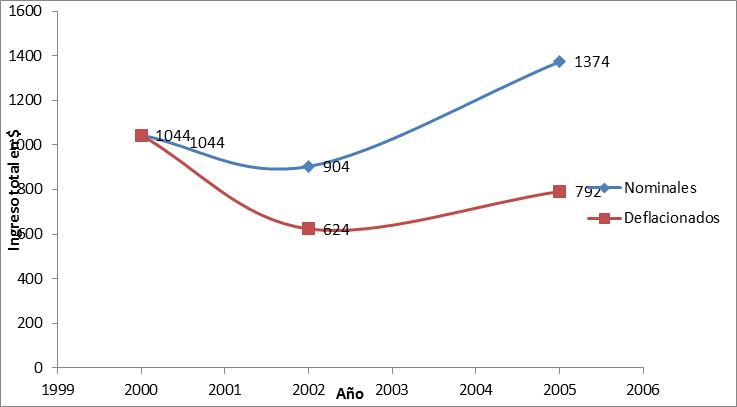
Fuente: Estudio longitudinal UNTREF. No respuestas e ingreso 0 eliminados del promedio. Ingreso Individual imputado por método Hot – deck.
El hecho de que la pobreza no pueda medirse siempre con los mismos valores, que la canasta tenga que ser actualizada y los ingresos deflacionados, es un reflejo de lo que hemos llamado (entre los desafíos del análisis del tiempo) el envejecimiento de los indicadores (Desafío B). En este caso el indicador “ingreso nominal” se vuelve obsoleto en un contexto inflacionario como el de Argentina de esta época (tal como se puede observar en los datos de la evolución de la inflación medida mediante el IPC GBA del Anexo), porque la capacidad de intercambio de productos o servicios de una suma fija de dinero no es el mismo, y la probabilidad de intercambiar ese monto por productos o servicios disminuye con el tiempo.
Esta evolución fluctuante de los ingresos anticipa que habrá modificaciones importantes en la población viviendo en hogares bajo la línea de pobreza.
Aplicación de modelos estadísticos para el análisis del cambio
Los modelos multinivel de cambio permiten responder dos tipos de preguntas: 1) ¿Cómo cambia el resultado a través del tiempo? 2) ¿Podemos predecir las diferencias de estos cambios? La primer pregunta es descriptiva y hace hincapié en las características que describen la modalidad de cambio de cada persona a través del tiempo (lineal, no lineal, constante o variable a través del tiempo, y otras). La segunda está relacionada con la asociación entre los predictores y los patrones de cambio (¿diferentes tipos de personas experimentan distintos patrones de cambio? ¿qué predictores están asociados con qué patrones?). En una primera instancia nos preguntamos acerca del cambio del individuo a través del tiempo. Buscamos caracterizar el patrón individual de cambio y describir la trayectoria de crecimiento individual de cada persona, el modo en que crecen o disminuyen sus valores a través del tiempo. En la segunda instancia de un análisis del cambio, nos preguntamos acerca de las diferencias interindividuales del cambio. Evaluamos si diferentes personas manifiestan diferentes patrones de cambio y que es lo que predice estas diferencias.
Cuando se utilizan variables continuas, como el ingreso, los resultados admiten todas las operaciones usuales de la aritmética: suma, resta, multiplicación y división. Las diferencias entre pares de puntuaciones, espaciados en forma equidistante a lo largo de la escala, tienen significados idénticos. Se dice que la métrica en cual el resultado se mide debe preservarse en el tiempo, indicando que las puntuaciones de resultado deben ser equiparables con el tiempo; es decir, un valor dado en una ocasión debe representar la misma cantidad en cualquier otra ocasión. Si los resultados no son equiparables en el tiempo, no se puede suponer la equivalencia longitudinal de los significados de la puntuación, dejando los resultados inutilizables para medir el cambio (Singer & Willet, 2003). Debe tenerse en cuenta que las medidas no se pueden hacer iguales simplemente mediante la estandarización de sus calificaciones en cada ocasión con un desvío estándar común.
Aunque la fiabilidad de la medición del cambio depende directamente de la fiabilidad del resultado, la precisión con la cual se calcula el cambio individual depende del número y del espaciamiento de las ondas, y de la recopilación de datos. Mediante una cuidadosa selección de las ocasiones de medida por lo general puede compensar los efectos perjudiciales del error de medición del resultado (Singer & Willet, 2003).
Para aprovechar la capacidad analítica de los estudios longitudinales pueden analizarse las trayectorias de cambio de ciertas variables dependientes, asociadas a las variaciones de las variables independientes. O también incorporar efectos de variables que no varíen en el período (por ejemplo, sexo), pero cuyo efecto en las trayectorias comparadas entre individuos puede ser analizado. Al mismo tiempo, hay que diferenciar las características individuales que varían y las que no varían; las que no varían no pueden explicar los cambios individuales porque son una constante al nivel del individuo. Esto indica que los efectos fijos controlan las diferencias que no se modifican en el tiempo de los individuos, de modo tal que los coeficientes estimados con efectos fijos no estén sesgados por características invariantes en el tiempo [69].
“…The fixed-effects model controls for all time-invariant differences between the individuals, so the estimated coefficients of the fixed-effects models cannot be biased because of omitted time-invariant characteristics… [like culture, religion, gender, race, etc]”. .. One side effect of the features of fixed-effects models is that they cannot be used to investigate time-invariant causes of the dependent variables. Technically, time-invariant characteristics of the individuals are perfectly collinear with the person [or entity] dummies. Substantively, fixed-effects models are designed to study the causes of changes within a person [or entity]. A time-invariant characteristic cannot cause such a change, because it is constant for each person” (Kohler & Kreuter, 2012, 245)
Por ejemplo, si tenemos a los individuos 1 y 2, las trayectorias y variaciones de sus ingresos (variabilidad intraindividual) no pueden ser explicadas por características individuales invariantes en el tiempo, como su sexo [70]. En el individuo 1 la variación de 270 $ en 2000 a 195,84 $ en 2002 no puede explicarse por el hecho de ser hombre o mujer (Cuadro 32), porque es muy poco probable que haya variado en esos años (la variable sexo es perfectamente colineal con el individuo, en términos estadísticos).
Cuadro 32: Ejemplificación de variación intraindividual e interindividual.
Año |
Individuo 1 |
Individuo 2 |
Ingreso deflacionado en $ |
Ingreso deflacionado en $ |
|
2000 |
270 |
600 |
2002 |
186,3 |
138 |
2005 |
195,84 |
460,8 |
Fuente: Estudio longitudinal (UNTREF).
En cambio, si el individuo 1 fuera varón, y el 2 mujer, podemos ver las diferencias en las trayectorias. En un período corto, las variables individuales como la religión o el sexo se mantienen constantes[71]. En ese sentido, al interior de las trayectorias de un individuo, las fluctuaciones deberían ser explicadas o asociadas estadísticamente a otros factores que efectivamente, varíen en el tiempo. Si las características individuales no cambian en un periodo breve, ¿qué puede influir entonces para que haya cambiado el ingreso? ¿Es por el contexto, o por cambios internos al individuo?
En las explicaciones de las variaciones pueden existir estilizadamente, cambios individuales, cambios contextuales o una combinación de ambos. Algunos factores como un aumento del salario de una empresa en la que el individuo esta asalariado, o un aumento del salario mínimo, el crecimiento de la inversión o el PIB en un país, o la generalización de un subsidio universal, son variables contextuales que pueden influir en el aumento de ese ingreso. Los factores individuales podrían ser por ejemplo que el individuo haya puesto un microemprendimiento, que haya tomado otro trabajo, que haya finalizado capacitaciones, y otros factores que están referidos más bien al aumento de las capacidades y libertades individuales, al decir de Amartya Sen (1982, 1984, 1987, 1999a, 1999b). Es necesario también aclarar que, como indica Wooldrige (2010), algunos de esos factores individuales son observables directamente, y otros no (por ejemplo las habilidades innatas del individuo[72]).
Todo contexto social genera desigualdades y exclusiones en el acceso a recursos económicos y culturales, y a recompensas y beneficios de la actividad económica y el desarrollo social (Oliva, 2006; Oliva, 2010b; Salvia, 1997, 2011a, 2011b). A los factores sociales estructurales y las condiciones macroeconómicas, se contraponen respuestas microsociales, estrategias de los actores y de los núcleos familiares, que terminan definiendo las características de los procesos de exclusión – inclusión social. De ese modo, la estratificación social es un proceso dinámico (Giddens, 1974, 1975, 1989) que se reproduce en el tiempo (Elias, 1982a, 1992, 1994), y no una estructura estática.
Desde el punto de vista del combate contra la pobreza, podríamos decir que en algunos casos desde las políticas sociales focalizadas o universales, los gobiernos tratan de mejorar las condiciones contextuales, y ofrecer subsidios y planes para la aliviación coyuntural de la pobreza. Pero seguramente desde el punto de vista de la solución más estructural de la situación de pobreza, y en la línea del análisis de Sen (1984), es más efectivo el aumento de los factores de capacidad individual (Sen & Wood, 2006). El aumento de sus capacidades individuales aumentaría su libertad e independencia (Oliva & Phelan, 2014), mientras que las otras políticas podrían fomentar la dependencia de las políticas circunstanciales.
Como señala Francois Dubet, es necesario evitar una estigmatización de los más débiles o la culpabilización de las víctimas de la pobreza (Dubet, 2002); no es posible asignar una responsabilidad exclusivamente personal a quienes están en la pobreza a salir de esa situación. Lo que indica esto es que existen factores individuales y sociales en estos procesos, y que desde un punto de vista de la evolución de la serie, ambas cuestiones podrían diferenciarse. Por ello, es difícil establecer una evaluación normativa o moral contraponiendo la evolución de los contextos sociales, respecto de los factores y disposiciones individuales, en este tipo de datos.
Desde el punto de vista estadístico, si el mejoramiento se debiera al cambio positivo en el contexto social general, todos los individuos deberían variar de la misma forma, y las trayectorias crecerían en un modo equivalente. Si se tratara de mejoramientos individuales, o diferentes capacidades para absorber o aprovechar mejoramientos contextuales (o en un sentido inverso, detener los efectos nocivos de las crisis), deberíamos observar que las trayectorias individuales varíen de un modo heterogéneo. Por supuesto, siembre habrá combinaciones de estas situaciones (parte de la variación será contextual y parte individual), y siempre habrá una parte de la varianza explicada por factores intraindividuales y otra por factores interindividuales (algo de esto podría medirse con la correlación intraclase, que veremos en los siguientes apartados).
Modelos multinivel
La dinámica de las trayectorias de los individuos, puede relacionarse con ciertas variaciones de variables independientes predictoras. En principio para esto utilizaríamos modelos multinivel, los cuáles se utilizan para datos agrupados (o anidados) en más de una categoría (por ejemplo, estados, países, individuos, etc.). Los modelos multinivel permiten captar: a) efectos de estudio que varían según la entidad (o grupos o individuos); b) la estimación de niveles promedio del grupo en alguna variable.
Una forma de analizar el cambio individual es calcular una regresión lineal del ingreso para un individuo en la serie de puntos en el tiempo, suponiendo trayectorias lineales en el período analizado. Los coeficientes de estas regresiones indican la evolución de esa variable (Singer & Willet, 2003). La regresión OLS (la regresión normal o regular) ignora la variación media entre entidades, en este caso, los individuos; en cambio, los modelos multinivel permiten estos análisis. Es importante diferenciar niveles, puesto que una conclusión sobre una serie de datos agregados, por ejemplo que exista una relación agregada entre años de estudio e ingreso al nivel de una cuidad, no permite asegurar que tales relaciones entre esas variables existan y se verifique al nivel de todos los individuos (o grupos, o elementos) involucrados.Esta idea relevante es expresada en An Introduction to Multilevel Modeling – basic terms and research examples, de John Nezlek[73]. Nezlek ejemplifica el efecto de las correlaciones agregadas y las individuales, cuando se analizan en distintos niveles de análisis. Consideremos estos datos ficticios para obtener una correlación de Pearson entre la variable años de estudio (una variable irreversible, que como se observa en los datos, solo puede crecer, y tiene entonces una dirección privilegiada en el tiempo) y el ingreso por hora. En estos datos, diferenciamos la información para una serie de cada individuo.
Cuadro 33: Ejemplo de datos para elaborar un modelo multinivel
Individuo |
Años de estudio |
Ingreso por hora |
1,00 |
1,00 |
10,00 |
1,00 |
2,00 |
9,00 |
1,00 |
3,00 |
8,00 |
1,00 |
4,00 |
7,00 |
1,00 |
5,00 |
6,00 |
2,00 |
4,00 |
10,00 |
2,00 |
5,00 |
10,00 |
2,00 |
6,00 |
11,00 |
2,00 |
7,00 |
10,00 |
2,00 |
8,00 |
10,00 |
3,00 |
9,00 |
13,00 |
3,00 |
10,00 |
14,00 |
3,00 |
11,00 |
15,00 |
3,00 |
12,00 |
16,00 |
3,00 |
13,00 |
17,00 |
Fuente: datos ficticios obtenidos de Nezlek (2015).
Con estos datos, obtenemos la siguiente correlación de Pearson, calculado a nivel agregado, como se observa en el Cuadro 34.
Cuadro 34: Correlación agregada para datos de ejemplo multinivel
Correlations | |||
Años estudio |
Ingreso horario |
||
Años estudio |
Correlación de Pearson |
1 |
,851** |
Sig. (2-tailed) |
,000 |
||
N |
15 |
15 |
|
Ingreso horario |
Correlación de Pearson |
,851** |
1 |
Sig. (2-tailed) |
,000 |
||
N |
15 |
15 |
|
**. Correlation is significant at the 0.01 level (2-tailed). | |||
Fuente: elaboración propia con SPSS en base a datos ficticios de Nezlek (2015)
Esta correlación positiva y fuerte (+ 0,851) para las 15 observaciones nos indica que, a nivel agregado, a medida que aumenta la cantidad de años de estudio, aumenta el ingreso por hora. Esta relación sería estadísticamente significativa, con un p valor (0,00) inferior a 0,01. Sin embargo, esta relación estadísticamente significativa al nivel agregado, no necesariamente se cumple al nivel de todos los individuos. Si analizamos esta correlación al nivel de los grupos o individuos, obtendremos otro tipo de conclusión. Analizando el Gráfico 7 (elaborado a partir de los datos del Cuadro 34) veremos que para el primer individuo, cuanto mayor cantidad de años de estudio, menor es el nivel de ingresos. Para el segundo, la correlación entre sus años de estudio y su nivel de ingreso es casi nula, y para el tercero, cuando sube la cantidad de años de estudio, aumenta el ingreso por hora. Entonces la afirmación “a medida que aumenta los años de estudio aumenta el ingreso por hora” no es cierta a nivel de una proporción importante de individuos (como se ve en este caso, hay 2 de 3 individuos, es decir un 66 %, en los cuales no se cumple esa correlación o asociación estadística); pero aun así, la correlación es significativa a nivel agregado. Matemáticamente, una correlación agregada no implica que la afirmación sea adecuada para los agrupamientos inferiores (individuos en este caso – podría tratarse de regiones, provincias, municipios, etc.). Es decir, la correlación a nivel agregado no implica que ésta se verifique para todos o la mayor parte de los individuos.
Gráfico 7: Gráficos de dispersión para tres individuos, ejemplos de datos multinivel
Fuente: elaboración propia con SPSS en base a datos ficticios de Nezlek (2015).
Esto indica que los modelos multinivel puede servir para esclarecer si un proceso a nivel agregado, tiene o no un correlato al nivel de los individuos o las entidades de menor nivel. Por ejemplo, y volviendo a las temáticas analizadas en el primer capítulo, y como se había planteado en el Desafío A, si encontramos una tendencia irreversible en un modelo de regresión agregado, esto no significaría que a nivel de los individuos, ese proceso irreversible se verifique del mismo modo, en todos los individuos o agregados de nivel inferior.
Para el análisis de nuestros datos longitudinales, y en particular el ingreso deflacionado, utilizaremos un modelo con dos niveles: 1) un nivel 1, que describe el cambio individual en el tiempo; 2) un modelo de nivel 2, en el que se relacionan las variables predictoras con cualquier diferencia interindividual en el cambio. Este tipo de modelo se suele denominar “modelo multinivel de cambio” (Singer & Willet, 2003). En este tipo de análisis estadístico deben considerarse supuestos sobre los errores, y la diferenciación entre efectos fijos y aleatorios[74] (Hsiao, 1986).
A partir de la variable ingreso individual deflacionado el análisis de trayectoria se puede realizar mediante regresiones lineales de la variación de los individuos, suponiendo trayectorias lineales (a partir de otros supuesto, podrían ajustarse modelos no lineales[75]).Con estos métodos podemos estudiar las trayectorias en el tiempo de los ingresos, y la influencia de la condición de otras variables (factors o covariates) en las posibles diferencias entre las trayectorias de ingresos de los individuos[76].
Ajustaremos ahora un modelo lineal mixto. Este tipo de modelo, cuando se aplica a datos longitudinales, se suele denominar “modelo multinivel de cambio”. En estos modelos se realizan una serie de análisis estadísticos donde se ajustan trayectorias lineales para cada individuo. Luego se calculan las constantes y/o las pendientes de las regresiones lineales para cada uno de los individuos, y el desvío standard de estas variaciones. Se distinguen los efectos fijos y aleatorios, y se busca diferenciar estadísticamente los efectos de cambio del error muestral.
Los métodos de regresión OLS asumen independencia y homocedasticidad de los residuos. Sin embargo, es poco probable que esto se cumpla en datos longitudinales, ya que los residuos tienden a ser autocorrelacionados y heterocedásticos[77] en el tiempo. A pesar de esta preocupación, las estimaciones OLS pueden ser muy útiles a los fines de la exploración. Si bien son menos eficientes cuando se viola el supuesto de independencia residual, igualmente proporcionan estimaciones no sesgadas de la intersección y la pendiente del cambio individual. Entonces, haremos estas estimaciones preliminares de las características de las trayectorias.
Si queremos estudiar las trayectorias en el tiempo de los ingresos, y la influencia de otras variables en las posibles diferencias entre las trayectorias, podemos utilizar modelos multinivel. El nivel 1 de estos modelos es el cambio individual en el tiempo, y el nivel 2, las diferencias interindividuales de esos cambios.
Para ajustar este modelo, en principio se transformó la base de datos a un formato “persona – periodo” (Singer & Willet, 2003) — cada individuo tiene un registro por cada ocasión en la que se midió información panel —[78].
Luego, se llevan a cabo análisis exploratorios que describen cómo los individuos cambian a través del tiempo. Los análisis descriptivos pueden revelar la naturaleza e idiosincrasia del patrón de crecimiento temporal de cada persona, abordando la pregunta “¿cómo es el cambio en el tiempo de cada persona?”. Una forma de analizar este cambio es a través de un gráfico empírico de crecimiento[79], en donde buscamos resumir las tendencias observadas mediante la superposición rudimentaria de las trayectorias individuales (Singer & Willet, 2003). En el Gráfico 8 pueden verse algunas trayectorias de los ingresos nominales, sin deflacionar (para esta estadística se han dejado solo los individuos que tienen información para las tres ondas), y para algunos casos las líneas de regresión de los ingresos totales y sus pendientes, calculadas para cada uno de los individuos (identificados con los números ID) para los tres años (en el eje x: 2000, 2002 y 2005).
Gráfico 8: Evolución de ingresos nominales totales individuales en período 2000 – 2005 y ajuste de rectas de regresión individual
Fuente: Estudio longitudinal (UNTREF). Valores sin deflacionar.
La exploración de algunos casos permite reflexionar sobre algunas características de estos datos. Encontramos datos con ingreso 0 (ver por ejemplo en el Gráfico 8 el caso identificado con el número 8, el primero). En muchos casos los datos corresponden a niños, dado que en estas encuestas de hogares se capta la información sobre todos los integrantes del hogar. Para el análisis eliminaremos los sin ingresos. Luego descartaremos los casos en los que alguna de las respuestas sea cero, por las dificultades que añaden estos valores en la interpretación. En este gráfico también se observan las rectas (de los mínimos cuadrados) ajustadas para cada serie de datos para cada individuo en particular, que serán las rectas de regresión individuales; para cada individuo, se puede calcular además el R² (que se observa en el gráfico), es decir la correlación entre el valor estimado y el valor real, que permite establecer un test del ajuste del modelo a los datos reales. En el Cuadro 45 del Anexo se observa la cantidad de individuos con información para todos los años, para dos, para uno, o los que no tienen información para las tres ondas[80]. También, en análisis posteriores, quitaremos los datos de los individuos que no registraron ingresos en alguno de los años, dado que es difícil distinguir los casos sin respuesta, de los casos en que efectivamente el ingreso fue 0 o nulo.
Después de haber resumido cómo cada individuo cambia, buscamos examinar las similitudes y diferencias de estos cambios a través de las personas; ¿cambian todos de la misma manera? ¿o las trayectorias de cambio difieren sustancialmente entre las personas? Preguntas como estas se centran en la evaluación de las diferencias interindividuales del cambio.
Luego, se busca analizar las trayectorias de los ingresos deflacionados. Estos datos pueden ser descriptos para los individuos mediante ecuaciones de regresión lineal[81].En el Gráfico 9 se ven los datos para algunos casos de los ingresos pero deflacionados. Se observan las líneas de regresión y sus pendientes para los ingresos totales (eje y) para cada uno de los individuos (identificados con los números, por ejemplo 8, 9, 47), para los tres años (eje x). Las pendientes muestran los cambios individuales. En algunas personas los ingresos deflacionados suben (y entonces en la regresión individual tendrán pendientes positivas), y en otros bajan (pendientes negativas).
Gráfico 9: Evolución de ingresos deflacionados totales individuales en período 2000 – 2005 y ajuste de rectas de regresión individual

Fuente: Estudio longitudinal ( UNTREF). No respuestas eliminadas del promedio. Valores deflacionados.
En el Gráfico 9 se observa que las trayectorias tuvieron una variabilidad importante en el período 2000 – 2005. Puede decirse que fueron caóticas, en el sentido de que no tienen patrones homogéneos. Esto es compatible con la interpretación heurística de un proceso de crisis que modifica significativamente las trayectorias. Además, indica que los distintos individuos han tenido distintas capacidades para enfrentar la crisis, ciertamente con distinto grado de éxito.
En el gráfico anterior solo exploramos algunos casos. Para lograr una mayor generalidad en este tipo de conclusión, inspeccionaremos esta afirmación ajustando modelos multinivel. Recordemos además que, como se había explicado, conceptualmente la variabilidad podría deberse a factores individuales, como por ejemplo los referidos a un aumento de capacidades o libertades (Drèze & Sen, 1989) – que haya realizado un curso de algún oficio rentable, o que haya instalado un nuevo microemprendimiento en cuentapropia– , o también a factores contextuales como un aumento del salario mínimo vital o móvil, o una paritaria que lo haya beneficiado (en el caso de un individuo asalariado formal).
Si ajustamos modelos con componentes aleatorios, los β y las constantes de cada individuo pueden variar. Los valores de los coeficientes β de la regresión y las constantes βo se convierten en variables a ser explicadas, por ejemplo por las condiciones iniciales, o la trayectoria de otras variables independientes. Si estudiamos N individuos, tenemos N ecuaciones de regresión, y N valores para los coeficientes β0 y β1.
En algunos casos, se podría utilizar este tipo de series para hacer prognosis y formular hipótesis sobre trayectorias de la variable a futuro — en este estudio particular del ingreso (Desafío D) –. Si proyectamos los datos de la serie a una fecha futura, el valor obtenido no debería entenderse estrictamente como un pronóstico, sino como una hipótesis sobre un escenario posible, en base a supuestos de crecimiento de ingresos. Se supone que las rectas de mínimos cuadrados, ajustadas mediante las regresiones lineales, serán mejores que los promedios de los datos de la serie si se busca pronosticar el ingreso del individuo a futuro. En particular, porque se suele generalizar el concepto de que el crecimiento de los salarios es “inflexible a la baja”, y también porque la inflación tiene un crecimiento que es tendencialmente irreversible. Así, la proyección permite realizar una hipótesis en un período acotado sobre el ingreso que obtendría un individuo si se mantuviesen las tendencias de una serie de ingresos anteriores. En algunos casos, los resultados de estas regresiones pueden ser más precisos que el promedio simple de los datos de la serie para realizar un pronóstico de ingresos. Al mismo tiempo, en una serie con más datos, una proyección acrítica de estas tendencias a largo plazo, posiblemente este desviada respecto de los ingresos reales. Entre otros factores, esto se debe a que las constantes y los coeficientes de estos modelos dependen de los puntos que se tomen como pronosticadores; por ejemplo, si en vez de la serie 2000 – 2005 utilizamos una serie con el ingreso deflacionado desde el año 1995 hasta el 2005. Si tomamos los puntos desde el año 1995 al 2005, y los proyectamos con la misma técnica de regresión, el resultado pronosticado sería distinto a si tomamos los puntos desde el año 1997 al 2005. Entonces, el resultado de la proyección cambia según la selección de datos que se haga del período, es decir, de los puntos (en este caso de ingresos) que se incluyan en la recta.
La adopción de un modelo paramétrico para el cambio individual nos permite reexpresar preguntas genéricas sobre las diferencias interindividuales en el “cambio” como preguntas específicas sobre el comportamiento de los parámetros en los modelos individuales (Hsiao, 1986). Si hemos seleccionado bien el modelo paramétrico, poca información se pierde y se logra una gran simplificación (Singer & Willet, 2003). Si se adopta un modelo lineal de cambio individual, por ejemplo, está aceptando implícitamente que resumir el crecimiento de cada persona usa sólo dos estimaciones de parámetros: la intersección y la pendiente. El análisis de estos estimadores nos muestran el cambio de nuestra variable dependiente ya sea en su “status inicial” (intersección) o en la tasa de cambio que marca las diferencias interindividuales observadas a través del tiempo (pendiente).
Para informarnos sobre el patrón de cambio promedio observado, se examinan los promedios de las muestras de las intercepciones y pendientes, las cuales nos hablan de la situación inicial y de la tasa promedio interanual de variación de la muestra en su conjunto. Para obtener información sobre las diferencias individuales observadas, se analizan las variancias y desviaciones estándar de las intercepciones y pendientes, que nos hablan de la variabilidad observada en la situación inicial y de las tasas de cambio en la muestra. Y para analizar la relación observada entre la situación inicial y la tasa de cambio, podemos examinar la covarianza de la muestra o correlación entre intersecciones y pendientes. Responder formalmente a estas preguntas requiere realizar el modelo multinivel, pero podemos presagiar este trabajo mediante la realización de análisis descriptivos simples de las intercepciones y pendientes estimadas. Además de graficar su distribución, podemos examinar los estadísticos descriptivos (medias y desviaciones estándar) y las medidas resúmenes bivariadas (análisis de correlaciones). Es particularmente útil examinar tres medidas específicas: a) los promedios muestrales de las intercepciones y pendientes estimadas, b) las variancias muestrales (o desviaciones estándar) de las intercepciones y pendientes estimadas y c) las correlaciones muestrales entre las intercepciones y pendientes estimadas.
Podemos ajustar un modelo con random slope (pendiente aleatoria, o pendiente que puede variar para cada individuo), u otro llamado de random intercept (la constante puede modificarse para cada individuo), o un modelo en que tanto la constante como la pendiente sean aleatorios.
La estructura jerárquica de los datos, hace que este tipo de modelos se conozca con el nombre de modelos multinivel[82] (multilevel). Las variaciones en las contantes βo nos indican las diferencias en el comienzo de la serie; estas variaciones podrían ser medidas, por ejemplo, como el desvío estándar de estas constantes. Un modelo de regresión lineal (una regresión lineal común) entre el ingreso y el año para todos los casos en la base de datos, tendría la forma:
Ingreso = β0 + β * (Año) + ε
En la formalización de la Ecuación 1 la variable Año variará entre 2000 y 2005, mientras que la constante β0 y la pendiente β serán fijas. Esto sería una ecuación de regresión normal para el total de la población. Luego, si aleatorizamos – dejamos “libres”- a la constante, a la pendiente, o a ambas (los convertimos en random effects), tendremos modelos multinivel. Suponiendo trayectorias lineales distintas para cada individuo (podrían suponerse en cambio trayectorias no lineales y ajustar otro tipo de ecuación para cada individuo), podemos formular un modelo de regresión lineal para la trayectoria de un individuo (1), donde se especifica para ese individuo una constante, y una pendiente para la variable año:
Ecuación 2:
Ingreso INDIVIDUO 1 = β0 + β1 * (Año) + ε
A diferencia de las ecuaciones de regresión habituales, donde las constantes y los coeficientes son fijos, en este tipo de modelos tanto los coeficientes B como las constantes pueden ser móviles o aleatorios (random effects). Las estimaciones de estos efectos se conocen como best linear unbiased predictions (BLUPs). Los efectos aleatorios no son directamente estimados, pero son caracterizados por los elementos de G, conocidos como los componentes de la variancia [83].
Modelos lineales mixtos de ingreso deflacionado
Con estas definiciones, se elaboró un modelo lineal mixto (mediante el software STATA) teniendo como variable a explicar el ingreso deflacionado respecto del tiempo. Se eliminaron de la base de datos los individuos con ingreso 0 en todos o en algunos de los tres años [84] de medición. En el Cuadro 35 se registran las estadísticas descriptivas.
Cuadro 35: Estadísticas descriptivas del ingreso deflacionado, período 2000 – 2005
Variable |
Observaciones |
Media |
Desvío Standard |
Min. |
Max. |
ingredef |
492 |
473.9623 |
348.3549 |
13.8 |
2246.4 |
Fuente: Estudio longitudinal (UNTREF). No respuestas eliminadas del promedio. Valores deflacionados.
El promedio del ingreso deflacionado es de 473,9623 $ tomando en cuenta 492 observaciones (Cuadro 35), que son el total de datos captados en los tres años. Es decir, éste sería el promedio general del período. Mediante un modelo multinivel lineal mixto, podemos distinguir la variabilidad del punto inicial de los ingresos y el desvío estándar en los datos de los individuos (intraindividuo). Se ajustó el modelo multinivel lineal mixto al ingreso deflacionado entre 2000 y 2005, con una constante aleatoria a nivel individuo.
A fin de comprender mejor las distintas posibilidades de análisis, y obtener conclusiones, se analizan distintos modelos. Como primera aproximación se utilizó el comando xtreg del software STATA. Se realizó este modelo sobre 492 observaciones, de 164 grupos (individuos). El resultado se observa en el Cuadro 36.
Cuadro 36: Resultados de ajuste de modelo lineal mixto de ingreso deflacionado 2000 – 2005, con constante aleatoria (random intercept) a nivel individuo.

Fuente: Elaboración propia, estudio longitudinal UNTREF. No respuestas eliminadas del promedio. Valores deflacionados.
Hay tres observaciones para cada individuo (2000, 2002, 2005); el mínimo es 3 y el máximo es 3, dado que se han tomado solo las trayectorias que tienen datos para los tres años. En el modelo ajustado que se muestra en el cuadro anterior se dejó un efecto aleatorio al nivel del individuo: la constante. En este caso el valor de _cons es la media de los ingresos deflacionados (que es igual a 473,9623 $ como se había consignado en el cuadro anterior), para las n = 492 observaciones en 164 individuos en los tres años. El estadístico rho es la correlación entre las mediciones del ingreso deflacionado en distintas ocasiones para el mismo individuo (intra-class correlation). Obsérvese que ρ = 0,3763076 no es muy elevado, indicando que las observaciones repetidas entre individuos no están muy correlacionadas, o sea que estas mediciones han tenido una alta variabilidad.
El estadístico Sigma_u en este caso es igual a 213,4773, y es la estimación del desvío estándar de las constantes aleatorias (random intercepts). Esperamos que el 95 % de los valores de las constantes varíen en + / – 426,9546 (que es aproximadamente 213,4773 * 2) desde la media general (473,9623 $), es decir aproximadamente entre 47, 0077 $ y 900,9169 $; en otras palabras, un 95% de los valores de la constante estarían en estos valores. Estas variaciones corresponden a algo así como la variabilidad del punto inicial (constantes, intercepts) de los ingresos, algo que se podría conceptualizar como la desigualdad social al inicio de la serie. En este caso, esta variabilidad es alta.
El estadístico Sigma_e corresponde a la estimación del desvío estándar para los datos intraindividuos, 274,8308. Entonces esperamos que el 95 % de las mediciones repetidas de un individuo van a caer entre 549,6616 (aproximadamente 274,8308 * 2 ) unidades de la media específica de cada individuo (Dominici, 2009). Esto indica que existe una alta variabilidad en las constantes aleatorias (origen, o desde qué valores comienzan los ingresos) y también mucha variabilidad en las trayectorias de cada individuo, en las tres mediciones de cada individuo. Esto nos indicaría no solo que las trayectorias aparecen desde puntos distintos (que hablaría de una desigualdad estructural) sino también que dado un determinado valor de comienzo de los ingresos, éstos han tenido una alta variabilidad en el período.
Podemos ajustar un modelo similar para ajustar diferentes niveles de efectos mixtos. En este caso utilizaremos el comando xtmixed [85]. En este caso para la constante Bo obtendremos distintos valores para cada individuo, dado que es una descripción de su trayectoria individual, y se parten de distintos valores iniciales de ingreso individual.
Cuadro 37: Ajuste de modelo lineal mixto de ingreso deflacionado 2000 – 2005, con constante aleatoria a nivel individuo.

Fuente: Elaboración propia a partir de datos del Estudio longitudinal UNTREF). No respuestas eliminadas del promedio. Valores deflacionados.
Para calcular los valores de la correlación intraclase (CI), nos valemos de la estadística del desvío estándar al nivel de los individuos (variable ID). El resultado que se obtiene es 0,37853583 (similar al rho calculado en el modelo expuesto en el Cuadro 36); si el valor de sd (Residual) es 0, toda la variación se debe a la variación de sd (_cons). Si la variación de las constantes es 0, todos los individuos partirían de la misma constante (intercept). Si no hay variación en los errores[86], las ecuaciones para todos los individuos ajustan perfecto [87].
Ajustaremos un modelo con constante aleatoria, y predictor de un nivel. En este caso, el predictor será el año, para hacer variar las estimaciones con el tiempo (en vez de ajustar un promedio, como en el modelo anterior)[88].
Ecuación 3:
Ingredef ij = β0 + β1 añoij + ui + ɛij
para i = 1, 2, 3 años y j=1, 2, … n individuos. En este caso si i=1, J=1, esto indicaría que este modelo de ingreso se aplicaría al individuo 1 (i=1) para el primer año (j=1), 2000. Este modelo compara el ingreso deflacionado en distintos años para los individuos en 492 observaciones para 164 individuos en 3 años. El coeficiente ui es un efecto aleatorio (en este caso la constante móvil, random intercept) al nivel del individuo.
Cuadro 38: Ajuste de modelo lineal mixto de ingreso deflacionado 2000 – 2005, con predictor año y constante aleatoria (random intercept) a nivel individuo.

Fuente: Elaboración propia a partir de datos del estudio longitudinal (UNTREF). No respuestas eliminadas del promedio. Valores deflacionados.
En este caso, la primera estimación corresponde a los efectos fijos. Estimamos la constante β0 = 15032,82 y β1 = -7,270948 que es la pendiente estimada para el predictor Año — estos valores de la constante y la pendiente cambiaran en los próximos modelos, cuando centremos los datos de la variable año; el procedimiento de centrar permite una mejor interpretación y ajuste (Singer & Willet, 2003) de las ecuaciones –. La segunda estimación muestra los componentes de la varianza (random effects parameters). Como solo tenemos un efecto aleatorio en este nivel, xtmixed ajusta la covarianza con la opción Identity [89]. En este caso, sd (_cons) se estimó en 214,5733 con un error standard de 18,93645. La columna etiquetada sd (Residual) es la estimación del desvío standard del error, 274.6398. Finalmente, un test de likelihood-ratio compara este modelo a una regresión lineal ordinaria, y es altamente significativa para estos datos (con un p valor de 0.0000). Para comprender mejor el resultado, para este modelo se muestra los valores de estos coeficientes (los BLUP para el efecto aleatorio – en este caso la constante –, el valor estimado finalmente para el modelo resultando de la suma de ambos elementos xb + Zu, y los residuales). Mediante el procedimiento de postestimación de STATA, se obtuvieron las variables de la predicción lineal para los efectos fijos, los BLUP para el efecto aleatorio (constante), el valor estimado finalmente para el modelo resultando de la suma de ambos elementos xb + Zu, y los residuales. Tomemos por ejemplo dos casos, y observemos los resultados en el Cuadro 39.
Cuadro 39: Ejemplo de ajuste de modelo lineal mixto de ingreso deflacionado 2000 – 2005 para dos individuos, con predictor año y constante aleatoria (random intercept) a nivel individuo, y estimación de valores predichos, BLUP, valores ajustados y residuales.
Individuo |
Año |
Ingreso deflacionado |
A |
B |
C |
D |
|
(Ingredef) |
Predicción lineal (porción fija). Linear prediction, fixed portion |
Estimadores constante para individuo |
Valores ajustados. Fitted values: xb + Zu
|
Residuales
|
|
1 |
2000 |
270 |
490,92 |
-165,957 |
324,971 |
-54,971 |
1 |
2002 |
186,3 |
476,386 |
-165,957 |
310,429 |
-124,129 |
1 |
2005 |
195,84 |
454,573 |
-165,957 |
288,616 |
-92,776 |
2 |
2000 |
600 |
490,928 |
-48,097 |
442,830 |
157,170 |
2 |
2002 |
138 |
476,386 |
-48,097 |
428,289 |
-290,289 |
2 |
2005 |
460,8 |
454,573 |
-48,097 |
406,476 |
54,3243 |
En el primer caso, tenemos que la constante para el efecto fijo es 15032,820, y la pendiente -7,270948, por lo que para el primer individuo para el primer año (2000) – como se ve en los resultados que se exponen en el Cuadro 39 –, la estimación de la predicción lineal de los efectos fijos es 490,02 (columna A). Para el individuo 1, en el año 2000, el resultado sería:
Ecuación 4:
βo + β1 * Año = A
Para el caso del individuo 1 en el año 2000, el resultado sería:
15.032,820 + (-7,270948 * 2000) = 490,92
Este es el resultado que se observa en la columna A (etiquetada en el Cuadro 39 como linear prediction, fixed portion). Luego, existe un efecto aleatorio sobre la constante (r.e., random effect), que es distinta para cada individuo, pero igual para los tres años en los que se captó información para aquel. Para el primer caso asume el valor -165,957 y se mantiene para los tres años; para el segundo caso asume el valor -48,097, y se mantiene constante para los tres años (es decir, varió de un individuo a otro, pero no de año en año). En la columna C observamos la suma de las partes fijas y aleatorias del modelo, que dará la estimación para cada individuo. Para el individuo 1 en el año 2000, la estimación del ingreso es 490,92 -165,957 = 324,971. Luego, se observa el residuo en la columna D (residuals), que es la diferencia entre el valor real observado y el valor estimado para un individuo en un año, y la suma de la parte fija y aleatoria del modelo.
En síntesis a una regresión normal le hemos agregado un factor variable o aleatorio a la constante. Ahora agregaremos a estos valores una pendiente aleatoria, a la constante móvil.
Cuadro 40: Ajuste de modelo lineal mixto de ingreso deflacionado 2000 – 2005, con predictor año y constante aleatoria (random intercept) y pendiente aleatoria (random slope) a nivel individuo
.
Fuente: Elaboración propia a partir del Estudio longitudinal (UNTREF). No respuestas eliminadas del promedio. Valores deflacionados.
Podemos incluir en el modelo una pendiente y una constante aleatoria, que daría como resultado la Ecuación 5, como se muestra a continuación:
Ecuación 5:
yij = γ0j + γ1j xij + ij
Se especifica una ecuación adicional para la pendiente en xij, y para la constante en γ0j. Así, la constante y la pendiente se transforman en:
Ecuación 6:
γ0j = β00 + u0j
γ1j = β10 + u1j
La ecuación adicional para la pendiente γ1j consiste en la media general de la pendiente β10, y una pendiente específica[90] para el agrupamiento (específico del cluster, o cluster specific) que en este caso corresponde al parámetro u1j. Sustituimos las dos últimas ecuaciones para un modelo en forma reducida, tal como se observa en la siguiente ecuación.
Ecuación 7:
yij = (β00 + u0j ) + (β10 + u1j ) xij + ij = β00 + β10xij + u0j + u1jxij + ij
Para esta aplicación se centraron los datos de la variable temporal (anio)[91]. Se tomó el valor de 2002,5 para centrar, considerando un período de 2000 a 2005 de 5 años.
Cuadro 41: Ajuste de modelo lineal mixto de ingreso deflacionado 2000 – 2005, con constante aleatoria y pendiente aleatoria a nivel individuo, valores de año centrados, covarianza independiente.

Fuente: Elaboración propia a partir del Estudio longitudinal (UNTREF). No respuestas eliminadas del promedio. Valores deflacionados.
Centrando los datos, logramos que la constante del modelo de regresión coincida aproximadamente con la media de la muestra (472,7505, como se consigna en el Cuadro 41).
También, se ajustó un modelo multinivel lineal mixto con covariancia no estructurada, y se obtuvo la correlación entre las estimaciones de las constantes aleatorias y las pendientes aleatorias.
Cuadro 42: Ajuste de modelo lineal mixto de ingreso deflacionado 2000 – 2005, con constante aleatoria y pendiente aleatoria a nivel individuo, valores de año centrados, y covarianza no estructurada.

Fuente: Elaboración propia a partir del Estudio longitudinal (UNTREF). No respuestas eliminadas del promedio. Valores deflacionados.
En principio, el efecto de la variable temporal centrada (que en el Cuadro 42 se denomina canio[92] es un efecto no significativo ( -7,270948), y tiene un valor de z pequeño ( -1,19), por lo que no hay evidencia para afirmar que haya un ‘efecto de la variable año’, o crecimiento diferente de cero. El IC (intervalo de confianza) contiene ampliamente al cero en este caso (esta conclusión se obtiene del intervalo de confianza, etiquetado 95% Conf. Interval). Esto estaría indicando que no existe un efecto de aumento de los ingresos en el periodo que fuese estadísticamente significativo[93].
Guardando los BLUPS mediante el procedimiento de postestimación (etiquetados como r.e. for id: canio y r.e. for id: _cons), se observa que el 52,4 % de estos tuvieron pendientes positivas o 0, y 47,6 % tuvieron pendientes negativas. Se sabe, que por las características de las estimaciones multinivel, estas no informan en forma definitiva sobre si las tendencias generales de una regresión se cumplen en cada individuo (Nezlek, 2015). El LR test en la tabla (LR test vs. Linear regression: chi2 = 67,25, p=0,000) nos informa la mejora de estos modelos frente a un modelo de regresión sin desagregación a nivel de grupo [94]. En este caso, el resultado es significativo, lo cual indica que la estimación de la regresión multinivel mejora la estimación, comparando ésta con una regresión normal.
Por otro lado, la alta correlación negativa (-0,8684819) obtenida entre la constante y la variable canio indica que a mayor nivel de ingreso al inicio (es decir, a mayor valor en la constante, o intercept), las pendientes de crecimiento del ingreso tienden a ser menores.
La variabilidad de las constantes sd (_cons) nos informa de los diversidad de los puntos de origen, es decir de la desigualdad en la distribución inicial del ingreso; la de las trayectorias de los ingresos sd (canio) nos informa cómo se modificaron las trayectorias en los cinco años, más allá de la desigualdad en el punto de inicio (variabilidad de las constantes). El alto desvío en sd (canio) indica que hubo diferentes capacidades para absorber o aprovechar mejoramientos contextuales (o en un sentido inverso, detener los efectos nocivos de las crisis).
Si bien los ingresos en la vida de los individuos fluctúan, y existen situaciones en las que éstos pierden o disminuyen sus ingresos, no se suele esperar en situaciones normales una caída de ingresos sostenida y generalizada en el tiempo, o una variación positiva o negativa muy marcada de los montos de los ingresos individuales en un período breve de cinco años. Aunque esta afirmación no es objeto de estudio empírico, posiblemente la variabilidad de las trayectorias se correspondan con un proceso de crisis. Es necesario tener en cuenta los acontecimientos o sucesos que dan marco a este tipo de evoluciones. En este caso, sin la referencia a la crisis, perderíamos capacidad analítica del fenómeno y sus variaciones.
- Maletta (2002) realiza una sistematización del análisis de variables categóricas en estudios longitudinales.↵
- De acuerdo a los estudios de Saussure, el enfoque sincrónico observa la lengua desde el punto de vista estático. Consiste en hacer un corte temporal y determinar las pautas que en ese momento componen la lengua aceptada por la comunidad lingüística. El enfoque diacrónico, en cambio, permite destacar la relación que vincula a la lengua con el habla, y examina la evolución de la lengua a través del tiempo: el modo en el que se modifican los significados de las palabras, aparecen nuevos vocablos y otros se tornan arcaicos, la construcción gramatical y el estilo va cambiando sus reglas o se modifica a lo largo de los siglos.↵
- En cierto modo, la identificación de estos problemas puede servir como lecciones aprendidas para otros investigadores que aborden problemas similares.↵
- Si estudiamos el desgaste de las cubiertas de los autos, el paso del tiempo podría medirse como kilómetros recorridos, por ejemplo (Singer & Willet, 2003). ↵
- El proyecto de investigación (código 32/0028), se desarrolló entre 2000 y 2010, y contó con financiamiento de la Universidad Nacional de Tres de Febrero, y con el apoyo operativo del Centro de Investigación en Estadísticas Aplicadas de la UNTREF. En este estudio, se contó con el apoyo de alumnos, becarios y profesores de la Licenciatura en Estadística de la UNTREF. En esta investigación se captó en forma sistemática desde el año 2000 la evolución en el tiempo de la situación patrimonial, las características de la inserción laboral y de las tareas productivas y reproductivas de los distintos miembros de los hogares, los patrones de utilización y acceso a los servicios básicos y sociales públicos y privatizados. En base a la información captada en los tres periodos, se realizaron distintos procesamientos de la información. En 2012 se realizaron distintos tipos de ajustes de modelos lineales mixtos. A través de la mirada diacrónica de la evolución de los individuos entre el año 2000 y 2005 respecto a la condición de pobreza se ha construido una tipología que ha permitido detectar información sobre el grupo más vulnerable, el de los individuos que han vivido en hogares pobres en los dos años relevados (pobre crónico).↵
- Entre ella podemos destacar: 2013, Conversatorio “Metodologías de investigación en procesos de cambios social”, FACes, Universidad Central de Venezuela, Caracas, 14/11/2013. 2014. “Los desafíos metodológicos del paso del tiempo en las ciencias sociales”, ponencia aceptada en el IV Encuentro Latinoamericano de Metodología de las Ciencias Sociales (ELMeCS, Heredia, Costa Rica), 25-29 de agosto de 2014. 2011. “Metodología y modelos estadísticos para el análisis de las redes sociales”, “II Encuentro Latinoamericano de las Ciencias Sociales. Continuidades, rupturas y emergencias de la investigación científica en América Latina”, Sonora, México, 2011. Ponencia “Análisis de la evolución de las condiciones sociolaborales y de ingreso de los hogares en el Partido de Tres de Febrero (Argentina) en el período 1999-2009 mediante la aplicación de metodologías de análisis longitudinal”, III Encuentro Latinoamericano de Metodología de las Ciencias Sociales (ELMeCS), Manizales, Colombia,l 30-31 de agosto y 1 de septiembre de 2012. “Estudio longitudinal de la evolución de las condiciones de vida y de ingreso de los hogares en el partido de Tres de Febrero”, 1era. Jornada de investigación, UNTREF, 8 de mayo de 2012. Caseros II, UNTREF. 2008. Ponencia “Análisis longitudinal de la evolución de la pobreza y la inserción en el mercado de trabajo de los hogares en el partido de Tres de Febrero en el período 1999-2009”, V Jornadas de Sociología de la UNLP y I Encuentro Latinoamericano de Metodología de las Ciencias Sociales, La Plata, 10, 11 y 12 de diciembre de 2008. La información captada fue utilizada en los cursos de la carrera de Licenciatura en Estadística de la Universidad Nacional de Tres de Febrero, y en el marco de las cátedras de posgrado en la Maestría en Generación y Análisis de Información Estadística (MGAIE) y de la Maestría en Investigación Social (UNIBO-UNTREF).↵
- Entre ellas, en los libros, 2013. “Investigación social para el análisis de la opinión pública y el comportamiento electoral”, Oliva y De Angelis (2013), “Aplicaciones de software estadístico”, Oliva, Perez Candevra (2010). ↵
- El día 20 de diciembre se hacía cargo del poder ejecutivo el presidente de la Cámara de Senadores Ramón Puerta, quién convocó a una asamblea legislativa para elegir un nuevo presidente. El día 23 asumía la presidencia Adolfo Rodríguez Saá también del partido opositor. El 30 de diciembre renunciaba Rodríguez Saá, alegando falta de apoyo político, lo que desencadenó una nueva ola de inestabilidad. Ante la negativa de Puerta, el presidente de la Cámara de Diputados Eduardo Camaño asumía el poder ejecutivo y también convocaba a una Asamblea Legislativa para nombrar un nuevo presidente.
El 2 de enero de 2002 asumía Eduardo Duhalde, el candidato a presidente que había perdido ante De la Rúa en 1999, como presidente interino.↵ - Para el total del país, existió un crecimiento demográfico más elevado (10,6 %).↵
- Existen diversos complejos habitacionales en la localidad de Tres de Febrero donde residen hogares en mayor medida hogares humildes. Entre ellos, se destaca, en el Barrio Ejército de los Andes, el popularmente llamado Fuerte Apache, que es un complejo habitacional que se encuentra en el sector norte de la localidad de Ciudadela. Según el Censo 2001, en estas 26 hectáreas donde funcionan almacenes en los pisos altos, a veces se levantan paredes en los palieres de entrada y hasta los pasillos llevan reja, hay 4.657 viviendas habitadas por alrededor de 35.000 personas. El barrio surgió a fines del gobierno de facto de la Revolución Argentina, como parte del Plan de Erradicación de Villas de Emergencia (PEVE) comenzado en 1968, con el propósito de reubicar a los habitantes de la Villa 31 de Retiro. La primera tanda de personas ocupó sus departamentos en mayo de 1973, al tiempo que Héctor Cámpora asumía la presidencia. Sus habitantes llamaron al barrio Padre Carlos Mugica en honor al cura tercermundista asesinado en mayo de 1974 que había trabajado en la Villa 31. El crecimiento demográfico del barrio llevó la población a niveles que triplicaron los 22.000 habitantes para los cuales estaba preparado el conjunto.↵
- Esta proporción es algo mayor que la que se observa en la provincia de Buenos Aires en su conjunto, con 78,4 % de los hogares con este tipo de materiales. El material predominante de los techos de las viviendas en esta localidad es baldosa con cielorraso.↵
- Es probable que por las características del distrito de Tres de Febrero, los procesos hayan sido similares a los otros partidos del Conurbano Bonaerense. ↵
- “La rotación planificada de las muestras se sobrepone a un proceso no planificado de desgranamiento (attrition). De una onda a otra hay siempre algunos sujetos que “desaparecen” de la muestra por distintas razones: muerte, emigración o cambio de domicilio, negativa a seguir en el estudio, etc”. (Maletta, 2012, 13). ↵
- “Algunas de estas desapariciones pueden ser por causas “sustantivas”, que de por sí constituyen un dato, por ejemplo la muerte o la emigración. En otros casos se trata de una ´desaparición´ cuya causa se desconoce o de un rechazo a la nueva entrevista. En el caso de las encuestas de hogares puede haber hogares completos que ´desaparecen´ y también individuos determinados que dejan de aparecer dentro de algunos hogares aun cuando el hogar como tal siga incluido en la muestra” (Maletta, 2012, 13).↵
- Agradezco a Gustavo Kremer por la elaboración del proceso de matcheo de las bases de datos.↵
- Es la misma metodología y las definiciones habituales que utilizaba en ese momento el organismo nacional de estadísticas INDEC (a partir de 2013 el INDEC discontinúa esas mediciones de pobreza).↵
- La heterogeneidad y complejidad de la pobreza torna necesaria la identificación y diferenciación de distintos tipos de pobreza. Convencionalmente, la pobreza era definida en términos de ingreso o el gasto asumiendo que el standard de vida material de una persona determina mayormente su calidad de vida, aunque en este fenómeno existen aspectos de exclusión social que trascienden la perspectiva estrictamente económica. ↵
- El método basado en la línea de pobreza (CEPA, 1994) presupone “la determinación de una canasta básica de bienes y servicios, respetando las pautas culturales de consumo de una sociedad en un momento histórico determinado” (Minujin, 1997). También podría calcularse el monto de la canasta básica menos el ingreso total familiar corregido por equivalente adulto (sería similar a calcular cuánto dinero falta en el ingreso per cápita familiar para salir del episodio de pobreza en el hogar, o por cuánto dinero un hogar supera el monto de la Canasta Básica).↵
- Ver como referencia el documento de la Comisión Asesora para la medición de la pobreza en Chile, creado por decreto Decreto 18 “Crea Comisión Asesora Presidencial de Expertos para la Actualización de la Línea de la Pobreza y de la Pobreza Extrema”, publicado el día 22 de enero de 2013. Disponible en: http://bcn.cl/17qmd. ↵
- Más información sobre la medición de pobreza del Banco Mundial en: http://povertydata.worldbank.org/poverty/home/. Los valores son expresados en valores en Paridad de Poder Adquisitivo, “an economic theory that estimates the amount of adjustment needed on the exchange rate between countries in order for the exchange to be equivalent to each currency’s purchasing power”. Consultado en http://www.investopedia.com/terms/p/ppp.asp (Agosto 2015).↵
- Varios estudios han sido compilados en “La Argentina democrática: los años y los libros. Prometeo, 2007” (Camou et al., 2007). ↵
- El CEDLAS fue creado en 2002 dentro de la Maestría en Economía de la Universidad Nacional de La Plata, y funciona en la Facultad de Ciencias Económicas de la UNLP.↵
- Estos autores aprovechando el esquema de rotación presente en el diseño muestral de la EPH “se construyeron paneles sucesivos para el período 1997-2012 que permiten descomponer la pobreza en sus componentes crónicos y transitorios. La amplitud del periodo de cobertura analizado permite capturar distintas etapas distributivas en Argentina durante las últimas dos décadas”. Con relación a los componentes transitorios y crónicos de la pobreza, los autores señalan que “Algunos de ellos son originados por situaciones extraordinarias e inesperadas con un impacto efímero sobre el ingreso, mientras que otros tienen un efecto más duradero sobre el poder adquisitivo del hogar. Es por eso que se considera que la variabilidad del ingreso está afectada por componentes transitorios y permanentes. El estudio de sus determinantes es relevante en términos del enfoque de la política económica, ya que permite distinguir distintos canales de acción e identificar las diferencias existentes entre aquellas medidas orientadas a conseguir reducciones duraderas en los niveles de pobreza de otras iniciativas que tratan de mitigar el riesgo o vulnerabilidad de la pobreza” (Alejo & Garganta, 2014, 3).↵
- En el capitalismo, la transmisión del patrimonio y el capital de una generación a otra, se realiza en términos generales mediante un criterio que sigue un camino genético, organizado socialmente a través de la estructura familiar (Oliva, 2006, 2008; Oliva, 2010a). Por ello ocurre que el nivel socioeconómico o la pobreza, habitualmente se construye a partir de una caracterización del hogar (y no como una propiedad puramente individual). En ese sentido es un criterio, y podría haber otros para transmitir la propiedad privada. Es decir, no es un fenómeno natural, sino cultural, que cuando un individuo se muera, la propiedad se traspase a los hijos, o a individuos con lazos de sangre o genéticos, como el poder en los tiempos de los reyes, o los apellidos. ↵
- Álvaro F. López Lara, Renata Beltrán Bonilla; “El análisis dinámico de la pobreza. Enfoques, metodología y hallazgos” (s/d). ↵
- Existen dos abordajes principales en la construcción de la línea de pobreza (Falkingham, Klugman, Marnie, & Micklewright, 1997); una definición absoluta, que asume la posibilidad de definir un standard mínimo de vida en función de las necesidades psicológicas de acceso a vivienda, comida, vestimenta, y otros bienes básicos, y una definición relativa que define a la pobreza en relación a un standard de vida aceptado en una sociedad en un contexto histórico determinado (Falkingham, 1999; Jane Falkingham & Harding, 1996).↵
- Estas cifras fueron anteriores a los conocidos problemas institucionales que sufrió el organismo de estadísticas nacional, y que luego derivó en una discontinuación de este tipo de medidas de la Canasta Básica Alimentaria (y de la pobreza por ingreso en general). Durante el año 2013 / 2014 se discontinuó la medición de pobreza por ingresos en el INDEC. En 2007 hubo una intervención del gobierno al Instituto Nacional de Estadísticas (INDEC), que derivó en fuertes cuestionamientos a los datos de inflación que calcula este organismo, creando problemas en las estimaciones de la Canasta y otras estadísticas relacionadas, como la población bajo la línea de pobreza por ingresos.↵
- Los porcentajes referidos a personas utilizan la clasificación pobre/no pobre e indigente/no indigente definida para los hogares. Esto significa que una persona es pobre o indigente si pertenece a un hogar pobre o indigente.↵
- INFORMACIÓN DE PRENSA, Buenos Aires, 2 de febrero de 2001.↵
- El concepto de línea de indigencia (LI) procura establecer si los hogares cuentan con ingresos suficientes como para cubrir una canasta de alimentos capaz de satisfacer un umbral mínimo de necesidades energéticas y proteicas. De esta manera, los hogares que no superan ese umbral, o línea, son considerados indigentes. El procedimiento parte de utilizar una Canasta Básica de Alimentos de costo mínimo (CBA) determinada en función de los hábitos de consumo de la población definida como población de referencia en base a los resultados de la Encuesta de Gastos e Ingresos de los Hogares de 1985/86, para los datos del año 2000. ↵
- INCIDENCIA DE LA POBREZA Y DE LA INDIGENCIA EN EL AGLOMERADO GRAN BUENOS AIRES. MAYO 2002, Informe de prensa, ISSN 0327-7968.↵
- En general, no se analizó de un modo panel por las dificultades que implicaba su análisis en distintas ondas. ↵
- Este comentario me fue sugerido por el rector de la UNTREF, el Dr. Aníbal Jozami. ↵
- “Los estados son las varias categorías de una variable de tipo cualitativo en las cuales puede resultar clasificado un sujeto o unidad de análisis en un momento determinado. Los eventos no son otra cosa que los cambios de estado (manifiestos o latentes) de los sujetos. Por ejemplo, si los estados son “ocupado” y “desocupado”, un evento sería el paso de una situación a otra (encontrar empleo, o quedar sin trabajo). Los procesos, también llamados trayectorias, son secuencias de eventos a lo largo de un período de tiempo. Cuando se registra el estado del sujeto en dos rondas del panel, la secuencia manifiesta es simplemente el pasaje de su estado en la primera ronda a su estado en la segunda, pero si el proceso subyacente es un proceso que opera en plazos más breves, o es un proceso continuo, podría haber una secuencia no registrada de eventos intermedios. Por ejemplo, si el sujeto estaba ocupado en ambas rondas, podría haber tenido de todas maneras algún período no registrado de desocupación en el lapso intermedio” (Maletta, 2002).↵
- “Si el estado es “tener 30 años de edad” los eventos relevantes podría ser “cumplir 30 años” y “cumplir 31 años”. El primero de estos eventos constituye la “entrada” en la situación de tener 30 años, y el segundo corresponde a la “salida” o “egreso” (otro posible “egreso” sería morir antes de cumplir 31)” (Maletta, 2002, 2012).↵
- “La rotación planificada de las muestras se sobrepone a un proceso no planificado de desgranamiento (attrition). De una onda a otra hay siempre algunos sujetos que “desaparecen” de la muestra por distintas razones: muerte, emigración o cambio de domicilio, negativa a seguir en el estudio, etc. Algunas de estas desapariciones pueden ser por causas “sustantivas”, que de por sí constituyen un dato, por ejemplo la muerte o la emigración. En otros casos se trata de una “desaparición” cuya causa se desconoce, o de un rechazo a la nueva entrevista. En el caso de las encuestas de hogares puede haber hogares completos que “desaparecen” y también individuos determinados que dejan de aparecer dentro de algunos hogares aun cuando el hogar como tal siga incluido en la muestra” (Maletta, 2012, 13). ↵
- El término “estados” indica la categoría de una variable en la que es clasificado un sujeto en determinada ocasión, de acuerdo a la terminología utilizada por Maletta (2012)↵
- Salvia describe la situación de crisis en este período en un contexto más amplio de una evolución histórica de Argentina, atípica en el capitalismo periférico; “El desempeño económico de la Argentina ha sido catalogado más de una vez como paradójico, a la luz de las teorías del desarrollo. Desde la conformación del Estado nacional el país registró un proceso de modernización que se extendió hasta la década de 1970. A partir de ese momento, la temprana transición capitalista parece haber mutado hacia un estado de subdesarrollo, convirtiendo al país en un prototipo poco común entre las naciones con economía de libre mercado”. Luego señala “Fue en este contexto, a través de una serie de reformas estructurales orientadas a generar una amplia apertura comercial y desregulación de los mercados, que la economía logró –entre 1992 y 2001– controlar la hiperinflación y retomar un sendero de crecimiento. Esta política incluía, además de una serie de medidas de ajuste y el establecimiento de un régimen de paridad fija denominado “régimen de convertibilidad”, una radicalizada aplicación de medidas de privatización, liberalización financiera, apertura económica, flexibilidad laboral, reconversión ocupacional y asistencia social. Este programa económico fue presentado por el establishment como una solución definitiva al estancamiento estructural que experimentaba el capitalismo argentino. Sin embargo, después de una recuperación inicial, la pobreza y la desigualdad distributiva volvieron a crecer, cerrándose la década con una fenomenal crisis económico-financiera, todo lo cual agravó aún más la situación económico-ocupacional y la conflictividad social. Por último, durante 2003, gracias a un nuevo régimen monetario y un entorno internacional favorable, la economía y los indicadores sociales del país experimentaron una rápida recuperación, dando inicio a un nuevo período de crecimiento económico” (Salvia, 2012, 13-14). ↵
- Considerando dos ocasiones, en caso de haber tres estados (por ejemplo A, B y C), el número de trayectorias aumenta a nueve posibilidades (AA, AB, AC, BA, BB, BC, CA, CB, CC). ↵
- El número de trayectorias posibles aumenta notablemente cuando se consideran tres o más rondas. Por ejemplo, con solo dos estados A y B, pero con tres rondas, las trayectorias posibles serían A→A→A, A→A→B, A→B→A, A→B→B para el estado inicial A, y otras cuatro similares para quienes arrancan en el otro estado B: B→A→A, B→A→B, B→B→A, B→B→B.↵
- Con tres estados y tres rondas habría 3³=27 trayectorias posibles. El número total aumenta muy velozmente: tres estados con cinco rondas generan 243 trayectorias, y los mismos tres estados con diez rondas implican 59.049 trayectorias posibles↵
- “Ningún divorciado o soltero puede pasar a ser viudo, ningún viudo o casado puede pasar a ser soltero. Estas exclusiones obedecen a dos clases de razones. Algunos eventos son directamente imposibles, mientras que otros son posibles pero sólo si se admite la existencia de eventos intermedios no registrados. Es posible que una persona aparezca como soltera la primera vez y como viuda en la segunda, pero ello implica que en el período intermedio se casó y luego enviudó. Nadie puede pasar de soltero a viudo, a menos que en el ínterin se haya casado” (Maletta, 2012, 18).↵
- Una vez emparejados o matcheados, las bases de datos pueden tener, siguiendo la terminología de Singer y Willet (2013), un formato “persona – periodo” — person period dataset – o “persona nivel” — person level — (Singer & Willet, 2003). ↵
- “La característica distintiva de un conjunto de datos a nivel de personas es que cada persona tiene sólo una fila de los datos, sin importar el número de series de recogida de datos. La principal ventaja de este tipo de formato de base de datos es la facilidad con la que se puede examinar visualmente el registro empírico de crecimiento de cada persona, sus resultados forman una secuencia temporal. La trayectoria de crecimiento empírico de cada persona aparece de forma compacta en una sola fila, por lo que es fácil de evaluar rápidamente la manera en que cambia a través del tiempo. En este formato no se puede manejar con facilidad la presencia de variables predictoras de la variación en el tiempo: si la base de datos contiene predictores que varían en el tiempo, necesitaríamos un conjunto adicional de columnas para cada uno – uno por cada onda de medición. Por estas desventajas, se recomienda que en el análisis de datos longitudinales se utilice el formato de persona-tiempo para sus datos, ya que se facilita y se hace más significativo el análisis” (Singer & Willet, 2003).↵
- En el software SPSS, este procedimiento de cambiar de estructura de base de datos se puede realizar mediante el procedimiento VARSTOCASES (SPSS, 2005).↵
- En el caso de la pobreza tenemos 428 casos con registros en las tres ondas, es decir con trayectorias completas, y esa será la base de análisis para describir las trayectorias. La suma de la multiplicación de 428 * 3 (años) + 464 * 2 (años) + 832 * 1 (año) da un total de 3.044, que es valor del total de registros de estados que contabilizamos en el Cuadro 13. Cuando registramos como estados en el formato “persona – período” cada individuo tiene tres registros, por lo tanto tienen 5.172 estados, es decir 1.724 * 3 (años) – cada uno de los casos aporta 3 líneas de registro, aunque en los casos de 1 o 2 datos por año, haya registros sin información – (Cuadro 45 del Anexo).↵
- Combinando las situaciones respecto de la pobreza (pobre – no pobre) en el punto inicial (2000) y el final (2005), es posible obtener la siguiente tipología de trayectorias: a) no pobre: aquellos individuos que han quedado excluidos de la clasificación de pobreza en ambos momentos; b) movilidad ascendente o nuevos no pobres: han pasado de una situación de pobreza a una de no pobreza; c) movilidad descendente o nuevos pobres: van de una situación de no pobreza a una de pobreza, y habitualmente se los denomina “nuevos pobres” (Minujin, 1997); d) pobres crónicos, personas que viven en hogares pobres por ingreso en ambos períodos. En este caso estaríamos tomando el principio y el final de las trayectorias.↵
- Una clasificación habitual es considerar a los pobres estructurales como los individuos que habitan hogares pobres según NBI, y los nuevos pobres (Minujin, 1997), a los individuos que no se encuentran en hogares con NBI, pero cuyos ingresos caen por debajo de la Línea de Pobreza. Los no pobres eran los individuos que no están en hogares pobres por NBI y cuyos ingresos superan la Línea de Pobreza (Minujin, 1997).↵
- “Uno de los efectos de la vulnerabilidad social es que los hogares se ven compelidos a insertarse en el mercado de trabajo en condiciones extremadamente desfavorables. En ese contexto, la definición de estrategias de vida con perspectivas de largo alcance se ven reemplazadas por decisiones de carácter meramente cortoplacista (decisiones tácticas). Por el contrario, la existencia de suficientes puestos de trabajo disponibles de calidad aceptable permitiría a los hogares elegir mejor los tiempos y características” (Feliz, 2001, 5). ↵
- Utilizando la terminología de los econometristas, time invariant (Hsiao, 1986) .↵
- Como se observa en el cuestionario utilizado (ver el formulario completo en el Anexo), las categorías utilizadas para la clasificación del nivel educativo fueron 1 “Primario incompleto”, 2 “Primario completo – secundario incompleto”, 3 “Secundario completo – terciario universitario incompleto”, 4 “Universitario completo – posgrado”. En la construcción de estas categoría se consultó por el nivel que actualmente cursa o curso y si termino o no ese nivel, junto con el ultimo grado aprobado. Este tipo de información, y las respuestas a estas preguntas, en algunos casos parece difícil que coincida exactamente en un estudio panel. ↵
- Este comentario (que me fuera realizada por el Dr. Agustín Salvia) se discute en el apartado titulado variables de hogar e individuales.↵
- Para estas aplicaciones, utilizaremos las definiciones habituales de las tasas que describen en mercado de trabajo (Oliva, 2010a). Las principales definiciones son:
Población desocupada: se refiere a personas que, no teniendo ocupación, están buscando activamente trabajo. Este concepto no incluye otras formas de precariedad laboral tales como personas que realizan trabajos transitorios mientras buscan activamente una ocupación, aquellas que trabajan jornadas involuntariamente por debajo de lo normal, a los desocupados que han suspendido la búsqueda por falta de oportunidades visibles de empleo, a los ocupados en puestos por debajo de la remuneración vital mínima o en puestos por debajo de su calificación, etcétera. Población económicamente activa: la integran las personas que tienen una ocupación o que sin tenerla la están buscando activamente. Está compuesta por la población ocupada más la población desocupada. Tasa de actividad: calculada como porcentaje entre la población económicamente activa y la población total. Tasa de empleo: calculada como porcentaje entre la población ocupada y la población total. Tasa de desocupación: calculada como porcentaje entre la población desocupada y la población económicamente activa. Semana de referencia: es la semana calendario completa que precede a la iniciación del relevamiento. Las estimaciones de las Tasas relativas a la situación ocupacional se refieren a las condiciones existentes en la semana de referencia. ↵ - Estos valores son indicativos, dado que sólo hay 25 registros de individuos con estas trayectorias.↵
- Como indicaba Karl Pearson en su famosa frase, “correlation is not causation” (este comentario me fue sugerido por Juan Piovani).↵
- En otros estudios a partir de estos datos (Oliva, Masello, Cha, 2009), observamos que la “inserción laboral es mayoritariamente como cuentapropistas, posiblemente en puestos de trabajo autogenerados a partir del capital humano y de las relaciones que poseen, con altos niveles de precariedad (posibilidades de trabajar menos de 35 horas, sin jubilación ni obra social). A su vez, no son puestos de trabajo permanentes sino que suelen ser changas (trabajos eventuales, habitualmente de baja calificación y remuneración). Finalmente, por el tamaño del establecimiento se puede especular que en este grupo se inserta en puestos de trabajo de baja productividad (fuertemente condicionado por la ausencia de tecnología o máquinas/herramientas). Resumiendo, se observó en los pobres crónicos una forma de inserción en el mercado de trabajo significativamente distinta al resto. Esta dimensión podría estar desempeñando un papel explicativo de la condición de pobreza crónica ya que, la probabilidad de estar y permanecer dentro de este grupo estaría condicionada por el tipo de empleo que estas personas pueden tener”. ↵
- Posiblemente aquí también actúen otros mecanismos informales de exclusión social, como el hecho de ser migrante (como vimos, hay una proporción del 8 % de individuos que no nacieron en el país, compuesto en general por personas de nacionalidad paraguaya mayormente).↵
- “El concepto de vulnerabilidad se refiere a aquellas numerosas situaciones intermedias, de exclusión en algunas esferas e inclusión en otras. La vulnerabilidad no lleva necesariamente a la exclusión. En algunas ocasiones los individuos logran superar las condiciones de riesgo (por ejemplo, a través de sus estrategias vitales) evitando caer en la exclusión. Pero en otras ocasiones, se produce el proceso inverso hasta que el incremento de las dificultades conduce inevitablemente a la exclusión. Se podría decir que si bien el proceso es dinámico, la condición de vulnerabilidad que se constituye en la Argentina de fin de siglo es permanente y es característica de la estructura social (Minujin, 1998)” (Féliz, Deledicque, & Sergio, 2001, p. 2) .↵
- “Esta advertencia anticipa que si se comparan los cambios ocurridos en períodos de diferente longitud, los porcentajes o probabilidades de cambio no serán comparables, a menos que todas ellas sean normalizadas, es decir reducidas a un común denominador temporal (convirtiéndolas por ejemplo en tasas anuales, bajo el supuesto de que el período empírico puede ser extrapolado o interpolado para estimar la probabilidad anual)” (Maletta, 2012).↵
- Esta observación me fue sugerida por el Dr. Agustín Salvia. ↵
- El autor supone sujetos racionales y auto interesados –pero no egoístas– que por estar detrás de un velo de ignorancia, no conocen su posición dentro de la estructura de la sociedad en cual, desearán regirse por los principios de justicia. Rawls (1971) destaca que “entre los rasgos esenciales de esta situación [la posición original], está el de que nadie sabe cuál es su lugar en la sociedad, su posición, clase o status social; nadie conoce tampoco cuál es su suerte con respecto a la distribución de ventajas y capacidades naturales, su inteligencia, su fortaleza, etc. (…) Los principios de la justicia se escogen tras un velo de ignorancia. Esto asegura que los resultados del azar natural o de las contingencias de las circunstancias sociales no darán a nadie ventajas ni desventajas al escoger los principios” (Rawls, 1971, 16).↵
- “Una medición multidimensional de la pobreza acotada a las necesidades básicas insatisfechas (NBI) muestra que carencias como la falta de agua potable o sistemas apropiados de saneamiento todavía afectan a un conjunto importante de hogares y personas en nuestro país. Ello conduce a preguntarse si las políticas públicas destinadas a la superación de la pobreza están poniendo suficiente énfasis en el logro de estándares absolutos de bienestar fundado en los derechos sociales. Una mirada más amplia de la pobreza que incluya la autonomía y la libertad de agencia que brindan los ingresos, así como las carencias sociales que por derecho social deberían estar erradicadas, permite hacer exigible al Estado una responsabilidad política superadora de esas miserias actuales. En esta misma línea argumental, cabe recordar que el Observatorio de la Deuda Social Argentina define la “deuda social” como el conjunto de privaciones económicas, sociales, políticas, psicosociales y culturales que recortan, frustran o limitan de manera injusta el desarrollo de las capacidades de desarrollo humano y de integración social. Tal como se ha explicitado en otros trabajos, esta perspectiva se apoya en tres líneas de antecedentes: a) los estudios sobre el desarrollo humano; b) la teorías sobre las estructuraciones sociales; y c) el enfoque normativo basado de los derechos económicos, sociales, políticos y culturales” (Salvia & Tami, 2005, 217).↵
- De un modo similar, tampoco hay acuerdo sobre si la clase social a la que pertenece un individuo, dado un intento de operacionalización de ese concepto, debería ser una característica del hogar, o del individuo (Oliva, 2006). Es decir, sobre si un individuo proletario puede vivir en un hogar burgués, y ese tipo de preguntas empíricas. ↵
- La unidad de análisis del enfoque de Torrado es la unidad familiar o doméstica. La definición propuesta por la autora es la siguiente: “grupo de personas que interactúan en forma cotidiana, regular y permanentemente, a fin de asegurar mancomunadamente el logro de los siguientes objetivos: su reproducción biológica, la preservación de su vida; el cumplimiento de todas aquellas prácticas económicas y no económicas, indispensables para la optimización de sus condiciones materiales y no materiales de existencia” (Torrado, 1982: 20).↵
- “Al analizar el hogar partimos, por lo tanto, del hecho de que los vínculos económicos y sociales que trae aparejada la pertenencia de la mayoría de los individuos a hogares determinados pueden llevar a respuestas familiares, en vez de individuales, frente a contracciones o expansiones en la demanda de la fuerza de trabajo (Gómez, 2001). Por lo tanto, la entrada de un trabajador adicional a la población económicamente activa, estaría determinada no sólo por las condiciones generales del mercado de trabajo –dimensión macroeconómica-, sino también por las condiciones particulares de cada hogar – dimensión microsocial – “ (Feliz, 2001, 7).↵
- Para imputar el ITF se recurrió primero a la pregunta promedio de ingreso: esta pregunta indaga sobre el promedio de ingreso en lo últimos tres meses. Se pensó principalmente como una forma de recabar información de las personas ocupadas que no quisiesen contestar sobre su ingreso en el mes previo a la encuesta. Si esta pregunta era contestada, se imputaba su valor a una no respuesta del ingreso total individual (ITI). En el resto de los casos (no respuesta tanto en Ingreso promedio como ITI) se aplicó el método Hot-deck para imputar, tomando como variables clasificadoras: condición de actividad, nivel educativo, tramo de edad, sexo y “tipo de inactivo”, relación de parentesco. Este método consiste, aproximadamente, en imputar un valor faltante con un valor declarado de un individuo elegido al azar con las características similares a la que presenta la no respuesta.↵
- Ver en el Anexo el criterio para el cálculo de Equivalente Adulto, a partir de las tablas del INDEC.↵
- Los valores de los deflactores con base 2000 = 100, fueron 0,69 para 2002, 0,576 para 2005. Ver Anexo para ver la serie deflacionada del IPC del GBA del INDEC desde el año 2000 al 2005.↵
- En este caso podría pensarse que la religión no es estrictamente invariante, aunque existen pocos cambios de religión en la vida de una persona. ↵
- “Fixed Effects models don’t allow time-invariant variables because you use FE precisely to make those constant and “control” for individual characteristics (Stata will drop these due to collinearity with the id)”. Consultado en 2015, STAtaBLOG. http://blog.stata.com/ ↵
- “The key insight is that if the unobserved variable does not change over time, then any changes in the dependent variable must be due to influences other than these fixed characteristics” (Stock and Watson, 2003, 289-290).↵
- “In estimating the causal effect of education on wage, we might focus on E (wage|educ, exper,abil) where educ is years of schooling, exper is years of workforce experience, and abil is innate ability. In this case, c = (exper, abil), where exper is observed but abil is not” (Wooldridge, 2010, 3).↵
- Tomado de la clase pública https://www.youtube.com/watch?v=f817HdHJneo, del profesor Nezlek, Publicado el 24 feb. 2015 “An Introduction to Multilevel Modeling – basic terms and research examples”, John B. Nezlek, College of William & Mary. Consultado Agosto 2015.↵
- “The linear mixed model is an extension of the general linear model, in which factors and covariates are assumed to have a linear relationship to the dependent variable. Categorical predictors should be selected as factors in the model. Each level of a factor can have a different linear effect on the value of the dependent variable. Fixed-effects factors are generally thought of as variables whose values of interest are all represented in the data file. Random-effects factors are variables whose values in the data file can be considered a random sample from a larger population of values” (https://bit.ly/2V8ARXJ).↵
- “En primer lugar, los análisis exploratorios sugieren a menudo que cada persona requiere diferentes funciones – el cambio puede parecer lineal para algunos, para otros curvilínea. Sin embargo, la simplificación que viene de adoptar una forma funcional común a todos en el conjunto de datos es tan convincente que sus ventajas superan totalmente a los inconvenientes. La adopción de una forma funcional común a todos los miembros de la muestra permite distinguir fácilmente las personas, utilizando el mismo conjunto de resúmenes numéricos derivados de sus trayectorias. En segundo lugar, el error de medición hace que sea difícil discernir si los patrones de peso en el registro empírico de crecimiento reflejan realmente el verdadero cambio o son simplemente debido a una fluctuación aleatoria. Estas complicaciones argumentan a favor del principio de parsimonia al seleccionar una forma funcional para el análisis exploratorio. Esto conduce a adoptar la trayectoria más simple que pueda hacer el trabajo” (Singer & Willet, 2003).↵
- Se puede especificar un factor o covariate; se denomina factors a los predictores categóricos, y covariates a las variables predictoras continuas.↵
- En estadística se dice que un modelo de regresión lineal presenta heterocedasticidad cuando la varianza de las perturbaciones no es constante a lo largo de las observaciones. Esto implica el incumplimiento de una de las hipótesis básicas sobre las que se asienta el modelo de regresión lineal. De ella se deriva que los datos con los que se trabaja son heterogéneos, ya que provienen de distribuciones de probabilidad con distinta varianza Existen diferentes razones o situaciones en las que cabe encontrarse con perturbaciones heteroscedásticas. La situación más frecuente es en el análisis de datos de corte transversal, ya que los individuos o empresas o unidades económicas no suelen tener un comportamiento homogéneo. Las principales consecuencias que derivan del incumplimiento de la hipótesis de homocedasticidad en los resultados de la estimación de mínimos cuadrados son: a) Error en el cálculo del estimador de la matriz de varianzas y covarianzas de los estimadores de mínimos cuadrados. b) Pérdida de eficiencia en el estimador mínimo cuadrático.
Por lo demás, los estimadores de mínimos cuadrados siguen siendo los mejores estimadores que pueden obtenerse. Siguen siendo insesgados, pero dejan de ser de varianza mínima. ↵ - Este formato, a diferencia del formato person level, permite analizar la covariación de los predictores con las variables dependientes, y es más útil que el formato nivel persona para este tipo de análisis ajustando modelos lineales mixtos.↵
- Se ordena la base de datos por la variable indicadora de sujetos (ID) y se grafican por separado los resultados de cada persona en función del tiempo. Debido a que es difícil discernir las similitudes y diferencias entre las personas si cada página contiene un solo gráfico, se recomienda agrupar grupos de gráficos en menor número de paneles. Es importante tener en cuenta que para la comparación e interpretación, usamos ejes idénticos en todos los paneles ya que si los ejes varían inadvertidamente, se puede llegar a conclusiones erróneas acerca de las similitudes y diferencias en el cambio individual. Los gráficos de crecimiento empíricos pueden revelar mucho acerca de cómo son los cambios de cada persona en el tiempo. Este cambio puede evaluarse tanto en términos absolutos (en contra de escala global de resultado), como en términos relativos (en comparación con otros miembros de la muestra).↵
- Esto se realiza en el software SPSS contando (comando COUNT) los casos missing que se registren.↵
- Desde un punto de vista conceptual estos tres puntos “reales” podrían resultar “puntos de inflexión” que cambian las trayectorias, o ser simplemente momentos de medición.↵
- Un posible procedimiento de ajuste de modelos lineales mixtos es MIXED del SPSS. Este procedimiento permite ajustar un tipo particular de modelos lineales, llamado jerárquicos, o multinivel. “Las estructuras jerárquicas se dan en casos como pacientes agrupados en hospitales, alumnos agrupados en colegios, individuos agrupados en familias, y otros” (Pardo, 2007). En este caso optamos por trabajar con el software STATA, que para este tipo de procedimientos tiene una mayor variedad de opciones.↵
- En STATA, se pueden utilizar distintos comandos para ajustar este tipo de modelo; “we can fit linear mixed models in Stata using xtmixed and gllamm. In the special case of a random-intercept model, we can also use xtreg”. ↵
- Esto se realizó mediante el comando Aggregate, de SPSS computando una variable que sea igual a 1 si el ingreso es 0, y agregando esta variable al nivel del individuo. Si la suma era mayor que 0, en este individuo había algún cero en el ingreso captado en algunas de las ondas, y por lo tanto fue eliminado del análisis.↵
- La diferencia con xtreg es que éste último solo se utiliza para ajustar una constante aleatoria (Dominici, 2009). El comando que utilizaremos es xtmixed ingredef, || id:, covariance(independent). Cuando agregamos “|| id:”, especificamos efectos aleatorios al nivel de los grupos identificados por la variable id, en este caso, el individuo. Dado que solo queremos una constante aleatoria, no hay que especificar otra opción. ↵
- “If the interclass correlation (IC) approaches 0 then the grouping by counties (or entities) are of no use (you may as well run a simple regression). If the IC approaches 1 then there is no variance to explain at the individual level, everybody is the same” (Dominici, 2009, 11).↵
- En los modelos multinivel se suele utilizar la terminología “Varying-intercept model with one level-1 predictor”. Para un ejemplo donde el nivel del modelo son distintas escuelas, y se compara los resultados de las pruebas de matemáticas en 5 y 3 grado, ver (Gutierrez, 2015) ↵
- Se podría ajustar un modelo que solo contenga variaciones en la pendiente (Varying-slope model, ajustamos la ecuación y = α + β j [i] x i + ε ↵
- Identity, es la única que tiene sentido cuando hay un solo efecto aleatorio. ↵
- La sintaxis de este modelo se convierte en mixed y x || id: x, covariance (unstructured), donde especificamos una covarianza no estructurada (unstructured) para los términos u del Segundo nivel. ↵
- Para centrar la variable año, se resta el valor del año, a un punto medio de la serie, en este caso 2002,5. ↵
- la variable año está centrada, es decir que se restó el valor de cada año (2000, 2002, 2005) a un punto medio de la serie (2002,5).↵
- “When estimating multi-level random effects models in Stata, the BLUP intercept predictions for each level are given as deviations from the overall intercept. So, suppose we have a three level model comprising total/national level, region and city. The overall mean is predicted to be A1. Suppose the predicted deviation for region 1 is R1 and the predicted deviation for city 1 (nested within region 1) is C1. The region specific intercept is simply A1 + R1: these predictions are simply the region specific deviations from the overall mean. In order to calculate the city specific intercept, we assume this is simply A1 + R1 + C1” (http://www.statalist.org/forums, consultado en Octubre 2015). ↵
- “LR output is a comparison of the fitted mixed model to standard regression with no group-level random effects. For example, for xtmelogit you are comparing with standard logistic regression. This LR test assesses whether all random-effects parameters of the mixed model are simultaneously zero” (Manual STATA).↵

