





El presente estudio se orientó a verificar empíricamente si variables sociodemográficas (sexo, edad, escolaridad, cargo, antigüedad, estado civil y rubro), organizacionales (cultura organizacional, trabajo flexible) y disposicionales (compromiso organizacional, articulación trabajo-familia, satisfacción laboral) desempeñan el rol de predictores del rendimiento laboral, en una muestra por disponibilidad de trabajadores santafesinos. Para tal fin, se diseñó una investigación empírica, transversal con base en tres etapas diferenciadas. Las dos primeras etapas estuvieron destinadas al desarrollo (trabajo flexible) o validación de instrumentos (rendimiento laboral e interacción trabajo-familia) necesarios para llevar a cabo la recolección de datos. En este libro no se presenta un desarrollo pormenorizado de ellas, ya que pueden ser consultadas en las publicaciones científicas respectivas. La tercera etapa, de neto corte empírico, se orientó al desarrollo y contraste de dos modelos teóricos rivales en línea con los argumentos de la estrategia asociativa-explicativa (Ato et al., 2013). Para ello, se utilizó el recurso de los modelos de ecuaciones estructurales, como técnica de análisis multivariante, para contrastar las relaciones conceptuales planteadas con los datos empíricos reunidos en la etapa de recolección. Los resultados obtenidos permitieron determinar el modelo que mejor se ajustaba a los datos, a la vez que posibilitaron conocer el aporte específico de cada una de las variables a la predicción del rendimiento laboral individual. A continuación, se describen esquemáticamente cada uno de los estudios desarrollados para ser analizados en profundidad en los capítulos subsiguientes.
Desarrollo y verificación de un modelo explicativo de rendimiento laboral
El estudio final que compone el diseño de la presente investigación estuvo enfocado a desarrollar y verificar empíricamente un modelo explicativo multicausal del rendimiento laboral individual. Para tal fin, se desarrollaron dos etapas sucesivas. La primera se orientó a sistematizar y analizar la literatura internacional con miras a postular dos modelos teóricos predictivos sustentados en la evidencia científica. La segunda se enfocó en el contraste empírico de los modelos postulados, de modo de identificar la mejor propuesta explicativa. En este sentido, se realizaron diversos análisis estadísticos que permitieron examinar las relaciones conjeturadas, determinar el modelo que mejor se ajustaba a los datos, así como la contribución relativa de cada variable a la predicción del rendimiento laboral. A continuación, se presentan los modelos elaborados en el marco de la primera etapa de este estudio.
Etapa I: desarrollo de modelos conceptuales
A la hora de probar el potencial de un modelo explicativo se deben tener en cuenta tanto el planteamiento de las relaciones de predicción como las estrategias disponibles para verificarlo (Cupani, 2012). En cuanto a las diferentes propuestas para la verificación de sistemas de ecuaciones estructurales, se han diferenciado: (1) estrategias de modelización confirmatoria, (2) estrategias de modelos rivales y (3) estrategias de desarrollo del modelo. En este caso, se optó por la segunda opción, la que permite evaluar el modelo estimado con modelos alternativos, dado que en muchas ocasiones pueden existir diferentes formas de representar una misma situación sin conocer cuál proporciona un mejor nivel de ajuste. Esta estrategia proporciona lineamientos tanto para realizar esta comparación como para seleccionar el más idóneo. En relación con la especificación de las relaciones de dependencia al interior de los modelos teóricos predictivos, éstas deben sustentarse en una correcta justificación teórica. Un modelo estructural es el modelo guía que permite esbozar las relaciones entre variables independientes y variables dependientes (Cupani, 2012). Por lo tanto, la claridad del modelo se encuentra determinada por el grado de conocimiento teórico que se posea sobre el tema en estudio (Hoyle, 2012).
La presente investigación, además, se encuentra orientada a identificar el efecto de terceras variables en el estudio de las relaciones multicausales. En este sentido, ellas pueden influir sobre una aparente relación causa-efecto y participar en el modelo como moderadoras o mediadoras (Ato & Vallejo, 2011). Los moderadores han sido señalados como variables intervinientes que afectan la dirección y/o la fuerza de la relación (reduciéndola, incrementándola, anulándola o invirtiéndola) entre una variable independiente y una variable dependiente (Baron & Kenny, 1986). Los mediadores, por su parte, han sido definidos (Baron & Kenny, 1986) como constructos intervinientes que dan cuenta de la relación entre la variable independiente y la variable dependiente. Es decir, la función mediadora representa el mecanismo a través del cual la variable independiente es capaz de influir sobre la variable dependiente de interés. A su vez, el alcance del efecto indirecto puede ser parcial o completo. Si la mediación es perfecta (completa), el efecto directo de la variable independiente queda completamente anulado cuando el mediador entra en escena. Mientras que si la mediación es parcial el pasaje causal entre la variable independiente y la variable dependiente continúa siendo significativo, pero se reduce la magnitud del efecto (Preacher, 2015).
Sin embargo, recientemente se ha indicado (Torres Costoso, 2015) que el análisis de mediación simple representa una simplificación del proceso de investigación, dado que la mayoría de los procesos estudiados en el ámbito de la psicología organizacional se encuentran determinados por diversos mecanismos que influyen sobre un resultado de interés. Por lo tanto, un enfoque apropiado debería realizarse mediante un modelo que permita analizar no solo la existencia de un efecto indirecto, sino también conocer el efecto simultáneo de diversos mediadores en un único modelo integrado (Torres Costoso, 2015). Tras estas consideraciones previas se presentan los dos modelos elaborados, se explicitan las hipótesis sobre las cuales se sostienen y se esquematizan gráficamente las relaciones presupuestas. En ambos casos se incluyeron las variables sociodemográficas (sexo, antigüedad, rubro, cargo, edad y estado civil) como posibles predictoras del rendimiento laboral. Sin embargo, no se retuvieron para la representación gráfica de cada modelo a los fines de evitar su contaminación visual.
Modelo de mediación en paralelo
Los modelos de mediación múltiple pueden realizarse en paralelo o en serie. En el primer caso, la variable dependiente se asocia a la independiente de manera directa, pero también de forma indirecta por medio de mediadores. En este sentido, el primer modelo propuesto se edificó sobre el interjuego entre variables independientes y variables mediadores. Más precisamente, se estipularon efectos directos del trabajo flexible (TF), el enriquecimiento trabajo-familia (ETF), el conflicto trabajo-familia (CTF) y las prácticas orientadas a los procesos (POP) sobre el rendimiento laboral (RL). Al tiempo que se conjeturó que tanto la satisfacción laboral (SL) como el compromiso afectivo (CA) podrían actuar como mecanismos mediadores. En la figura 1 se presenta la representación gráfica del modelo propuesto que, a su vez, se sostiene en las siguientes hipótesis:
Hipótesis 1: el TF y el ETF se correlacionarán positivamente entre sí y correlacionarán negativamente con el CTF y las POP.
Hipótesis 2: el TF y el ETF impactarán directa y positivamente sobre el RL.
Hipótesis 3: el CTF y las POP impactarán negativamente sobre el RL.
Hipótesis 4: la SL y el CA mediarán, paralelamente, la relación entre el TF, el ETF, el CTF, las POP y el RL.
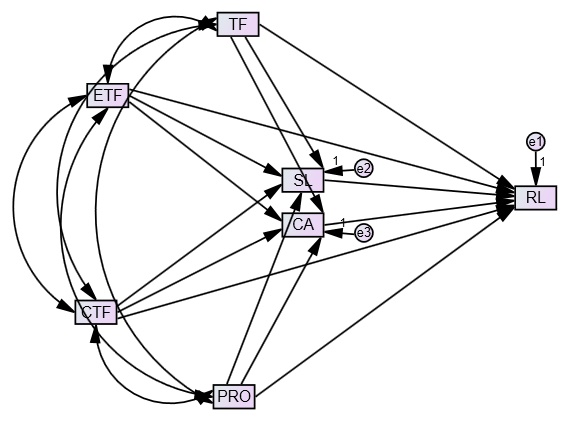
Figura 1. Modelo de mediación en paralelo (elaboración propia).
Modelo de mediación en serie
La mediación en serie, en cambio, estima que los mediadores se encuentran relacionados dentro de una misma cadena causal. Dependiendo de la complejidad del modelo, el número de efectos indirectos puede variar. Sin embargo, dado que la teoría debe ser la que guíe la representación del modelo, en la mayoría de los casos la presencia de más de dos mediadores en serie no resulta una buena elección (Cupani, 2012). El modelo planteado conjuga los efectos directos del ETF, el CTF, el TF, las POP sobre el RL. Así como los efectos indirectos entre éstos a través de dos mediadores, la SL y el CA, dispuestos en serie. El modelo propuesto se sostiene en las siguientes hipótesis (figura 2):
Hipótesis 1: el TF y el ETF se correlacionarán positivamente entre sí y correlacionarán negativamente con el CTF y las POP.
Hipótesis 2: el TF, el ETF impactarán directa y positivamente sobre el RL.
Hipótesis 3: el CTF y las POP impactarán negativamente sobre el RL.
Hipótesis 4: el TF, el ETF, el CTF y las POP tendrán un efecto indirecto sobre el RL a través de la SL y el CA, en serie.
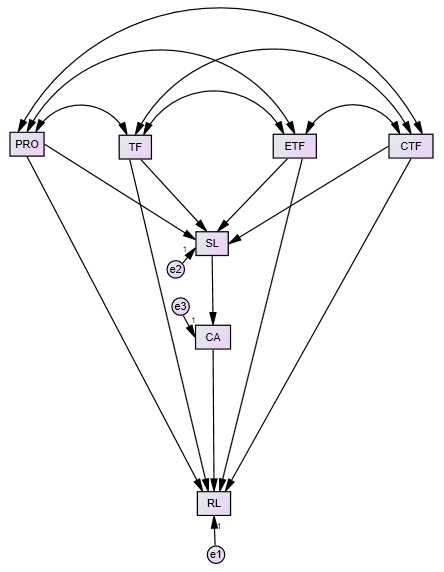
Figura 2. Modelo de mediación en serie (elaboración propia).
Etapa II: verificación empírica de los modelos teóricos propuestos
Para lograr cumplimentar los objetivos planteados en esta etapa, es decir, conocer el modelo explicativo más idóneo entre las dos alternativas planteadas y verificar el aporte específico de cada una de las variables a la predicción del rendimiento laboral individual, se emprendió un proceso de recolección de datos. La muestra final quedó integrada por 383 trabajadores de empresas pertenecientes a diversos rubros de la industria (servicios, comercios, industrias, educación y salud). La batería de escalas para la exploración psicológica de las variables de interés aplicada, la estrategia de análisis utilizada y los diversos resultados obtenidos se describen pormenorizadamente en los apartados que se presentan a continuación. Los análisis estadísticos necesarios para el cumplimiento de los objetivos se efectuaron con el auxilio de softwares especializados.
El proceso de recolección de datos para el presente estudio se dividió en dos grandes etapas. En la primera de ellas, llevada a cabo durante el primer trimestre del año 2016, se tomó contacto con distintas organizaciones de diversos ramos de la industria, radicadas en la ciudad de Rosario y zona de influencia, a efectos de invitarlas a participar de la investigación. En un segundo momento, entre las organizaciones que aceptaron formar parte, se distribuyeron los protocolos a ser completados por los trabajadores. Para cumplimentar con el número de casos esperados (entre 300 y 400) se confeccionaron y entregaron 700 cédulas de recolección de datos, habida cuenta de que la tasa de retorno de este tipo de instrumentos suele ser baja. Del total entregado, 415 fueron recuperados, sin embargo, 28 protocolos debieron ser descartados por encontrarse incompletos o presentar patrones de respuesta que denotaban una clara falta de compromiso (por ejemplo, seleccionar la misma opción de respuesta para todos los reactivos). Sobre las cédulas restantes, 383 casos, se efectuó una exploración preliminar para identificar la presencia de valores perdidos y/u observaciones atípicas que pudieran afectar los resultados del estudio.
Si bien esta inspección demostró que no existían valores perdidos que pudieran disminuir la eficacia de las pruebas estadísticas, se encontraron tres observaciones extremas univariadas una vez que se transformaron los resultados de cada variable en puntajes estandarizados (Tabachnick & Fidell, 2013). En todos los casos, los datos se encontraron a más de 3.5 DE por encima o por debajo de la media de cada variable. Sumado a ello, se identificaron seis casos que podían catalogarse como atípicos multivariados (Hair et al., 2010) desde el momento en que los valores del índice D2 tuvieron una significancia menor a la estipulada (p < .001). De ellos, dos casos satisfacían las condiciones de ser tanto atípicos univariados como multivariados. Por lo que se decidió eliminar un total de seis observaciones dado que el volumen de datos no se vería perjudicado si se quitaran tales observaciones de la matriz de datos. En definitiva, 376 casos fueron considerados válidos para continuar con los análisis posteriores.
Descripción de la muestra en estudio
La verificación empírica se llevó a cabo sobre una muestra no probabilística, seleccionada por disponibilidad, de 376 trabajadores. Ellos representaban industrias de diversos ramos de actividad pertenecientes a la ciudad de Rosario y zona de influencia. La composición definitiva de la muestra en función de las variables sociodemográficas se presenta en la tabla 1.
Tabla 1. Distribución de la muestra (N = 376) en función de variables sociodemográficas
VARIABLE |
CATEGORÍA |
FRECUENCIA |
PORCENTAJE |
| Sexo | Varón | 191 | 50.8% |
| Mujer | 185 | 49.2% | |
| Edad | Entre 18 y 20 años | 51 | 13.6% |
| Entre 21 y 30 años | 142 | 37.8% | |
| Entre 31 y 40 años | 107 | 28.5% | |
| Entre 41 y 50 años | 45 | 12.0% | |
| Más de 51 años | 31 | 8.2% | |
| Antigüedad laboral | Menos de 1 año | 83 | 22.1% |
| Entre 1 y 5 años | 146 | 38.8% | |
| Más de 5 años | 147 | 39.1% | |
| Cargo | Gerencial | 44 | 11.7% |
| No gerencial | 332 | 88.3% | |
| Estado civil | Soltero/a | 231 | 61.4% |
| Casado/a | 103 | 27.4% | |
| Otro | 42 | 11.2% | |
| Escolaridad | Primario | 47 | 12.5% |
| Secundario | 167 | 44.4% | |
| Universitario | 162 | 43.1% | |
| Rubro | Servicio | 97 | 25.8% |
| Industria | 94 | 25.0% | |
| Comercio | 109 | 29.0% | |
| Salud y Educación | 76 | 20.2% |
Como se desprende de la tabla precedente, la distribución de la muestra por género fue bastante homogénea, con una muy leve mayoría de participantes varones (50.8%). El mayor porcentaje de los participantes tenía edades comprendidas entre los 21-30 años (37.8%) de edad y los 31-40 años (28.5%) de edad. Porcentajes menores se ubicaron en los rangos etarios comprendidos entre los 18-20 (13.6%) de edad, y entre los 41-50 años (12.0%) de edad; en tanto que el rango de los mayores de 51 años (8.2%) de edad estuvo escasamente representado. El 27.4% de los sujetos estaba casado, mientras que cerca de un 61% era soltero. La muestra incluyó empleados de organizaciones de diversos ramos de actividad, tales como comercio (29.0%), servicios (25.8%), industria (25.0%) y, con menor representación, salud y educación (20.2%). En relación con la antigüedad laboral, el 39.1% de la muestra llevaba más de cinco años en su trabajo, el 38.8% entre uno y cinco años, y el 22.1% se encontraba trabajando hacía menos de un año.
Tabla 2. Distribución de las variables sociodemográficas por género
VARIABLE |
CATEGORÍA |
VARONES (N = 191) |
MUJERES (N = 185) |
||
F |
% |
F |
% |
||
| Edad | Entre 18 y 20 años | 28 | 14.7% | 23 | 12.4% |
| Entre 21 y 30 años | 77 | 40.3% | 65 | 35.1% | |
| Entre 31 y 40 años | 48 | 25.1% | 59 | 31.9% | |
| Entre 41 y 50 años | 22 | 11.5% | 23 | 12.4% | |
| Más de 51 años | 16 | 8.4% | 15 | 8.1% | |
| Antigüedad laboral | Menos de 1 año | 45 | 23.6% | 38 | 20.5% |
| Entre 1 y 5 años | 78 | 40.8% | 68 | 36.8% | |
| Más de 5 años | 68 | 35.6% | 79 | 42.7% | |
| Cargo | Gerencial | 25 | 13.1% | 19 | 10.3% |
| No gerencial | 166 | 86.9% | 166 | 89.7% | |
| Estado civil | Soltero/a | 110 | 57.6% | 121 | 65.4% |
| Casado/a | 62 | 32.5% | 41 | 22.2% | |
| Otro | 19 | 9.9% | 23 | 12.4% | |
| Escolaridad | Primario | 18 | 9.4% | 29 | 15.7% |
| Secundario | 105 | 55.0% | 62 | 33.5% | |
| Universitario | 68 | 35.6% | 94 | 50.8% | |
| Rubro | Servicio | 49 | 25.7% | 48 | 25.9% |
| Industria | 63 | 33.0% | 31 | 16.8% | |
| Comercio | 57 | 29.8% | 52 | 28.1% | |
| Salud y Educación | 22 | 11.5% | 54 | 29.2% | |
Por otra parte, como se observa en la tabla 2, un mayor número de mujeres tenía un nivel de escolaridad universitario, mientras que la mayoría de los varones había terminado el secundario. La mayor parte de las mujeres trabajaba en salud y educación, mientras que los varones se desempeñaban, principalmente, en la industria y el comercio. En relación con el cargo, tanto varones como mujeres ocupaban mayoritariamente puestos no gerenciales. En lo que hace a la antigüedad laboral, las mujeres tenían un mayor porcentaje de permanencia en su puesto de trabajo. En cuanto al estado civil, varones y mujeres mostraron perfiles similares en las categorías exploradas, mayormente representado por los solteros. Finalmente, las edades también exhibieron similitudes entre los sexos, al momento que se registraron mayores porcentajes entre los 21-30 y los 31-40 años de edad para ambos grupos.
Instrumentos
Para la recolección de los datos necesarios para cumplimentar los objetivos del estudio, se confeccionó una batería de instrumentos con los fines de medir cada una de las variables de interés. En todos los casos, el protocolo de recolección estuvo integrado con escalas previamente validadas y/o adaptadas para su empleo con población de trabajadores argentinos. A continuación, se describen los instrumentos utilizados para tal fin, y en el Anexo se presenta un ejemplar del protocolo final.
Rendimiento laboral. Se utilizó la validación argentina (Gabini & Salessi, 2016) de la Escala de Rendimiento Laboral Individual de Koopmans et al. (2014). El instrumento, integrado por 13 ítems, permite evaluar las tres dimensiones del RL: rendimiento en la tarea (ej.: “cuando pude realicé tareas laborales desafiantes”), rendimiento en el contexto (ej.: “participé activamente de las reuniones laborales”) y comportamientos contraproducentes (ej.: “me quejé de asuntos sin importancia en el trabajo”); así como el RL global. Cada reactivo es valorado en una escala tipo Likert de 5 puntos (variando desde 1 = nunca a 5 = siempre), donde a mayor puntaje mayor RL.
Trabajo flexible. Se evaluó mediante la escala unidimensional desarrollada ad hoc (Gabini, en prensa). Ésta se encuentra integrada por 9 ítems (ej.: “cumplo con mis obligaciones familiares durante el horario laboral”). Cada uno de los reactivos es evaluado según una escala tipo Likert con 5 opciones de respuesta (variando desde 1 = nunca a 5 = siempre). A mayor puntaje, mayor trabajo flexible.
Satisfacción laboral. Se utilizó la Escala Satisfacción Laboral Genérica de Mac Donald y Mac Intyre (1997), adaptada por Salessi y Omar (2016). El instrumento, integrado por 7 ítems (ej.: “en mi trabajo puedo aplicar todas mis capacidades y habilidades”), proporciona una estimación global del grado de satisfacción laboral. Cada reactivo es evaluado según una escala tipo Likert con 5 opciones de respuesta (1 = totalmente en desacuerdo; 5 = totalmente de acuerdo). A mayor puntaje, mayor satisfacción laboral.
Cultura organizacional. Fue analizada mediante la Escala de Prácticas Organizacionales (Omar & Urteaga, 2010), conformada por 25 ítems con formato Likert de 5 puntos, variando de “nada frecuente” a “muy frecuentemente”. Explora los cinco tipos de prácticas que con mayor frecuencia caracterizan a una organización (prácticas orientadas a los procesos vs. a los resultados; orientadas al empleado vs. a la tarea; orientadas a sistemas abiertos vs. a sistemas cerrados; orientadas a sistemas flexibles vs. a sistemas rígidos y orientadas al mercado vs. al interior de la empresa).
Compromiso organizacional. Fue evaluado mediante la adaptación argentina (Omar & Urteaga, 2008) de la Escala de Compromiso Organizacional de Allen y Meyer (1990), que mide las tres dimensiones del compromiso organizacional: afectivo (ej.: “esta empresa tiene mucho significado para mí”), normativo (ej.: “siento que tengo una gran deuda hacia mi empresa”) y calculativo (ej.: “siento que tengo pocas opciones de trabajo como para considerar dejar mi organización”). Ésta se compone de 18 ítems con formato Likert de 5 puntos (variando desde 1 = totalmente en desacuerdo a 5 = totalmente de acuerdo).
Articulación trabajo-familia. Se exploró mediante la adaptación argentina (Gabini, 2017) del Cuestionario de Interacción Trabajo-Familia (SWING) (Geurts et al., 2005), integrada por ocho ítems con formato Likert de 5 puntos (variando desde 1 = nunca a 5 = siempre). Esta escala explora tanto los recursos ganados en las esferas familiares y laborales, denominado enriquecimiento trabajo-familia, a través de cuatro ítems (ej.: “tengo más autoconfianza en el trabajo porque mi vida en casa está bien organizada”); así como el vínculo negativo entre ambos dominios, conflicto trabajo-familia, a partir de cuatro ítems (ej.: “me resulta difícil concentrarme en mi trabajo porque estoy preocupado por asuntos domésticos”).
Variables sociodemográficas. La cédula de recolección de datos incluyó un apartado destinado a recabar información acerca de la edad, el sexo, el estado civil, el nivel de escolaridad, el cargo del empleado (gerencial vs. no gerencial), la antigüedad laboral y el ramo de actividad (servicio, comercio, industria, salud y educación) de los participantes.
Consentimiento informado. El protocolo utilizado, además, incorporó una hoja de consentimiento informado, donde se explicitaban los objetivos del estudio, se garantizaba el anonimato de los participantes y el uso de los datos obtenidos sólo para fines investigativos, en un todo de acuerdo con las normas éticas.
Procedimiento de recolección de datos
La recolección de los datos tuvo lugar durante el primer trimestre del año 2016. La participación de cada organización que aceptó colaborar fue voluntaria, no se brindaron incentivos de ningún tipo a las personas que accedieron a formar parte de la investigación. Algunas organizaciones permitieron que la administración se llevara a cabo en el seno de las mismas instituciones en lugares, días y horarios previamente estipulados. En aquellas organizaciones en las que la recolección no pudo darse al interior de éstas, se acordó hacerles llegar una determinada cantidad de protocolos para que los empleados pudieran responderlos en sus momentos libres, de modo de no generar interrupciones durante la jornada laboral. Las cédulas respondidas fueron retiradas una semana después de la recepción, de acuerdo con lo pautado.
En todos los casos, los empleados fueron alentados a responder de manera individual un cuadernillo integrado por los instrumentos descriptos. Se explicó la mecánica de respuesta, se indagó si existían dudas y se resolvieron las inquietudes sobre el proceso. Las consultas que surgieron durante esa instancia fueron aclaradas en forma personalizada con cada participante. En aquellas ocasiones en las que los protocolos debieron dejarse en las organizaciones, se elaboró un escrito que contemplara tanto instrucciones sobre la modalidad de respuesta como las dudas más frecuentes a la hora de responder el protocolo. Éste quedó a disposición de los empleados, para que pudieran consultarlo ante cualquier inconveniente.
En el desarrollo de esta investigación se siguieron los procedimientos recomendados por la Asociación de Psicología Americana (APA) y los lineamientos dados por el Consejo Nacional de Investigaciones Científicas y Técnicas (CONICET) para el Comportamiento Ético en Ciencias Sociales y Humanidades (Resolución N° 2857/06). Asimismo, se cumplieron las normas establecidas en el Código de Ética de la Federación de Psicólogos de la República Argentina (FePRA) para la realización de investigaciones en psicología. En este sentido, se proveyó a todos los que aceptaron participar de un documento que contenía toda la información necesaria (objetivos y alcances de la investigación, usos de la información recolectada, datos de contacto con los responsables del estudio, etc.), a fin de que pudiesen comprender las consecuencias de su decisión. Dicho documento fue debidamente firmado, dando cuenta del consentimiento formal por parte de los participantes. En todo momento, se resguardó la confidencialidad de los datos obtenidos y la identidad de las personas, respetando su dignidad, libertad, privacidad y autodeterminación.
Estrategia de análisis
La literatura especializada (Byrne, 2006; Hair et al., 2010; Hoyle, 2012; Kline, 2011) ha señalado consistentemente la necesidad de efectuar una serie de análisis preliminares. En este sentido, primero, se evaluó la potencia estadística a posteriori, de modo de establecer si el tamaño muestral alcanzado era adecuado para identificar diferencias significativas. Segundo, se cotejaron los supuestos que subyacen a las técnicas utilizadas para la verificación empírica, como pruebas paramétricas y técnicas de análisis multivariante.
Una vez realizados los análisis preliminares, se procedió al cálculo de medias y desviaciones estándar para las dimensiones constitutivas de cada constructo y para el constructo total, en el caso del rendimiento laboral individual. Para una presentación más armoniosa de tales índices descriptivos, se analizaron en relación con la muestra total y, luego, en relación con cada grupo conformado en función de las variables sociodemográficas (sexo, estado civil, cargo, antigüedad laboral, escolaridad, sector de la industria). Para determinar si las diferencias halladas en función de las características personales eran estadísticamente significativas, se calcularon pruebas de diferencias de medias (t de Student) y análisis de la varianza (ANOVA) con comparaciones múltiples (Tukey). Sumado a ello, se analizó el tamaño del efecto (TE) a través del cómputo de los índices d y f. El primero de ellos corresponde a las pruebas t con muestras independientes, mientras que el segundo concierne a las pruebas ANOVA de un factor (Cárdenas-Castro & Arancibia-Martini, 2014). Por otra parte, se exploraron las asociaciones entre las variables en estudio a partir del cálculo de correlaciones producto-momento (r de Pearson). Estos análisis fueron realizados tanto para la totalidad de la muestra como para cada uno de los grupos constituidos en función de las características personales.
Finalmente, con base en los modelos teóricos desarrollados en el Estudio 3 se evaluó el ajuste de cada uno de ellos y se contrastaron con estructuras rivales formuladas, de modo de seleccionar la propuesta explicativa más idónea. Sobre ésta se efectuaron las pruebas correspondientes a fin de verificar las relaciones propuestas en las hipótesis de trabajo, determinar el TE (mediante el índice f2) y examinar la capacidad explicativa del modelo (a través del índice Q2). El procesamiento y análisis de los datos se realizó mediante el auxilio de recursos informáticos especializados, tales como SPSS versión 23.0, Amos versión 23.0, EQS versión 6.1 (Bentler, 2006) y G*Power (Faul, Erdfelder, Buchner & Lang, 2009).



