





6.1. Teoría de la evaluación
Las políticas de aseguramiento de la calidad educativa expresan la necesidad de evaluar un determinado sistema educativo o programa académico. En este sentido, toda evaluación en sí misma encierra una idea de control o comparación respecto a objetivos inicialmente planificados, y la conclusión a la que se arriba parte de una investigación sobre los sujetos e instituciones evaluados. En los siguientes apartados se analiza la naturaleza de la evaluación como así también de la acreditación como un tipo específico de evaluación.
Sobre el concepto de evaluación
Lafourcale define evaluación como “la determinación del grado de discrepancia entre una norma o pauta establecida y el producto parcial o terminal obtenido” (citado en Perez Lindo 1993: 77). En esta línea, House (2000) afirma que la evaluación es en esencia un instrumento de comparación, por lo que son necesarias un conjunto de normas y criterios con los cuales comparar el objeto evaluado. Haciendo referencia a Taylor, House continúa aseverando que esas normas de selección deben ser no solo seleccionadas, sino también definidas para poder llegar luego a una decisión sobre el grado de cumplimiento. No obstante, existe un principio dialéctico entre estas normas abstractas y el caso concreto a evaluar, no se trata de una simple deducción.
Por otro lado, el término “evaluación” se relaciona además con diversas vertientes de acuerdo a la función que se priorice. En todos los casos se parte de un concepto de evaluación que incluye la recolección de datos útiles para la toma de decisiones. Ahora bien, esta tarea puede estar dirigida a la rendición de cuentas o a la mejora del objeto evaluado. El primer objetivo tiene un carácter sumativo más orientado a la supervisión del sujeto a evaluar, ya sea la institución o el alumno. En este sentido, se enfatiza “la valoración de los logros o las carencias” del evaluado con el objetivo de proveer información sobre su situación (Tiana Ferrer, 1997: 11). Por otro lado, el carácter formativo está dirigido hacia el interior del evaluado, identificando debilidades y posibilidades de mejora con el objetivo de confeccionar planes de acción (Tiana Ferrer, 1997). A pesar de la diferencia en los enfoques, ambos usos están íntimamente ligados y se pueden dar en una misma práctica evaluativa en proporciones diversas.
Además, más allá del carácter sumativo o formativo, hay modelos básicos de evaluación que se pueden agrupar en enfoques. Estos mismos no implican un compromiso con uno de ellos, sino que según el fin de la evaluación y las cualidades del objeto a evaluar, se seleccionará uno u otro. Es decir, la selección de un enfoque no establece el descarte del resto de ellos. De acuerdo a House (2000), se pueden identificar ocho enfoques generales:
- Enfoque del análisis de los sistemas: Agrupa a las evaluaciones que analizan la correlación entre las puntuaciones de los tests con la normativa. Es decir, se estudian cuantitativamente (a través de estadísticas), los resultados en comparación con lo que estaba planificado. En este sentido, a través de este modelo el evaluador se pregunta si se han alcanzado los resultados previstos de la forma más eficiente. Los juicios a los cuales se llega a través de este tipo de evaluación no deberían variar de acuerdo al evaluador.
- Enfoque de objetivos conductuales: Este modelo de evaluación analiza el éxito del programa de acuerdo al alcance respecto a los objetivos preestablecidos para el programa. La norma entonces es equivalente a las metas, las cuales están formuladas en función de conductas del evaluado. Su principal preocupación se centra en la productividad, por lo que los objetivos deben estar formulados en términos mensurables.
- Enfoque de decisión: Este enfoque establece que la máxima autoridad de una institución debe estructurar la evaluación de acuerdo a las decisiones que haya que tomar. Según Stufflebeam, “la evaluación es el proceso de delimitar, obtener y proporcionar información útil para juzgar posibles decisiones alternativas” (citado en House, 2000: 30). Por lo tanto, es de vital importancia identificar quiénes son los responsables de la toma de decisiones y los usuarios a los cuales está dirigida, para luego seleccionar el tipo de información más útil de acuerdo a las decisiones necesarias. Este tipo de evaluaciones se dirigen a procesos de control de calidad.
- Enfoque que prescinde de los objetivos: Al contrario del segundo enfoque mencionado, en este modelo los evaluadores desechan los objetivos preestablecidos para evitar sesgos en el proceso de medición. Por lo tanto, el evaluador tiene una mirada más amplia, buscando todos los resultados posibles, incluso aquellos que pueden convertirse en negativos.
- Enfoque del estilo de la crítica del arte: La crítica de arte no se trata de una valoración negativa, sino de la apreciación objetiva de las cualidades de un objeto a evaluar. La función del experto es entonces la de reconocer y apreciar una obra sin necesidad de llegar a un juicio, y se entiende por “apreciación” conocer algo con mayor profundidad.
- Enfoque de revisión profesional (acreditación): Este enfoque consiste en un tipo de evaluación en la cual los profesionales participan de la misma juzgando el trabajo de colegas. Su función principal es dar fe de la calidad de instituciones o programas. Los propios evaluados también pueden participar de la evaluación, además de una comisión externa. A pesar que los procedimientos pueden ser distintos, las acreditaciones comparten el objetivo de finalizar con una valoración global de la institución o programa, por lo que el principal producto es la aceptación profesional.
- Enfoque cuasijudicial: Consiste en la simulación de un juicio para evaluar a una persona o programa. Se seleccionan testigos para que presenten pruebas y declaren ante un tribunal que tiene autoridad para tomar una decisión al respecto. Estas evaluaciones indagan entonces sobre los argumentos a favor y en contra del programa.
- Enfoque de estudio de casos (negociación): En esta evaluación se utilizan procedimientos como entrevistas y observaciones in situ. Es una evaluación en su mayor parte cualitativa en su metodología y presentación, y su principal objetivo se dirige a comprender una determinada situación, más que a explicarla. En comparación con el enfoque crítico, el estudio de casos se basa en las percepciones del evaluador y de los otros, en cambio el primero solo se funda en la experiencia del experto.
Al mismo tiempo hay que considerar que la evaluación tiene un carácter político, dado que “supone la existencia de acuerdos comunes: juicios previos consensuados, sobre lo que es bueno o conveniente para todos como propósito de las acciones educativas” (de la Garza Vizcaya, 2004: 808). Por lo dicho, se convierte en un elemento construido subjetivamente y, por consiguiente, pasible de disenso al momento de decidir su objetivo y modo de uso. En este sentido, la evaluación tiene carácter político porque se trata de una actividad humana social, pero también tiene carácter ideológico porque no se trata simplemente de un “proceso técnico, neutral e inocuo”, sino que en su cualidad instrumental, “obedece a una lógica de control” (de la Garza Vizcaya, 2004: 808).
La evaluación de la calidad que aplica la CONEAU ha sido resultado de la interacción de factores políticos, sociales y económicos, dentro de un contexto determinado que lleva a los diferentes grupos de interés a revisar la relación entre Estado, instituciones de educación superior y la sociedad civil. Se encontró entonces en los procesos de evaluación institucional y acreditación de carreras la manera de regular a las instituciones de educación superior para asegurar que fueran a dirigir sus esfuerzos a la mejora de la calidad en la formación que ellas proporcionan. Por lo tanto, la evaluación que realiza la CONEAU tiene un carácter indudablemente político, pero sostenido con métodos técnicos objetivamente definidos, propios de las evaluaciones de programas.
La evaluación de programas
Dado que existen diversos tipos de evaluación, cada una tiene sus especificidades y procedimientos propios. La evaluación de programas es una categoría concreta que se refiere al análisis del “conjunto especificado de acciones humanas y recursos materiales diseñados e implantados organizativamente en una determinada realidad social, con el propósito de resolver algún problema que atañe a un conjunto de personas” (Fernández Ballesteros, 1995, citado en González Ramírez, 2000: 89). Por lo tanto, dada la complejidad del universo que abarca un programa (ya sea en cuanto a su extensión temporal, geográfica o institucional, actividades que incluye, o tópicos sobre los que versa), la evaluación puede incluir personas, instituciones y materiales. Es importante entonces que la evaluación capte la esencia del programa al desarrollar sus múltiples dimensiones: su significado y propósitos, su estructura y procedimientos, los individuos involucrados y funciones que cumplen, recursos de los que dispone, entre otros.
Por otro lado, este tipo de evaluación debe ser lo suficientemente flexible, dado que es la evaluación la que se debe adaptar a las cualidades de un programa en un determinado contexto, y no al revés. Además, toda evaluación de programas deberá considerar que la realidad en la que se desenvuelve es dinámica, por lo que se vuelve necesario una revisión periódica de lo planificado y de las estrategias adoptadas para evaluar (Gobantes Ollero, 2000, citado en González Ramírez, 2000). Asimismo, una evaluación de programa debería contar con una serie de aspectos relacionados al contexto para que se pueda consolidar con éxito: contar con la voluntad del personal involucrado en la aplicación del programa; respetar la autonomía y democracia del mismo; cuidar que la evaluación tenga en cuenta la disposición y los tiempos del personal asignado, el cual tiene a cargo múltiples tareas; y tomar en consideración las evaluaciones preexistentes (Gobantes Ollero, 2000, citado en González Ramírez, 2000).
La acreditación
Según The International Encyclopedia of Higher Education, “la acreditación es el proceso mediante el cual una agencia o asociación legalmente responsable otorga reconocimiento público a una escuela, instituto, colegio, universidad o programa especializado que alcanza ciertos estándares educativos y calificaciones previamente establecidas” (Marquina, 2012: 62). Además, es un proceso de evaluación continuo que se repite cada determinada cantidad de años con el objetivo de que exista un perfeccionamiento constante y que la sociedad en general vaya otorgando mayor confianza y validez a esta certificación.
Marquina describe los objetivos que impulsan a los Estados a desarrollar sistemas de acreditación y a las universidades a someterse a este tipo específico de evaluación. En primer lugar, afirma que la acreditación ofrece mayor certeza al ser una evaluación externa. Asimismo, se brinda seguridad de que la institución o programa ha alcanzado las expectativas generales en los campos científicos y profesionales, y facilita también la identificación de aquellas instituciones que voluntariamente se comprometen a mejorar la calidad. Además, la acreditación permite verificar si las universidades están incorporando nuevos conocimientos y prácticas profesionales necesarios para el desarrollo personal y del país o región.
En el caso de CONEAU, Pugliese (2001) explica que la acreditación es más un control a partir de normas preestablecidas, por lo que es un tipo de evaluación diferente al de la evaluación institucional que realiza la misma institución. En la evaluación institucional, el concepto de calidad se define a partir de las características propias de las universidades, “por lo que está expresando la existencia de diferentes conceptos de calidad en el mismo ámbito de la educación superior” (Vizcarra, 2011: 292). En cambio, en las acreditaciones, un organismo define estándares mínimos que se deben alcanzar. Tanto la acreditación de carreras como la evaluación institucional tienen como objetivo el mejoramiento de la calidad. Pero en el primer caso se trata de un procedimiento más estricto en el cual se verifica la adecuación a ciertas pautas generales. Por lo tanto, la claridad en los estándares mínimos es un elemento fundamental para demostrar la transparencia del proceso de acreditación, asegurando a la comunidad académica y al público en general que los parámetros no fueron decisión de actores externos a la universidad, sino fruto de discusiones y deliberaciones en el marco de un ámbito en el cual todos los sujetos involucrados están representados (Pugliese, 2001). Marquis y Sigal (1993) afirman que es imposible diseñar evaluaciones de programas si no se considera la participación de los actores involucrados en el proceso. La acreditación no escapa a la naturaleza política de toda evaluación. Es decir, se trata de una construcción subjetiva pero basada en estándares preestablecidos. En este caso concreto, los criterios para la acreditación de los posgrados que realiza la CONEAU fueron producto del dictamen del Consejo de Universidades. El artículo 46° de la Ley de Educación Superior establece que las acreditaciones se llevarán a cabo “conforme a los estándares que establezca el Ministerio de Cultura y Educación en consulta con el Consejo de Universidades”. La CONEAU no crea entonces los estándares, sino que los implementa y verifica a través de determinados instrumentos de medición.
6.2. Teoría de la medición
Stevens define la medición en términos amplios como la asignación de “numerales a objetos o acontecimientos de acuerdo con ciertas reglas” (1951, en Wainerman, 1976: 17). En este sentido, toda evaluación es una medición que estudia las dimensiones de ciertos fenómenos según escalas predefinidas. Para ello todo acto de medición debe considerar no solo la construcción de los instrumentos utilizados, sino también su aplicación. Por lo tanto, los instrumentos creados para recolectar información deben analizarse en su calidad de dispositivos de medición, y también en la forma en la que se lleva a cabo dicha medición. Es decir, una vez que se identificó el qué se quiere medir, se deben además tomar las decisiones sobre el cómo: los procedimientos o técnicas de recolección de información y las normas para la utilización del instrumento. No obstante, en toda medición existen variaciones en la puntuación en los instrumentos dado que la medida “siempre tiene lugar en una situación más o menos compleja en la que innumerables factores pueden afectar a las características objetivo de medición y al proceso de medida” (Selltiz, 1965: 174). Por lo tanto, los análisis de validez y confiabilidad de los procesos de medición pretenden identificar qué factores pueden estar influenciando los datos considerados para explicar una determinada realidad social. En los siguientes apartados se estudiará el proceso de medición y se profundizará en los conceptos de validez y confiabilidad que guiarán el análisis de los instrumentos de evaluación utilizados por la CONEAU.
Los elementos de todo proceso de medición
Todo proceso de medición incluye una serie de elementos centrales que se dan en una sucesión gradual, cuyo orden es importante respetar para asegurar la validez y confiabilidad de la medición integral (Ravela, 2006b): 1) elección de la porción de la realidad que se medirá y la construcción conceptual de la variable a medir; 2) definición de objetivos de la medición; 3) construcción de instrumentos de medición y producción de evidencia empírica, es decir, la construcción de los datos a partir de la información recolectada; 4) generación de juicios de valor sobre la realidad observada; y 5) toma de decisiones de acuerdo a los objetivos propuestos.
De acuerdo a este esquema, el primer paso en todo proceso de evaluación es construir el referente, el cual debe ser consistente con los objetivos de los evaluadores. La naturaleza del proceso de medición consiste entonces en la acción de contrastar la evidencia empírica con el referente. En este sentido, Ravela (2006b) explica que uno de los errores más comunes de toda evaluación es suponer que el referente está inequívocamente predefinido y, por ende, la evaluación se limita a construir instrumentos para recoger evidencia empírica. Esta realidad es una construcción subjetiva que contiene una connotación valorativa, ya que se posiciona como el ideal a alcanzar. La comprensión del referente es el primer elemento que facilitará la construcción de instrumentos, el entrenamiento de evaluados y evaluadores, y proveerá mayor objetividad a todo el proceso de medición.
El tercer elemento solo se puede desarrollar una vez que se hayan definido clara y consistentemente el referente y los propósitos. De otra forma, no tiene sentido construir instrumentos de medición si no se sabe qué y para qué se medirá. Una vez definidas estas cuestiones, el problema central del tercer elemento se encuentra en reconocer que el acceso a la realidad que se quiere estudiar es mediado, no existe un contacto directo. La evidencia empírica hace referencia a las aproximaciones parciales a la realidad que nos proveen información sobre algún aspecto que nos interesa conocer a través de la aplicación de instrumentos de medición. Ravela define a los instrumentos de una evaluación como “todos aquellos dispositivos construidos para recoger evidencia empírica en forma sistemática sobre los aspectos relevantes de la realidad a evaluar” (2006b: 5). Es decir, los instrumentos son las herramientas con la que cuentan los evaluadores para conocer una realidad, son generadores de datos.
El proceso de medición
En toda medición se da una progresión de etapas que crea un orden conceptual y que va desde la definición nominal y real de aquello que se medirá, para luego definir la variable operacionalmente y aplicarla efectivamente en el mundo real. La definición nominal se refiere a aquella que se asigna a un término, por lo que centra la observación, pero aún no nos explica cómo observar. Una definición nominal de calidad que estableciera CONEAU proporcionaría un determinado enfoque a este concepto multívoco, pero aún no dice a los evaluadores o evaluados cómo se lo habrá de observar. Estas guías las proporciona la definición operacional, que es una definición que detalla con precisión cómo se observará un concepto.
En la misma línea, Padua describe etapas progresivas para la medición, comenzando por la imagen inicial que los evaluadores establecen de una variable, que es un atributo o propiedad de una unidad de análisis, susceptible de asumir diversos valores. Korn define variable a “un aspecto discernible de un objeto de estudio” (1973: 9). Y se denomina “dato” al valor que toma la unidad de análisis en la variable. La imagen inicial es una idea más o menos vaga del concepto original, la cual luego se descompone en dimensiones. Cada una de estas dimensiones se describe a partir de indicadores. En la interpretación final de la evaluación es necesario recomponer el concepto original a través de la información recabada en los indicadores: se vuelven a unir las partes para analizar una situación en comparación con la imagen inicial que se tenía. Entre la construcción de la imagen inicial de la variable (primera etapa) y la reconstrucción de la imagen final para ser comparada (última etapa) se da un ida y vuelta con la realidad.
Korn (1973) resume este proceso en tres pasos de definición de la variable: primero es necesario una definición nominal de la variable; en segundo lugar se requiere una definición real que incluye la enumeración de dimensiones y por último una definición operacional en la que se seleccionan los indicadores que medirán la variable en la realidad. La variable entonces debe estar definida conceptualmente tanto de forma nominal como real, y relacionarse con el cuerpo teórico en el que está contenida. La figura 3 representa un esquema del orden conceptual de una variable.
Figura 3. Descomposición de una variable
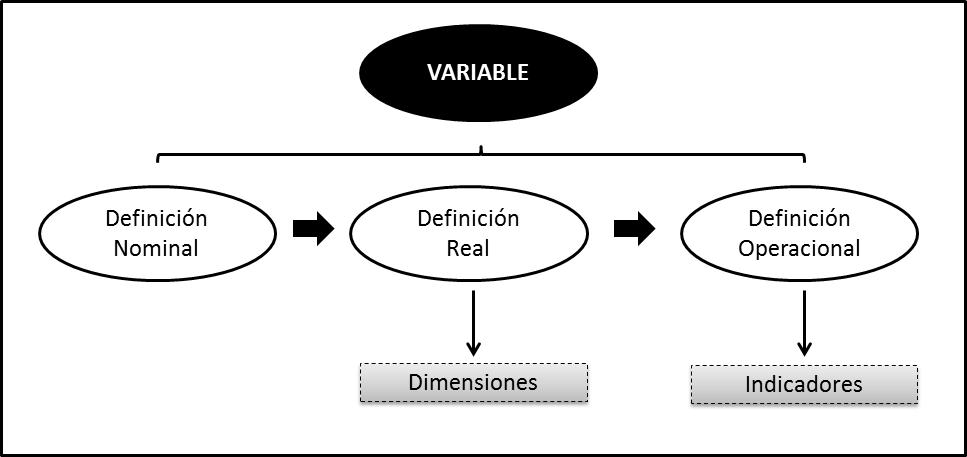
Fuente: Elaboración propia a partir de Korn (1973).
Mayntz, Holm y Hubner (1996) asumen que todo saber sobre la sociedad se basa en datos sobre diferentes dimensiones de análisis que se atribuye a una determinada situación social. Una dimensión es el nombre técnico que se le atribuye a un aspecto discernible de una variable (Korn, 1973). Ahora bien, los datos se obtienen a partir de observaciones y del análisis del comportamiento humano, y todos aquellos aspectos que son parte de un fenómeno social, de manera “conceptualmente estructurada, guiadas por premisas teóricas, sistemáticas y controladas” (Mayntz et al., 1996: 45). Pero estas observaciones solo se convierten en datos cuando el registro se identifica con las dimensiones atributivas del objeto de estudio y es relevante para la respuesta al problema de investigación (Mayntz et al., 1996). Por lo tanto, hay que conocer el objeto de estudio y su contexto, como así también identificar cuál es el problema de investigación, para asegurarnos que aquello que se está observando podrá ser considerado un dato.
En síntesis, a través de instrumentos de medición se recolectan datos de acuerdo a determinadas reglas que permiten contrastar un escenario específico con la imagen inicial de la variable. En el caso de la acreditación que realiza la CONEAU, la variable es calidad y los valores son acredita o no acredita.
La definición de estándares
Toda evaluación en esencia es una medición y una comparación. Y todo análisis que deriva de la recolección de datos requiere de estándares o puntos de referencia que puedan indicar si hubo una mejora o deterioro de una determinada situación. Cassasus define a un estándar como un constructo teórico elaborado por una autoridad que cuente con el conocimiento y apoyo necesario para ello. Es decir, se trata de información sistematizada y disponible para promover acciones en un ámbito determinado: “La vinculación con la acción significa que los estándares se construyen para generar acciones que conduzcan a la implementación de tareas para alcanzarlos” (Cassasus, 1997: 2). Sin embargo, es una condición sine qua non que los usuarios o evaluados tengan confianza en el estándar, porque solo así mejorará la eficacia del accionar. Esta confianza se alcanza solo en los casos en los cuales los estándares son públicamente conocidos, accesibles a todos los interesados en la evaluación, delimitan responsabilidades concretas y pasan por procedimientos periódicos de rendición de cuentas (Cassasus, 1997).
Por último, es necesario considerar en toda evaluación que los estándares no son construcciones únicas y válidas, dado que en última instancia son elaborados por actores sociales con sus propios marcos de referencia. Por lo tanto, para una misma situación se pueden definir estándares diferentes (Cassasus, 1997). De aquí la necesidad de que el conjunto de ellos cuente con el consenso de la comunidad interesada. Por otro lado, también se requiere evaluar con prudencia el peso relativo de cada estándar dentro del conjunto. Tanto evaluados como evaluadores deben acordar precedencias entre los estándares para las situaciones concretas (de la Garza Vizcaya, 2004).
La validez y confiabilidad de la medición
Toda política pública de evaluación necesita un sistema de indicadores que puedan mostrar si un determinado fenómeno evaluado cumple con los requisitos de calidad esperados. Si en este proceso de recolección de datos y comparación se encuentran fallas, estas viciarán la toma de decisiones derivada del análisis de la información. Estos errores se pueden explicar por falta de validez y confiabilidad en los instrumentos de medición o en la manera de aplicarlos.
Según Wainerman (1976) la validez nos brinda información acerca de si se está midiendo aquello que se desea. Coincide con Mayntz et al., para quienes la pregunta por la validez de un instrumento “se refiere a si mide de hecho lo que el investigador quiere medir con su ayuda” (1969: 86). Un instrumento de medición es válido cuando evalúa lo que se pretende evaluar con él. Es decir, cuando los indicadores describen el concepto teórico que se está midiendo. Por lo tanto, la validez depende de los propósitos del sujeto que evalúa, quien previamente define una definición conceptual. Los instrumentos de medición no son válidos de manera absoluta porque se trata de una relación entre los objetivos del evaluador y la forma de aplicación en la construcción del instrumento.
La validez de conceptos se refiere al análisis de un conjunto de instrumentos de medición que reflejan un concepto particular, pero que puede ser definido de diferentes maneras (Cronbach y Meehl, 1966, en Wainerman, 1976). En el caso del estudio de esta investigación, el concepto particular es la calidad de un programa de posgrado, el cual se evalúa de acuerdo a determinados estándares. Ahora bien, desde el punto de vista científico, “dilucidar lo que algo es significa establecer las leyes dentro de las cuales aquello ocurre” (Cronbach y Meehl, 1966, en Wainerman, 1976: 175). Los autores designan una red nomológica a este sistema de leyes interconectadas. En este sentido, las distintas dimensiones que evalúa la CONEAU en la acreditación de posgrados como así también la definición de estándares para dichas dimensiones constituyen la red nomológica del concepto de calidad académica. El perfeccionamiento de la red nomológica permite entonces conocer con mayor profundidad el concepto teórico. Sin embargo, hay que tener en cuenta que “a menos que las diversas personas que usan el concepto acepten prácticamente la misma red nomológica, es imposible su comparación amplia, pública” (Cronbach y Meehl, 1966, en Wainerman, 1976: 178). La validez de concepto es en última instancia la adecuación entre la evidencia empírica y el referente definido para la evaluación, y es el uso convencional que se le da a este término.
Ravela (2006c) identifica amenazas a la medición en tres tipos de validez. En el caso de la “validez del constructo”, se refiere a la situación en la que la prueba no evalúa lo que se supone que debería evaluar. Se da entonces un problema de consistencia entre el instrumento empleado y el referente de la evaluación. La “validez de contenido” se refiere a la situación en la que la prueba no cubre de forma adecuada la amplitud del referente. Pick de Weiss (1994) agrega respecto a este tipo de validez que en ciencias sociales, particularmente, siempre medimos efectos latentes, por lo que para determinar la validez de contenido es necesario primero plantear exactamente los hechos manifiestos que queremos medir y luego todas las formas bajo las cuales se puede presentar en una realidad. Por último, la “validez predictiva” se refiere a la situación en la que el dispositivo de evaluación no es adecuado para predecir futuras acciones resultantes de la evaluación. Por ejemplo, los instrumentos de medición arrojan datos que acreditarían un programa, pero, sin embargo, en un futuro ese programa demuestra no tener la calidad requerida.
Por otro lado, Wainerman (1976) en la obra Escalas de medición en Ciencias Sociales dice que la “confiabilidad” es una condición necesaria pero no suficiente de una medición. Su análisis proporciona a los interesados información sobre la precisión de la medición. Thorndike (1951, en Wainerman 1976) denomina “no confiabilidad” al hecho o posibilidad que mediciones repetidas de un mismo factor, en un mismo objeto de estudio, no dupliquen los resultados. Es decir, la confiabilidad del instrumento se refiere a la exactitud de la medición, a la estabilidad y a la sensibilidad para la identificación de diferentes magnitudes. Por lo que una medida es confiable si algo se está midiendo con precisión o en forma consistente (Kerlinger, 2002). Y para decidir si un instrumento de medición es confiable es necesario que se pregunte qué debe detectar el instrumento, y si existen otros motivos que estén influyendo en la medición (Selltiz, 1965).
La estabilidad y la equivalencia son conceptos incluidos en el de confiabilidad. El primero se determina según el grado de consistencia entre las medidas luego de repetidas aplicaciones, aislando los cambios de factores externos que pueden influir de manera colateral (Selltiz, 1965). Por otro lado, la equivalencia alude a la medida en que diferentes investigadores que aplican los mismos instrumentos sobre los mismos sujetos llegan a resultados consistentes (Selltiz, 1965). Los grados de estabilidad y equivalencia aumentan según el grado de uniformidad de las unidades de la población a medir. Wainerman (1976) agrega que el origen de los factores que atentan contra la confiabilidad se puede encontrar en los sujetos evaluados, en el instrumento de evaluación o en la aplicación del mismo. Por otro lado, Thorndike (1951, en Wainerman 1976) también identifica al azar como un factor influyente e ineludible.
En resumen, una política pública de evaluación de la calidad requiere que se indague la presencia de amenazas a la validez y confiabilidad, con el propósito de proporcionar información útil y confiable para la toma de decisiones sobre la calidad de las carreras universitarias. Ahora bien, ¿qué se entiende por calidad?

