





Estudio 3. La comprensión simbólica de imágenes de una tablet que representan acciones
El objetivo de este estudio consistió en indagar si los niños de 24, 30 y 36 meses de edad comprenden que las secuencias de imágenes digitales provistas por una tablet representan acciones dirigidas hacia un fin que pueden ocurrir en la realidad. La comprensión de acciones ha sido estudiada utilizando imágenes de video (e.g., Baldwin, et al., 2001; Balwin, Andersson, Saffran y Meyer, 2008; Falck-Ytter, et al., 2006; Flanagan y Johansson, 2003; Saylor, et al., 2007) o acciones “en vivo” (e.g., Woodward, 1998, 2003; 2009; Meltzoff, 1995), pero no vincularon la comprensión de acciones en sí mismas con la comprensión referencial de las imágenes que las representan.
En este estudio participaron 45 niños de nivel socioeconómico medio, 15 de 24 meses (M = 25,67; DT = 1,49), 9 niños y 6 niñas; 15 de 30 meses (M = 29,40; DT = 0,73), 7 niños y 8 niñas; y 15 de 36 meses de edad (M = 36,20; DT = 1,20), 6 niños y 9 niñas. Los niños acudían a instituciones maternales públicas y privadas de la ciudad de Santa Elena (provincia de Entre Ríos).
Materiales. Se utilizó una tablet 10.1”, en la que se presentaban secuencias de imágenes que representaban acciones dirigidas hacia un fin, simples y cotidianas, realizadas por una figura humana. También se utilizaron nueve objetos reales (que aparecían en las imágenes): papeles, manzanas de juguete y ositos de peluche. La figura humana mostraba el torso y/o los brazos y las manos, pero no el rostro, con el objetivo de neutralizar pistas ostensivas y que la atención se focalizase en la acción ejecutada sobre los objetos.
Un total de seis acciones fueron presentadas a los niños. Tres correspondían a la fase de orientación (abrir una azucarera, verter jugo en un vaso e introducir una naranja en un bol); y tres a la fase de prueba (romper un papel, cortar una manzana y ensuciar un oso con pintura) (ver figura 4).
Procedimiento. Se diseñó una tarea en la cual el niño observaba diferentes secuencias de acciones (desempeñadas por una figura humana) en imágenes provistas por la tablet. Cada secuencia estaba compuesta de cuatro imágenes que formaban una acción desempeñada sobre diferentes objetos (papel, manzana, oso). Las imágenes eran mostradas una a una por la experimentadora mediante el deslizamiento del índice en la pantalla. Una vez que los niños observaban cada secuencia, se les pedía elegir el resultado de la acción escogiendo una de tres opciones posibles: 1. objeto con la modificación correcta, 2. objeto sin modificación alguna, 3. objeto con otra modificación. Para comenzar la fase de prueba, el experimentador invitaba al niño a sentarse en una mesa donde estuviera cómodo y pudiera observar las imágenes provistas por la tablet. Sobre la mesa se encontraban las elecciones ocultas por unas telas opacas. Las observaciones eran individuales.
El procedimiento constaba de dos fases.
- Orientación. En este estudio y en el siguiente, se introducía al niño en la tarea diciendo: “Te voy a mostrar unas fotos”. Luego, la experimentadora le presentaba tres secuencias de acciones. Mientras pasaba las imágenes, preguntaba: “¿Qué está haciendo?”. Al finalizar la presentación, se le decía el resultado la acción (e. g., secuencia 1: “¿Qué está haciendo? ¡Viste como abrió!”). El propósito de esta fase era asegurarse de que el niño prestase atención a la acción representada.
- Prueba. Esta fase constaba de tres subpruebas (tres secuencias). Se mostraban las secuencias en forma sucesiva y, en cada una de ellas, se preguntaba nuevamente: “¿Qué está haciendo?”, sin verbalizar el resultado de la acción. Inmediatamente después de mostrar cada secuencia, se invitaba al niño a elegir el objeto con el resultado de la acción diciendo: “¿Me mostrás cómo quedó?”.
El orden de presentación de las secuencias y elecciones fue contrabalanceado entre las diferentes subpruebas.
Figura 4. Secuencias de imágenes de la orientación y la prueba con sus respectivas elecciones de objetos.

Fuente: Elaboración propia.
Estrategia de análisis
La variable dependiente sobre la que se efectuaron los análisis fue el número de subpruebas correctas. Se tuvo en cuenta la primera elección, pudiendo cada niño tener una puntuación total de tres subpruebas correctas en la tarea.
Los análisis se realizaron sobre los puntajes, también se informan porcentajes para una mayor claridad en la exposición de los resultados. Se analizaron tanto las elecciones de los niños (Correcta: RC o Incorrecta: RI) como el tipo de secuencia presentada.
También se realizaron análisis de la ejecución individual de los niños en base al criterio de sujeto exitoso. Consideramos al niño como exitoso si había respondido correctamente las tres subpruebas de la tarea. Debido al tamaño de la muestra y a que no se asume normalidad, optamos por un análisis no-paramétrico, aplicando las pruebas U Mann-Whitney para muestras independientes y prueba Chi2 bondad de ajuste.
Resultados y discusión
Sobre un total de 45 respuestas correctas posibles por grupo, los niños de 24 meses mostraron un total de 17 respuestas correctas (38%); los de 30 meses, 32 (71%) y los de 36 meses, 39 (87%) (ver gráfico 3). La comparación entre grupos arrojó diferencias estadísticamente significativas (X2 = 17,55, p < .0001).
Gráfico 3. Porcentaje de respuestas correctas de los niños por grupos de edad.
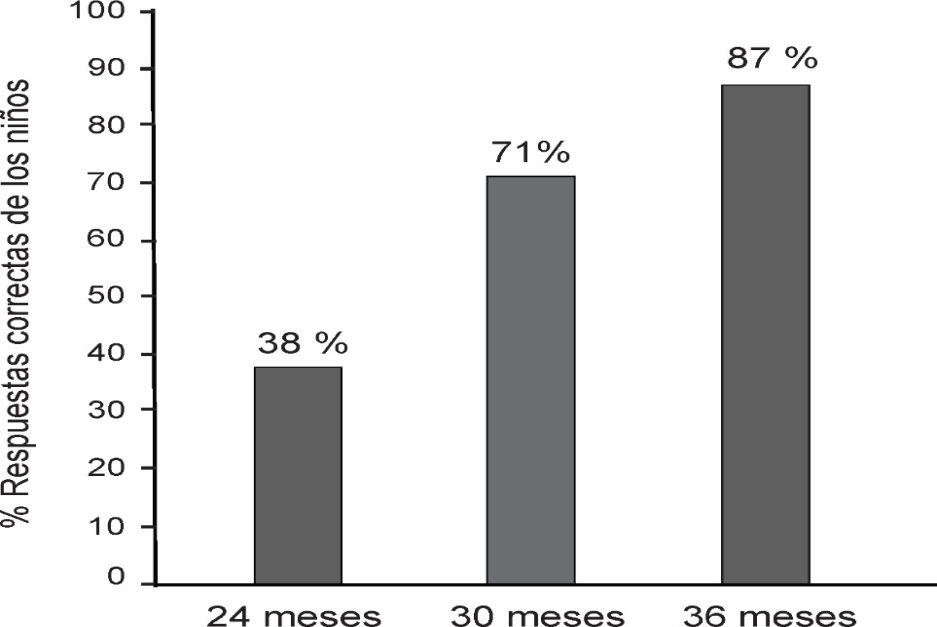
Fuente: elaboración propia.
En las comparaciones por pares, se encontraron diferencias significativas entre los niños de 24 y 36 meses (U = 21,00; p < .0001), entre los de 24 y 30 meses (U = 38,50, p < .001), pero no entre los niños de 30 y 36 meses de edad (ns).
Por otro lado, se buscó determinar si existían diferencias en el número de respuestas correctas e incorrectas de los niños según su edad. Al realizar este análisis, se encontraron diferencias significativas en el grupo de 30 meses (RC = 32, RI = 13), (X2 = 9,26; p < .01) y 36 meses de edad (RC = 39, RI = 6), (X2 = 10,80; p < .005); con más respuestas correctas que incorrectas en ambos grupos. En cuanto a los niños de 24 meses, si bien mostraron más respuestas incorrectas que correctas, la diferencia no alcanzó significación (RC = 17; RI = 28, ns).
En cuanto a las pruebas de azar, los datos mostraron que las respuestas de los niños de 24 meses no superaron la prueba de azar en ninguna de las tres secuencias de acciones: secuencia 1 (X2 = 0.00; gl = 1; p > .05), secuencia 2 (X2 = 0.30; gl = 1; p > .05) y secuencia 3 (X2 = 2,70; gl = 1; p > .05). La ejecución de los niños de 30 meses superó el nivel de azar en las tres acciones: secuencia 1-romper (X2 = 7,50; gl = 1; p < .005), secuencia 2-cortar (X2 = 4,80; gl = 1; p < .05) y la secuencia 3-ensuciar (X2 = 7,50; gl = 1; p < .005). De igual forma, los niños de 36 meses superaron las pruebas contra el azar en las tres secuencias presentadas, secuencia 1-romper (X2 = 14,70; gl = 1; p < .0001), secuencia 2-cortar (X2 = 19,20; gl = 1; p < .0001) y la secuencia 3-ensuciar (X2 = 24,30; gl = 1; p < .0001). Estos resultados muestran que, a partir de los 30 meses, los niños comprenden que las imágenes provistas por una tablet representan acciones que pueden ocurrir en la realidad.
Debido a que se presentaron acciones de diferente naturaleza (romper, cortar y ensuciar), analizamos si alguna de estas era más fácil de comprender según la edad de los niños. Aunque la acción de ensuciar tuvo un mayor número de respuestas correctas en todas las edades, no se encontraron diferencias estadísticamente significativas al comparar esta acción con las otras dos (romper y cortar).
Si bien los resultados no son directamente comparables, resulta interesante destacar que en el estudio de Harris, Kavanaugh y Dowson (1997) la acción presentada siempre fue la misma: ensuciar. Por ejemplo, el experimentador hacía como si o, efectivamente, realizaba acciones literales de ensuciar un juguete. En la presente investigación, se representaron acciones de diferente naturaleza (romper, cortar y ensuciar), lo que quizás llevó a que la tarea propuesta tuviera una mayor demanda cognitiva para los niños más pequeños. Al no repetir la acción, se descartó un efecto de aprendizaje y/o familiaridad con una acción específica a lo largo de la prueba.
Por otro lado, debido a que los niños podían seleccionar entre dos opciones incorrectas (objeto sin modificación, y objeto con otra modificación), analizamos si había alguna tendencia de los niños a seleccionar una opción por sobre otra. No se encontraron diferencias significativas entre el tipo de elección errónea por tipo de acción en los tres grupos de edad.
También analizamos el desempeño individual de los niños. A los 24 meses, 4 niños realizaron dos subpruebas correctamente; 9 niños, una, y 2 niños, ninguna. A los 30 meses, 5 niños respondieron correctamente todas las subpruebas; 8 niños, dos; 1 niño, una; y un solo niño, ninguna. A los 36 meses, once niños obtuvieron la puntuación máxima; 2 niños resolvieron dos y 2, una sola (ver tabla 1).
Tabla 1. Desempeño correcto individual de los niños por edad.

Fuente: elaboración propia.
En su conjunto, los resultados mostraron que los niños de 30 y 36 meses, a diferencia de los de 24 meses de edad, comprendieron que las secuencias de imágenes se referían a una acción que puede tener lugar en la realidad, ya que escogieron el objeto real que mostraba el resultado de la acción representada.
Si bien se ha sugerido que las acciones poseen múltiples niveles de abstracción, lo que hace que algunas sean más sencillas que otras (Hamlin, Hallinan y Woodward, 2008), este no pareció ser el caso en las acciones presentadas en este estudio, ya que ninguna fue más sencilla o complicada de comprender que la otra. Los niños, desde muy temprano, tienen una amplia experiencia con acciones como las que presentamos en este estudio. Ellos observan y experimentan que los objetos se rompen, cortan y ensucian cuando son manipulados por otros o por ellos mismos. Como se ha demostrado, los niños pequeños comprenden acciones, incluso acciones incompletas (Carpenter, Akhtar y Tomasello, 1998; Csibra y Gergely, 2009; Hamlin, et al., 2008), y diferencian acciones intencionales de accidentales desarrollando una cierta comprensión de la “intención en la acción” desde muy pequeños (Behne, Carpenter, Call y Tomasello, 2005).
Los niños de 24 meses de este estudio, probablemente, comprendieron las acciones en sí mismas en las secuencias de imágenes presentadas, pero no ligaron dichas imágenes a la realidad, por lo que no pudieron escoger el objeto que mostraba la modificación asociada al resultado de la acción representada. De hecho, varios de estos niños verbalizaban la acción al observar las secuencias, pero fallaban a la hora de elegir el objeto; por ejemplo, decían: “está cortando” (manzana), “está abriendo una carta” (papel).
Ahora bien, si ciertamente los niños del presente estudio no recibieron información explícita en cuanto a la función de referencia de las imágenes, cuando se presentaban las secuencias el experimentador preguntaba: “¿Qué está haciendo?”. Probablemente, el uso del verbo ayudó a los niños en esta tarea, ya que un verbo marca una acción. Investigaciones previas han mostrado que las etiquetas ayudan a la detección de similitudes y relaciones entre acciones familiares y novedosas (e.g., Ferry, Hespos y Waxman, 2010; Fulkerson y Waxman, 2007; Gerson y Woodward, 2013; Mackenzie, Graham y Curtin, 2011; Namy y Gentner, 2002; Ratterman y Gentner, 1998).
Por otra parte, está ampliamente demostrado que tanto niños como adultos comprenden una acción con más rapidez si la misma se presenta en una secuencia completa (Balwin, et al., 2008). Por ejemplo, cuando se presentan acciones en videos desarrolladas de manera continua y en secuencias, los bebés de 11 meses logran extraer información de las acciones (Baldwin, et al., 2001). Lo que, en última instancia, demuestra que los bebés son sensibles a los límites de intención de las acciones dinámicas humanas (Saylor, et al., 2007).
En virtud de estas dos variables: pista verbal y presentación de la secuencia, indagamos si los niños continuarían comprendiendo la acción si se les retiraba la información visual sobre la secuencia o la información verbal, y estudiamos cuál sería el peso de cada una de estas dos pistas sobre la comprensión de la acciones en imágenes provistas por una tablet.
Estudio 4. Pista verbal y secuencia visual en la comprensión de imágenes que representan acciones
El objetivo de este estudio consistió en indagar qué tipo de pista (verbal o secuencia) resulta clave en la comprensión simbólica de imágenes que representan acciones dirigidas hacia un fin por parte de niños de 30 y 36 meses de edad.
En el estudio anterior, se encontró que los niños de 30 y 36 meses comprendieron que las imágenes representan acciones que pueden ocurrir en la realidad. A los niños se les proveía de una pista verbal, de un verbo que marcaba una acción, al decirles: “¿Qué está haciendo?”, como así también de una pista visual, al presentarles imágenes que mostraban acciones en secuencias.
En cuanto a la pista verbal, se ha demostrado que cuando los niños escuchan a un adulto nombrar un objeto, tienden a mirar hacia su referente, y cuando escuchan una palabra nueva, tienden a buscar el concepto al que refiere (Waxman y Goswami 2012; Waxman y Lidz, 2006). De la misma forma, los niños pequeños esperan que las palabras nuevas se refieran también a acciones y eventos (Vouloumanos y Waxman, 2014).
En cuanto a la pista visual (secuencia), se ha demostrado que los niños comprenden una acción con más facilidad, en imágenes de video, si se les presenta la secuencia completa de la acción (Baldwin, et al., 2001; Balwin, et al., 2008; Saylor, et al., 2007).
Metodología
Diseño. Tres condiciones: 1. Con secuencia (CS) y con pista verbal (CV); 2. sin secuencia (SS) y con pista verbal (CV); y 3. con secuencia (CS) y sin pista verbal (SV). Las tres condiciones se testearon en dos edades: 30 y 36 meses (ver tabla 2).
Tabla 2. Distribución de los niños según edad y condición experimental.

Fuente: elaboración propia.
En este estudio participaron 78 niños, 42 de 36 meses de edad y 36 de 30 meses de edad. Al igual que en los estudios precedentes, se contó con el consentimiento informado de los padres y la institución. El nivel sociocultural de los participantes puede considerarse medio. Los niños fueron distribuidos en seis grupos según condición experimental (3) y edad (2).
Materiales. Los materiales utilizados fueron los descritos en el estudio anterior excepto que, para la condición sin secuencia (SS), solo se presentaba la imagen final (ver figura 4).
Procedimiento. Como en el estudio previo, luego de que los niños observaran las imágenes, debían elegir el resultado de la acción escogiendo una de tres opciones posibles: 1. objeto con la modificación correcta, 2. objeto sin modificación alguna, 3. objeto con otra modificación. El procedimiento para las tres condiciones constaba de dos fases: orientación y prueba.
Con secuencia y con pista verbal (CS-CV)
- Orientación. Se presentaba a los niños las tres secuencias completas de acciones en sus cuatro imágenes y se proveía la pista verbal; un verbo que marcaba que se trataba de una acción: “¿Qué está haciendo?”. Al finalizar cada secuencia, se verbalizaba el resultado la acción. Por ejemplo, secuencia 1: “¡Viste como abrió!”.
- Prueba. Se presentaban las tres secuencias completas de acciones (romper, cortar, ensuciar) acompañadas de la pista verbal: “¿Qué está haciendo?”, pero no se verbalizaba la acción. Inmediatamente después de mostrar cada secuencia, se invitaba a los niños a elegir, entre tres objetos, aquel que mostraba el resultado de la acción diciendo: “¿Me mostrás como quedó?”.
Sin secuencia y con pista verbal (SS-CV)
- Orientación. Se presentaba solo la última imagen de cada una de las tres secuencias de orientación y se proveía de la pista verbal: “¿Qué está haciendo?”. Al finalizar la presentación, se verbalizaba la acción; por ejemplo, Secuencia 1: “¡Viste como abrió!”.
- Prueba. Se presentaba solo la última imagen de cada una de las tres secuencias de la prueba (romper, cortar, ensuciar) acompañando con la pista verbal: “¿Qué está haciendo?”. Inmediatamente después, se invitaba a los niños a elegir entre tres objetos aquel que mostraba el resultado de la acción diciendo: “¿Me mostrás como quedó?”.
Con secuencia y sin pista verbal (CS-SV)
- Orientación. Se presentaban las tres secuencias de acciones con sus cuatro imágenes. Luego de completar la primera secuencia, se continuaba con la segunda diciendo nuevamente: “Ahora, te voy a mostrar otra”. Del mismo modo, se procedía ante cada nueva secuencia. En ningún caso se verbalizaba el resultado de las acciones.
- Prueba. Se mostraban las secuencias completas. Luego de mostrar la primera secuencia, sin proveer de la pista verbal, se invitaba a seleccionar entre tres opciones (objetos) diciendo: “¿Me mostrás como quedó?”. De la misma forma, se continuaba con las pruebas siguientes.
Estrategia de análisis
La variable dependiente sobre la que se efectuaron los análisis fue el número de subpruebas correctas. Una respuesta fue codificada como correcta si el niño señalaba o tocaba el objeto que mostraba el resultado de la acción. Se tuvo en cuenta la primera elección, pudiendo cada niño tener una puntuación total de 3 subpruebas correctas en la tarea.
Los análisis estadísticos se realizaron sobre los puntajes de las tareas. Los valores se informan en porcentajes para una mayor claridad en la exposición de los resultados obtenidos.
Al igual que en el estudio previo, se analizó el desempeño individual de los niños en base al criterio de sujeto exitoso: tres subpruebas correctas en la fase de prueba.
Debido al tamaño de la muestra y a que no se asume normalidad, se optó por un análisis no-paramétrico, utilizando las pruebas Kruskal-Wallis, U Mann-Whitney y Chi cuadrado.
Resultados y discusión
Los resultados del presente estudio muestran que sobre un total de 45 respuestas, en la condición CS-CV, los niños de 36 meses obtuvieron un total de 39 respuestas correctas (n = 15; 87%) y los de 30 meses, de 32 respuestas correctas (n = 15; 71%).
En la condición SS-CV, a los 36 meses, los niños mostraron un total de 31 respuestas correctas (n = 17; 61%) y los de 30, de 20 respuestas correctas (n = 11; 61%).
Por último, en la condición CS-SV, los niños de 36 meses obtuvieron un total de 21 respuestas correctas (n = 10; 70%); y los de 30 meses, de 17 respuestas correctas (n = 10; 57%) (ver gráfico 4).
Gráfico 4. Porcentaje de respuestas según condición y edad.

Fuente: elaboración propia.
Al comparar el desempeño al interior de cada edad y condición, se observó que los niños de 36 meses que participaron de la condición CS-CV mostraron una mejor ejecución en la tarea (87% de respuestas correctas) que los niños de la condición SS-CV (61%) (U = 58,50; p < .001). Sin embargo, no se encontraron diferencias significativas en el desempeño entre la condición CS-CV (87%) y la condición CS-SV (70%), (U = 50,00; p > .05). Estos resultados indican que la secuencia, a diferencia de la pista verbal, marca la diferencia en el desempeño a esta edad.
Por otro lado, a los 30 meses, si bien los niños tuvieron un mejor desempeño en la condición CS-CV (71%), no se encontraron diferencias al compararlo con su ejecución en la condición SS-CV (61%), (U = 72; p > .05) y con la condición CS-SV (57%), (U = 59,50; p > .05). Tampoco se encontraron diferencias entre la condición SS-CV (61%) y la condición CS-SV (57%), (U = 48,00; p > .05). Esto indicaría que, a los 30 meses, la combinación de ambas pistas es importante para que los niños tengan un buen desempeño en la tarea.
Análisis contra el azar por condición, edad y tipo de acción
Con secuencia y pista verbal
A los 30 meses, la ejecución de los niños fue superior a lo esperable por azar en las tres acciones presentadas: romper (X2 = 7,50; gl = 1; p < .005); cortar (X2 = 4,80; gl = 1; p < .05); ensuciar (X2 = 7,50; gl = 1; p < .005). De igual forma, a los 36 meses, la ejecución de los niños superó las pruebas contra el azar en las tres secuencias de acciones: romper (X2 = 14,70; gl = 1; p < .0001); cortar (X2 = 19,20; gl = 1; p < .0001); ensuciar (X2 = 24,30; gl = 1; p < .0001).
Estos resultados muestran que, a partir de los 30 meses, los niños comprenden que las imágenes provistas por una tablet representan acciones cotidianas dirigidas a un fin que pueden tener lugar en la realidad, siempre y cuando cuenten con información sobre la secuencia y se les provea de la pista verbal.
Sin secuencia y con pista verbal
Tanto a los 30 como a los 36 meses, los niños solo superaron la prueba de azar en la secuencia correspondiente a la acción de ensuciar (30 meses: X2 = 7,68; gl = 1; p < .005; 36 meses: X2 = 20,25; gl = 1; p < .0001), no así en las secuencias romper y cortar (X2 = 0,04; gl = 1; p > .05).
Con secuencia y sin pista verbal
La ejecución de los niños de 30 meses de edad no superó el azar en ninguna de las tres secuencias de acciones.
A los 36 meses, el desempeño de los niños en la acción romper no superó el azar (X2 = 0,20; gl = 1; p > .05). Sin embargo, se desempeñaron muy bien en cortar (X2 = 6,05; gl = 1; p < .01) y en ensuciar (X2 = 6,05; gl = 1; p < .01).
La tabla 3 resume los resultados de la prueba de azar en ambas edades según el tipo de acción observada y la información ofrecida: con y sin secuencia; con y sin pista verbal.
Tabla 3. Resultados de prueba de azar por edad, tipo de acción e información.

Fuente: elaboración propia.
En resumen, los niños de ambas edades mostraron un mejor desempeño en la tarea cuando se les proveyó tanto de la secuencia como de la de pista verbal. Cuando se les retiró la secuencia y se mantuvo la pista verbal, solo pudieron resolver la acción que resultó ser la más sencilla de comprender: ensuciar. Sin embargo, cuando se mantuvo la secuencia pero se retiró la pista verbal, los niños de 30 meses no resolvieron acción alguna, mientras que los de 36 meses resolvieron dos: cortar y ensuciar.
Ejecución individual por edad y condición
La tabla 4 muestra el total de respuestas correctas de los niños por condición y edad. Con respecto a la ejecución de los niños de 30 meses, se encontró que 5 obtuvieron la puntuación máxima (3 subpruebas correctas) en la condición CS-CV (n = 15); 2, en SS-CV (n = 11) y 3, en CS-SCV (n = 10).
En cuanto a los niños de 36 meses, 11 obtuvieron la puntuación máxima en CS-CV (n = 15), mientras que SS-CV, solo 2 (n = 17), y CS-SV, solo 3 (n = 10).
Tabla 4. Número de subpruebas correctas de los niños por condición y edad.

Fuente: elaboración propia.
En su conjunto, los resultados indican que cuando se provee solo la pista verbal o solo la pista visual (la secuencia), los niños muestran un bajo desempeño en la tarea. La provisión conjunta de ambas pistas es lo que potencia un desempeño exitoso en la tarea. Sin embargo, a los 36 meses de edad, al presentarse las pistas en forma separada, la información visual de la secuencia completa mostró ser más relevante que la pista verbal a la hora de comprender simbólicamente imágenes que representan acciones.
Discusión general
El objetivo de los Estudios 3 y 4 consistió en indagar si los niños de 24, 30 y 36 meses de edad comprenden que las secuencias de imágenes digitales provistas por una tablet representan acciones dirigidas hacia un fin que pueden ocurrir en la realidad.
Se encontró que los niños de 30 y 36 meses, a diferencia de los de 24, comprendieron que las secuencias de imágenes se referían a una acción que puede tener lugar en la realidad, ya que escogieron el objeto que mostraba el resultado de la acción. Aunque podría sugerirse que los niños de 24 meses no comprendieron las acciones, esto no es así. Numerosos estudios dan cuenta de la facilidad con la que los niños comprenden acciones a partir de la propia experiencia (Gerson y Woodward, 2014) y la observación (e.g., Slater, Quinn, Brown y Hayes 1999). Por lo que en el presente estudio se deduce que la dificultad de los niños reside puramente en el medio representacional, las imágenes. Una posible explicación de las dificultades a los 24 meses es quizás la forma en que la experimentadora mostraba las secuencias de imágenes. Recordemos que, para mostrar la secuencia (4 imágenes), la experimentadora deslizó su dedo índice en la pantalla, lo que probablemente le dio a los niños la oportunidad de descubrir una característica de la pantalla que antes era desconocida. Estudios recientes han sugerido que las características interactivas de las pantallas pueden obstaculizar o potenciar el uso simbólico de estos medios en niños pequeños, aunque esto depende de la edad de los niños y de las tareas propuestas (Krcmar, 2010; Sheehan y Uttal, 2016; Troseth et al., 2006).
Por otro lado, debido a que en el Estudio 3 a los niños se les proveyó tanto de imágenes en secuencia como de una pista verbal, en el Estudio 4 nos propusimos estudiar qué tipo de pista (verbal o secuencia visual) resultaba clave para la comprensión simbólica de imágenes que representan acciones cotidianas dirigidas hacia un fin en niños de 30 y 36 meses de edad.
Los resultados, en general, muestran que los niños son muy exitosos en la tarea cuando se les provee de la secuencia y la pista verbal. Es decir, cuando se muestran las acciones en secuencias de imágenes acompañadas por un verbo que marca una acción (“¿Qué está haciendo?”).
Asimismo, los análisis del Estudio 4 indican que las pistas tienen un impacto diferencial a distintas edades. Los niños de 36 meses, a diferencia de los de 30, pueden prescindir de la pista verbal, pero no de la secuencia.
Los resultados en su conjunto se alinean con estudios que han sugerido que los niños comprenden acciones cotidianas presentadas en imágenes cuando estas acciones son desarrolladas de manera continua y/o en secuencias coincidentes con los límites de los objetivos e intenciones de un actor (Baldwin, et al., 2001; Baldwin, et al., 2008; Saylor, et al., 2007).
Por otro lado, estos resultados muestran que a los 30 meses, los niños necesitan del andamiaje verbal. Estudios recientes sugieren que la presencia de un adulto que responde de manera contingente a las acciones de los niños puede tener importantes influencias en el aprendizaje de los niños a partir de libros, televisión y computadoras (Strouse y Troseth, 2014). Aunque también cabría suponer que la pista verbal ofrecida quizás no fue suficiente. Estudios relacionados con la comprensión simbólica de imágenes han mostrado que nombrar los objetos representados y la provisión de una narración significativa (descripción de los eventos) ayuda a los bebés y niños pequeños en tareas simbólicas (e.g., Pruden, Hirsh-Pasek, Golinkoff y Hennon, 2006; Seehagen y Herbert, 2010; Simcock y DeLoache, 2006; Simcock, Garrity y Barr, 2011; Waxman, 2008). En futuros estudios, se podría indagar acerca del impacto de diferentes pistas verbales sobre la comprensión simbólica de imágenes que representan acciones.



